Gateway core
EOL
This documentation is archived and will no longer be updated. Instead, refer to the section on Gateway in Geneos.
Introducing Gateway Generation 2 Copied
Gateway2 is the latest version of the Gateway component. This version has been designed with reliability and extensibility as key requirements and is the strategic platform for Geneos going forward.
Gateway System Requirements Copied
| Prerequisite | Description |
|---|---|
| Gateway Machine |
OS: RedHat Linux
(Preferred), Suse Linux, Solaris (X86 and
Sparc)
CPU: Dual CPU, Dual Core
Memory: 2GB (32bit), 8GB
(64bit)
Network: 1 Network Card or
2 bonded Network cards (100 mbps)
Disk: 500 MB* software
only, does not include database table space
Hardware: Virtual or
Physical
|
| SSH Access | SSH access to the Gateway server will also be required for initial installation and configuration of the Geneos software. |
| SCP Access | The Geneos software will be installed in a nominated directory (/opt/geneos) or a user's home directory. This should be a common directory across all machines. We will need SCP access to each server and directory to copy the Gateway binaries. |
| Port 7039 | Default port for communication between the Gateway server and Active Console. |
| SendMail | In order for actions such as email alerts to be demonstrated the Gateway server requires a sendmail daemon running so outgoing messages can be properly routed. |
Running a Gateway Process Copied
Installation considerations Copied
Installation directory Copied
Select a directory to install and extract the files. For new installations the following directory is recommended:
/usr/local/geneos/gateway
Selecting a port number Copied
Each installed gateway must have a unique port on which it listens for client connections. The default gateway port for insecure channel is 7039. For secure channel, the default gateway port is 7038. If these ports are unavailable or you are hosting multiple gateways on a single machine, then you will need to select an available unique port(s) for the gateway. See operatingEnvironment > listenPorts.
Gateway name Copied
Each installed gateway must have a unique name. The name is important as it is used when selecting data and defining rules later on so a unique name is selected that can identify this gateway’s purpose within the organisation. As it is difficult to change the name once monitoring has begun it is recommended to select a suitable name from the outset.
Gateway id Copied
The gateway process uses a unique gateway id internally, which is a 32-bit integer value. This id also allows data generated by this gateway to be identified by connecting processes. If not specified, the id is automatically generated by the gateway, using the gateway name. It is recommended however, that each gateway has an explicitly defined id and name.
Selecting log file and setup directories Copied
The gateway will generate a log file and require at least one master setup file per running instance. As it is common to have multiple gateway instances running on a single host it is useful to organise these files. Your organisation may have specific guidelines as to where configuration and log files must reside which Geneos can accommodate.
See Gateway log file for more info.
Gateway resources Copied
The gateway is shipped with a set of xslt resource files and a timezone file. The resources directory, or a symbolic link to it, must exist in the working directory of the gateway at startup time as these files are part of the runtime source code. The files should not be edited by users and doing so may result in unexpected behaviour. When a gateway binary is upgraded, the resource files must also be upgraded to the version supplied with that gateway.
Installing a new Gateway Copied
This section will describe how to install a Gateway up to the point where the setup can be edited by a connected Gateway Setup Editor.
Extracting files Copied
The Gateway package is simple to install. The package is supplied as a tar file with a name in the format:
gateway2.<platform>.GA<version number>.tar
Extract this to your installation directory. The package will contain the following files and directories:
gateway2.<platform>lib
templates/gateway.setup.xml.tmpl
templates/start_gateway2.tmpl
templates/gateway.setup.withdefaults.xml.tmpl
resources
resources/databases
resources/diagnostics
resources/hooks
resources/nanomsg_stats
resources/standardisedformats
resources/xslt
resources/timezone
LICENCE
NOTICES
LICENCE_README.txt
compat
The file gateway2.
setenv LD_LIBRARY_PATH <SetupDirectory>/compat
Editing start_gateway2 and gateway.setup.xml files Copied
Create the appropriate directory and copy gateway.setup.xml.tmpl to:
<SetupDirectory>/gateway.setup.xml
Copy the start_gateway2.tmpl to start_gateway2 and edit as follows:
### Run the gateway in the foreground
#./gateway2.linux
### Run the gateway in the background with logging
setenv LOG_FILENAME <LogDirectory>/gateway.log
./gateway2.linux -setup <SetupDirectory>/gateway.setup.xml -port <Port> &
Please note the following:
- The gateway process is configured to run in the background
- The log file is set via an environment variable (alternatively this could be set via command line or in the setup file).
- The setup file is set via command line option
- The listen port is set via command line option (alternatively this could be set in the setup file).
Running the start_gateway2 script will now start the Gateway process. You must now connect an ActiveConsole to the Gateway and use the Gateway Setup Editor to set the gateway name and id in the operating environment section.
You can now start adding monitoring configuration via the Gateway setup editor.
Upgrading to a new Gateway Generation 2 version Copied
To upgrade to a later gateway2 binary from an existing installation:
- Stop the current Gateway process.
- Copy the new binary and resources files into the installation directory.
- Restart the Gateway process
Gateway licensing Copied
In order for the gateway to function, an appropriate licensing method must be in place. Please see section 3.6 for more information.
Gateway Command Line options Copied
The following command line options are available in the gateway process:
| Option | Use | ||||||
|---|---|---|---|---|---|---|---|
-help [topic]
|
Displays help about the topic if specified, or this help message. Topic can be any of the parameters shown below. |
||||||
-v, -version
|
Used to display version information for the Gateway. It contains information about the exact version of the Gateway and all the libraries contained within. |
||||||
-validate
|
Used to validate setup files without
using ActiveConsole. By default it validates the
default Gateway setup file
Returns:
|
||||||
-validate-json-output <filename>
|
This option (which implicitly selects the
|
||||||
-setup <filename>
|
Used to specify the setup file Gateway should use. The option must be followed by the filename, which should not start with a - (dash) character. If |
||||||
-setup-comments <none|optional|required>
|
Controls if the Gateway Setup Editor (GSE) asks for comments when you change the setup file. There are three options:
Default if not specified: |
||||||
-max-severity <none|warn|error>
|
Used to specify the maximum allowable setup severity. The maximum severity controls whether the Gateway allows a setup to be applied. For example, if the maximum severity is set to warn, and the setup file contains problems with a severity of warning or less, then the setup is applied, otherwise it is rejected. Possible severity settings are:
Default if not specified: |
||||||
-port <number>
|
Used to specify the port the Gateway listens on for other components. The option must be followed by the listen port, a positive integer in the range 1-65535 inclusive. Note: On some systems ports in the range 1-1024 are reserved, and Gateway will need special permissions to listen on a port in this range. If
If only the secure listen port is configured in the
Gateway setup file, then If only insecure listen port is
configured in the Gateway setup file, then If both secure and
insecure listen ports are configured in the Gateway
setup file, then |
||||||
-log <logfile> | -nolog
|
Used to specify the name of the Gateway log file. The Running the Gateway with the The Gateway sends its output to stdout if this option is not set. |
||||||
-roll-time <HH:MM>
|
Sets a predetermined file rollover time for the Gateway log file. When set, the log file roll over occurs when the first log message comes in after the requested rollover time. The format must be |
||||||
-dump-xml
|
Print the contents of the merged
xml tree (Gateway setup) to the log file or stdout,
then exit. Can be used with The merged nodes have an additional attribute to
specify which setup file this node came from. A node
coming from main file has the attribute This mode is intended for testing/debugging purposes. |
||||||
-autolock
|
Forces a GSE connected to the Gateway to lock setup files (or include files) if a user wants to update them. Other connected GSEs are notified when a lock on a file becomes available and will have a chance to lock it. If GSE's are connected to different gateways that share an include file, they are only be prevented from updating the include file at the same time. For more information, see Autolock. |
||||||
-resources-dir <resource-dir>
|
Specifies the location of the resource directory. This directory is provided as part of the Gateway package. By default it is the directory resources in the current working directory of the Gateway. If running multiple Gateways in multiple working directories from the same package, this is option can be used to provide access to the shared resource. |
||||||
-hooks-dir <resource-dir>
|
Specifies the location of the hooks directory. This directory contains the user defined hooks that are run at setup validation and after a setup change is applied by the Gateway. See Gateway Hooks. |
||||||
-hooks-timeout
|
Changes the hooks timeout from the default of 2 minutes to the value specified. Values greater than the default result in a warning that Gateway performance may be degraded. See Gateway Hooks. | ||||||
-licence
|
Specifies the location of the temporary licence file that the Gateway uses in absence of a Licence Daemon. |
||||||
-licd-host
|
Specifies the host name or IP address of the Licence Daemon the Gateway uses when requesting licences. Default: |
||||||
-licd-port
|
Specifies the port that the Licence Daemon is listens on. The default is 7041. |
||||||
-licd-secure
|
Specifies that the Gateway connects to the Licence Daemon using TLS. If this is not used then an insecure protocol is used to transfer licences from the Licence Daemon to the Gateway. The Gateway and Licence Daemon must be identically configured. |
||||||
-stats
|
Enables gateway load monitoring statistics collection from start-up. This flag can be useful in diagnosing gateway performance issues only seen on start-up, rather than those occurring during normal gateway operation. |
||||||
-process-dump-files
|
Starts a process to read all the database dump files that have been created by the Gateway and inserts them into the database. See Database dump files section. |
||||||
-display-timezone-defaults
|
Prints the default timezone for timezone abbreviations by reading the timezone resources file. The defaults are mentioned in this section and marked with asterisk(*). |
||||||
-skip-cache
|
Loads setup from files on disk instead of cache even if some setups are inactive (outside their active time). The cache contains setup files that the Gateway was running before shutdown. |
||||||
|
|
These options relate to storing passwords in the Gateway setup. They are explained in the section Using Secure Passwords on the Gateway. |
||||||
-ssl-certificate
|
Specifies the file that contains the signed SSL server certificate in PEM (Privacy-enhanced Electronic Mail) format. |
||||||
-ssl-certificate-key
|
Specifies the file that contains the
signed SSL server private key in PEM (Privacy-enhanced
Electronic Mail) format. If this is option is not
specified, but |
||||||
-ssl-certificate-chain
|
Specifies the file that contains the trusted certificate authority. |
||||||
-minTLSversion
|
Specifies the minimum TLS version. The accepted values are:
For more details, see Secure Communications. |
||||||
-openssl-cipher <ciphers>
|
To set the available TLS ciphers use the `-openssl-cipher For more information, see TLS ciphers in Secure Communications. |
||||||
-kerberos-principal <principal>
|
A unique identity that Kerberos can assign tickets to. Examples: |
||||||
-kerberos-keytab <path>
|
Path to the keytab file. The principal must also be specified. |
Gateway Feature Description Copied
The following is a brief introduction to each of the major features of the Gateway. Full details of each feature and all configuration options will be detailed in the following chapters.
Gateway Setup File Copied
The Gateway setup file is the main configuration repository for a configured Geneos system. It contains configuration sections for the Gateway Directory, Rules, Database Logging, Authentication etc.
The setup format is xml and a full xml schema is supplied with the Gateway to define the format. The format allows for multiple files to be merged together. This enables portions of the setup file to be stored externally and reused by multiple Gateways, which eases system administration and maintenance within an organisation. The full details of this are found in the Gateway Setup Files section.
Gateway Operating Environment Copied
The Gateway Operating Environment is a configuration section in which settings that will affect the whole Gateway are set.
Directory Configuration Copied
The monitoring configuration of the gateway is known as the directory configuration. This configuration describes all the Netprobes which the gateway will connect to, and the Managed Entities and Samplers these probes will host.
Authentication Copied
When using the template setup file, users are allowed full access to all gateway features for ease of configuration. User access to various functions within the gateway can be restricted by the use of user definitions and permissions. In addition user administration and permissioning can be simplified by the creation of user groups. Various methods of user authentication are provided by the Gateway. Full details of the configuration options for this are found in the Authentication section.
Auditing Copied
The auditing feature of gateway allows logging of user interactions with the gateway. These logs allow historical tracking of gateway functions and can be used to reconstruct a sequence of events or for security planning. Full details of the configuration options for this are found in the Auditing section.
Ticker event logging Copied
Ticker events are produced by gateway when infrequent but important events occur. For example, Netprobe or Database disconnection events will create an event, which is then viewable in the ActiveConsole 2 event ticker. These events can be logged by configuring the ticker event logging feature of Gateway 2.
Rules Copied
Rules allow run-time information to be updated and actions to be fired in response to specific gateway events. Typically the updates will apply to the severity of cells, reflected in the ActiveConsole by red, amber and green cell backgrounds. Full details of the configuration options for this are found in the Rules section.
Actions Copied
An action is a user-defined processing action which is fired in response to events. Rules are used to trigger actions in response to monitored events. Actions can be configured to trigger an internal process in gateway, or an external system such as sending an email or raising a support ticket.
Effects Copied
An effect is a user-defined processing effect, similar to a cut-down action. Effects can be called by Actions or by Alerts.
Active Times Copied
Active Times provide time-based control of Gateway features, allowing configured functions to be enabled and disabled based on user-defined time periods. Once an active time has been specified in the Gateway setup, it is then referred to by name in the configuration of other gateway features such as Rules, Actions and Database Logging. Active times are very useful for restricting Geneos functionality to periods of time that are important for example: only send alerts during “Trading Hours”. Full details of the configuration options for this are found in the Active Times.
Commands Copied
Gateway commands are the primary method of interaction between gateway and connected users. Commands are invoked by users through a controlling process (such as ActiveConsole 2) which prompts gateway to perform a given operation.
There are a number of pre-defined commands that are provided out of the box. In addition Geneos administrators can define their own commands to provide a very rich functionality set. Multiple commands can be chained together to create tasks, which enable administrators to define and automate more complicated procedures. Execution of commands can be restricted by the user permissioning system. Full details of the configuration options for this are found in the Commands section.
Scheduled Commands Copied
Gateway allows the scheduling of any command in the system, including both internally-defined commands and user-defined commands. These commands can be scheduled to run automatically at recurring intervals, or one-off events at a specified time without further user input.
Scheduled commands are configured to run against a list of targets. This allows, for example, a command to be configured to run against every Netprobe in the system or some subset of those Netprobes.
Database Logging Copied
Gateway supports logging of data values or events to a database. These records allow users to perform historical search or analysis of monitored data, which can then be used to improve system reliability, performance and capacity management.
Gateway currently supports four databases for logging values to:
- MySQL, a free medium-sized fast SQL database available from http://www.mysql.com
- Sybase Adaptive Server Enterprise (ASE), versions 12.5 and above
- Oracle 10g
- MS SQL Server, version 2008 and above, please refer to MS SQL Server Database Setup using native client library
Full details of the configuration options for this are found in the Database Logging section.
Hot Standby Copied
As gateway is responsible for consolidating all monitoring data for distribution to ActiveConsole 2 and other visualisation components, this introduces a single point of failure. To alleviate the problem two gateways can be run as a hot-standby pair, so that if one gateway fails the other gateway will remain in operation until the fault is rectified. This feature is discussed in more depth in the Hot Standby configuration section below.
Environments Copied
In many places in the setup file it is possible to enter data directly, or to use a variable. The use of variables allows values to be substituted at key points. This promotes setup reuse by allowing widely used generic setup sections to be defined which can then be used by providing the specific parameter values. This can greatly ease setup administration for Geneos installations. For more information see the configuration section for Environments and User Variables.
Compute Engine Copied
Compute engine allows computations to be performed on the monitored data from the Geneos system, and the results placed into new metrics on which rules can be set. These computations can be used to compare several values, summarise items across several systems, or perform statistical functions upon a set of historical values.
Persistence Copied
The persistence feature of gateway is used in conjunction with compute engine and historical data. It allows historical values of monitored items to be persisted locally on the gateway machine (instead of or in addition to database logging) on disk. This ensures that if the gateway is restarted for some reason, then values for historical calculations are immediately available to perform computations.
Knowledge Base Copied
The knowledge base feature allows gateway to publish URL links to an organisation knowledge base or document repository, so that the links are available to ActiveConsole 2 users when viewing particular parts of monitoring data. These can be used - for example - to inform users of who to contact if a particular system goes down, or common problems experienced by a process and how to resolve them.
Alerting Copied
The Alerting feature of gateway allows users to be alerted of an item’s severity based on the properties of the item, separating the configuration of alerts and alert recipients from the configuration of rules. This can be used - for example - to send alert emails to different recipients based on the location of the server where the error occurred.
Gateway Sharing Copied
The Gateway Sharing feature of gateway allows users to share data between gateways. This allows one gateway to run rules and thus fire actions and alerts based on the combination of a subset of data from a set of gateways.
Annotations Copied
The Annotations feature works with Alerting and Actions and allows users to target name / value pairs that are available to Actions and Alerts specific to the data items on which they were triggered.
For example if a user has some rules that trigger emails annotations can be configured that are available only on specific cells or have different values depending on the target of the rule.
Similarly if a executable action is configured environment variables are created that are conditional on the target.
Gateway Log File Copied
Log to a file Copied
The -log command line option allows users to specify a file for the Gateway to write all of its log messages to, allowing quick access the past Gateway behaviour. These log messages include descriptions of what the Gateway is doing, such as sending setups to Netprobes, getting information about connecting to them, syncing with a hot standby pair etc., as well as errors that may have occurred, such as being unable to connect to license daemons or unable to start due to fatal setup errors.
Each log message is written on a separate line, and starts with the date and time that it was generated.
Date and time specifiers in log file name Copied
The log filename accepts date and time specifiers in its file name. These specifiers then get populated with relevant date/time information during the logging process. By default this will be evaluated against the gateway start time, but will be evaluated against the roll time if this is used.
For example, if we start up a Gateway on the 3rd of Jan 2013 at 09:30, with a command containing ‘-log GatewayLogExample-%Y-%m-%d-%H-%M.log’ the log file generated would be GatewayLogExample-2013-01-03-09-30.log.
The full list of Time Specifiers is available, showing what can be used.
Note
It is possible that using these specifiers will allow a number of log files to build up on disk. The section on archiving provides more details about this.
Roll over due to max file size Copied
To stop log files from getting excessively large, Gateway log files will roll over when they reach a certain size limit. Upon hitting this size limit, the log file which was being written to will be archived.
By default the log file rolls over when the log file reaches 10485760 bytes (or 10 MB).
It can, however, be configured to rollover after a maximum of 2,147,483,647 (2GB) with a 32-bit Gateway. This can be done through the use of the environment variable MAX_LOG_FILE_SIZE_MB being set to an appropriate amount (in MB). This can also be set in the Gateway setup file under operating environment.
Roll over at a specified time of day Copied
The Gateway log file can be set to roll over at a specified time of day via the -roll-time command line option. When this is set the Gateway log file will automatically roll over after the specified time of day, at the point when a new log message comes in.
For example, if the rollover time is set to 18:00 and at 18:02 the next log message comes in, the current log file will be closed and a new log file will be generated at 18:02. This log message will then be written into the new file.
You may only set one role time.
Note
When time based rolling is active, any time specifiers used in the filename will be evaluated against the roll time rather than the gateway start time, meaning a new log file will not be generated each time the gateway is simply stopped and started. This means that if a gateway is started at 09:00 on 02-Mar-2012 and the roll time is 10:00 then the date and time used to generate the log file name is 10:00 01-Mar-2012.
When rolling, if the new file name generated by the Gateway already exists, the existing file will be archived.
Archive log files Copied
When the log file reaches its maximum size, or a roll time
has been reached, a new log file is opened. When the Gateway starts a new log file, any existing file with the same name will be renamed
to <filename>.old.
To prevent a large number of
log files being retained, only the latest
.old file will be kept. If <filename>.old
already exists it will be overwritten. Consequently, using a simple filename results in there only ever being two log files: the current log, and the old log.
Using time specifiers in the filename usually results in a new filename that does not already exist, particularly if the full date is used. However, this may cause the number of files on disk to continue to increase.
Not including the whole date increases the
number of possibilities, such as just
including the day or day of the month,
which creates a weekly or monthly rotation of
files. .old files may still be generated during a day
if the maximum size is reached, therefore it may be advisable to increase the maximum size if the files
on disk will be limited by a rotation system.
A UNIX script can be called to move log files. The archive script can be used to:
- Move or copy
.oldfiles into an archive elsewhere. - Prevent a large number of date/time based files building up by removing the older ones if the full date is specified.
The UNIX script can be specified using:
- operatingEnvironment > logArchiveScript
- LOG_ARCHIVE_SCRIPT environment variable.
Note
Using operatingEnvironment > logArchiveScript overrides LOG_ARCHIVE_SCRIPT (if set).
The script is run when the gateway switches to using a new log file. The name of the old log file is passed to the script, which is either:
<filename>.old, if the log file name did not change.- The old log
<filename>, if the log file name did change.
If the log file name is changed to a file that already
exists, the existing file is moved
to <filename>.old. That file is not passed
to the archive script.
Licensing Copied
Overview Copied
Many features in the gateway, including running the gateway itself, require a licence to function. These are acquired from the Geneos Licence Daemon to which the gateway connects.
In order to run any functionality the gateway must initially request a ‘gateway’ licence. If this request is successful, the gateway starts up and requests licences for other configured components (for example Database Logging). If the initial ‘gateway’ licence is denied, the gateway stays idle.
A licence will be requested for plug-ins on configured probes.
The connection to the Licence Daemon is dynamic. This means components on the gateway (including the gateway itself) can move from licenced to unlicenced if the licence itself is changed on the daemon, making certain features available or unavailable. The gateway will retain only the minimum licences required for the current configuration.
By default, the gateway will attempt to connect to a daemon running on localhost:7041. The hostname and port to connect to can be specified using the -licd-host and -licd-port command line options when starting the gateway. If the Licence Daemon has been configured to run securely, then the gateway needs to be passed the -licd-secure flag in order to connect correctly, if it has not then the -licd-secure flag should not be passed to the gateway.
The gateway can be configured to request licences from a particular group on the daemon using the Licensing Group setting in Operating Environment.
Viewing information about licensing Copied
There are two methods for viewing the licence on the daemon and how it is being used.
- Web Page Report
- Available using the Licensing Information command on the right click menu from the Gateway icon
- Licence Usage gateway plugin
The GatewayData gateway plugin also provides high level licensing information such as expiry date and current connection status to the daemon.
Licence Usage plugin Copied
The LicenceUsage gateway plugin displays reports about the licence on the daemon and how it is currently in use.
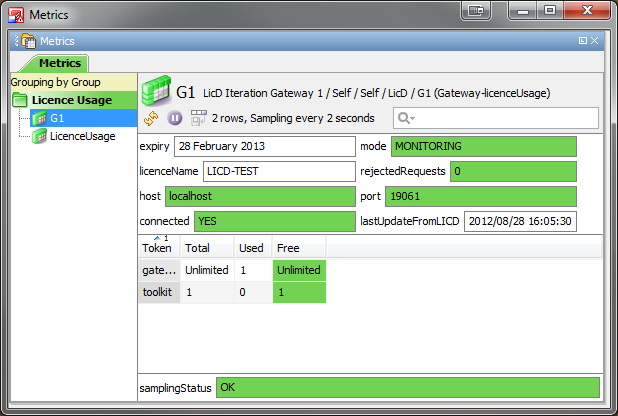
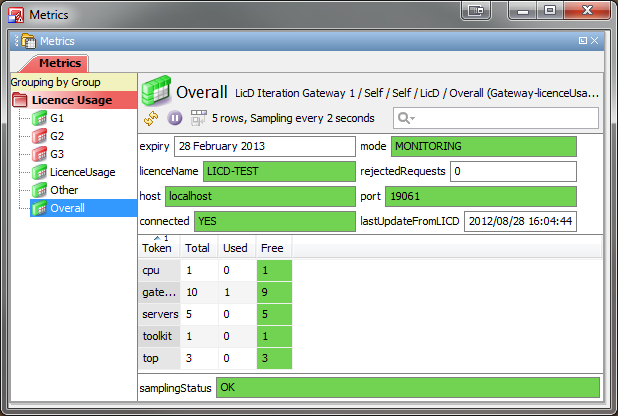
By default, views will be shown showing the licences available and currently in use for all licensing groups configured on the gateway. In addition, an overall LicenceUsage view shows connection and licence expiry information.
The plugin can also be configured to request views for specific groups as well as the overall usage of the entire licence.
It is strongly suggested that a gateway is used to monitor licence usage as one would monitor any other application. For a set of useful rules please consult the Licence Daemon.
Unavailable Licence Daemon Copied
In the event of the daemon becoming unavailable at runtime, the gateway will continue to operate. Connected probes and even the gateway itself can restart but the following operations are not possible:
Changing the gateway name
If this occurs, the entire gateway will cease to function until it can reconnect to the daemon.
Adding a new probe
New probes will not be licenced even if they are on the same server as an existing probe.
Adding a new sampler on a probe
If a new sampler is added on a probe with a plugin that is already in use on that probe, it will not be licenced. However, if the gateway or probe is restarted in the absence of the daemon, it is undefined which of the two samplers will be licenced.
Changing the host or port of a probe
Adding a new licensable gateway component that has not been used already in the setup
Adding a new Breach Predictor plugin
Currently all other gateway plugins do not require a licence.
If the gateway is not connected to the daemon and the expiry date of the licence is reached, all licences held by the gateway will still expire.
Licensable Gateway Features Copied
A gateway token is required to start the gateway. A server token is required for each machine on which the gateway is running a netprobe.
The following gateway features require a licence:
| Gateway Component | Licence Required |
|---|---|
| Database Logging | db-logging |
| PAO Login | single-signon |
| Alerting | alerting |
| Self-Announcing Probes | self-announcing-probes |
| Floating Probes | floating-probes |
A token will be requested for each plug-in running on any configured netprobes. Some plug-ins are licensed by server, meaning one token allows a netprobe to run as many instances of that plug-in as required. Others are licensed by sampler, meaning each token corresponds one to one with a plug-in instance. For more information, contact ITRS.
Failed licence requests are logged in the gateway log.
For more details on licensing and running and configuring the licence daemon, please consult the Licence Daemon.
To obtain a licence, please contact ITRS.
Gateway Setup Files Copied
File location Copied
The gateway reads its configuration from the gateway
setup file at start-up, and also in response to a
“reload setup” command. By default, the gateway looks
in its current working directory for a file named
gateway.setup.xml which is then
loaded.
Gateway can also be configured to look for a
different setup file, using the -setup flag. This flag is followed
by the setup filename, for example:
gateway2 -setup /home/Geneos/setups/config1.xml
File format Copied
The gateway setup file is formatted as an XML document, as described by the XML 1.0 specification . This format is both strict and extensible, and was chosen to allow for validation of the configuration.
In particular, the contents of a valid XML document
can be described by a set of rules called the
schema. This schema is distributed
with both Gateway 2 and ActiveConsole 2 and can be used
by any schema‑aware XML editor to ensure that the setup
file is well-formed XML, and that the contents are
valid.
A minimal gateway setup file template (gateway.setup.xml.tmpl) is supplied
with the gateway, as well as an example with reasonable
initial default settings (gateway.setup.withdefaults.xml.tmpl).
Both these files require the addition of a name for the
gateway to make them valid; either can be used as a
starting point for a full configuration.
If you are editing the setup file without using the Gateway Setup Editor, you can request the gateway to validate a setup file, which will cause gateway to run, print out all the configuration problems it finds and then exit.
gateway2 -setup mySetup.xml -validate
The results of the validation can be generated in JSON format:
gateway2 -setup mySetup.xml -validate-json-output mySetup-validation.json
File contents Copied
The setup file contains many XML elements, which are
contained within the top-level gateway element. Each element
within the gateway element typically controls a feature
of gateway, many of which may work in tandem with each
other. These elements are termed top-level sections,
and are summarised below.
<?xml version="1.0" encoding="iso-8859-1"?>
<gateway compatibility="1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://schema.itrsgroup.com/GA4.0.0-170109/gateway.xsd">
<includes/>
<probes/>
<managedEntities/>
<types/>
<samplers/>
<samplerIncludes/>
<actions/>
<effects/>
<commands/>
<scheduledCommands/>
<rules/>
<alerting/>
<activeTimes/>
<dataSets/>
<hotStandby/>
<databaseLogging/>
<tickerEventLogger/>
<authentication/>
<environments/>
<auditOutputs/>
<knowledgeBase/>
<persistence/>
<staticVars/>
<restrictedSections/>
<selfAnnouncingProbes/>
<exportedData/>
<importedData/>
<publishing/>
<operatingEnvironment/>
</gateway>
Each section of the setup is decribed in detail in the rest of this document. In brief, the purpose of each of the elements shown above is as follows:
gateway
The gateway section is the root node of the XML document. All the XML for the gateway configuration is placed within this node. The attributes on the gateway node shown in the example above include the path to the XML schema, which is used by schema-aware editors. Note that the Gateway will refuse to load the setup if either the compatibility attribute or the format of the version number is incorrect.
includes
The includes section contains a list of included setup files, which the gateway will combine to form the configuration it will use. For more information, see File merging.
probes
The probes section contains the Netprobe processes gateway will connect to for monitoring. For more information, see Probe Configuration.
managedEntities
The managedEntities section contains the Managed Entities which will be run on Netprobes. For more information, see Managed Entities Configuration.
types
The types section contains details of samplers to load for Managed Entities of a particular type. For more information, see Types.
samplers
The samplers section contains details on which samplers will run and what they will monitor. For more information, see Samplers Configuration.
samplerIncludes
The sampler includes section allows common subsets of sampler settings to be defined as templates. For more information, see Sampler Includes.
actions
The actions section describes user-provided scripts and executables which will be launched in response to configured events with the gateway. For more information, see Actions.
effects
The effects section describes defined routines that can be performed by the gateway. Effects are called by Actions and Alerts but are always run in the context of the specific data-item which caused the event. For more information, see Effects.
commands
The commands section allows users to configure commands which can be run on demand from ActiveConsole or the REST API. For more information, see Commands.
scheduledCommands
The scheduledCommands section allows the scheduling of commands defined in the command section, which will then be run automatically by Gateway. For more information, see Scheduled Commands.
rules
The rules section contains user-defined rules in a script-like language. Rules allow users to flag certain conditions of the data being monitored as requiring attention, and are the primary mechanism for triggering other events such as actions. For more information, see Rules.
alerting
The alerting section contains a hierarchy of effects that can be triggered by severity changes. For more information, see Alerting.
activeTimes
The activeTimes section contains user-defined time periods. These time periods can be referenced by other parts of the configuration, and used to provide time-based control of gateway functions. For more information, see ActiveTimes.
dataSets
The dataSets section allows configuration of time series used by Breach Predictor. For more information, see the Breach Predictor and Adaptive Rules documentation.
hotStandby
The hotStandby section allows configuration of the Hot Standby gateway functionality, which ensures monitoring is not interrupted as a result of a failure on the gateway host. For more information, see Hot Standby.
databaseLogging
The databaseLogging section describes monitored data to be logged to a database. For more information, see Database Logging.
tickerEventLogger
The tickerEventLogger section allows configuration of persistence for gateway ticker events. For more information, see Ticker Event Logger.
authentication
The authentication section controls which users can login to the gateway, and what actions they can perform once connected. For more information, see Authentication.
environments
The environments section contains environment variables used in sampler configurations. For more information, see Environments and User Variables.
auditOutputs
The auditOutputs section allows configuration of the auditing functionality of gateway. For more information, see Auditing.
knowledgeBase
The knowledgeBase section is used to configure data-items with links to web-pages containing knowledge articles (possibly hosted by an external content management system). These articles can then provide a more in-depth description of what is being monitored. For more information, see Knowledge Base.
persistence
The persistence section contains configuration for storing persistence data, which is used by the historical analysis functions in rules. For more information, see Persistence.
staticVars
The staticVars section stores complex data to be used across multiple samplers e.g. FKM tables and process descriptors. For more information, see Static Vars.
restrictedSections
The restrictedSections section allows the user to define which other sections can be used in this setup file. It allows an include file to be limited to prescribed functions. For more information, see Restricted Sections.
selfAnnouncingProbes
The selfAnnouncingProbes section is used to configure the self-announcing probes feature. For more information, see Self-Announcing Probes.
exportedData
The exportedData section lists sets of data that the gateway makes available to export to another gateway. For more information, see Gateway Sharing.
importedData
The importedData section is used to configure the sets of data that the gateway will import from another gateway. For more information, see Gateway Sharing.
publishing
The publishing section allows configuration of the publishing of data from Geneos to other systems. For more information, see Publishing data to external systems.
operatingEnvironment
The operatingEnvironment section contains configuration of gateway-wide settings. For more information, see Gateway Operating Environment.
File merging Copied
Introduction Copied
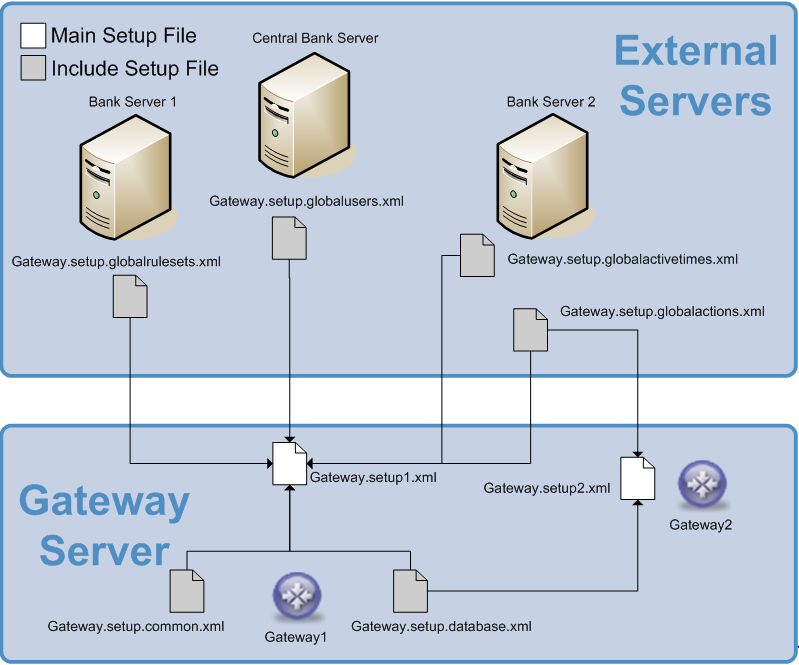
The gateway setup file provides a mechanism for separating out parts of the gateway configuration using include sections. This is useful for sharing common configuration details between different gateways e.g. a local gateway setup (“Main Setup File”) may include a global set of users, rules, activetimes etc. (“Include Setup File”). An example of how this could be organised is shown below.
Configuration Copied
Merged files are configured within the Includes top-level section of the gateway setup. Configuration consists of a priority for the gateway setup file and a list of include definitions that specify what files to include, if they are required and what priority they should have.
Priorities Copied
A priority is used to resolve any conflicts that can occur when merging a set of setup files e.g. if 2 setup files contain the same setup section the gateway will choose the section that belongs to the setup file with the highest priority. Each setup file must have a priority and that priority must be unique so the gateway can always resolve merging conflicts. The highest priority is specified as 1 with all numbers after e.g. 2, 3, 4 etc. have an increasingly lower priority.
Nested Includes Copied
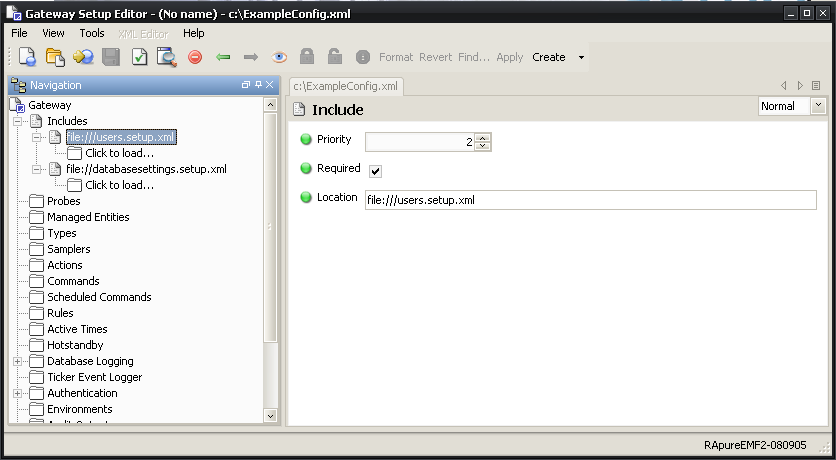
Nested includes are not supported. A setup validation error is produced if the gateway setup includes setup files that have their own include sections.
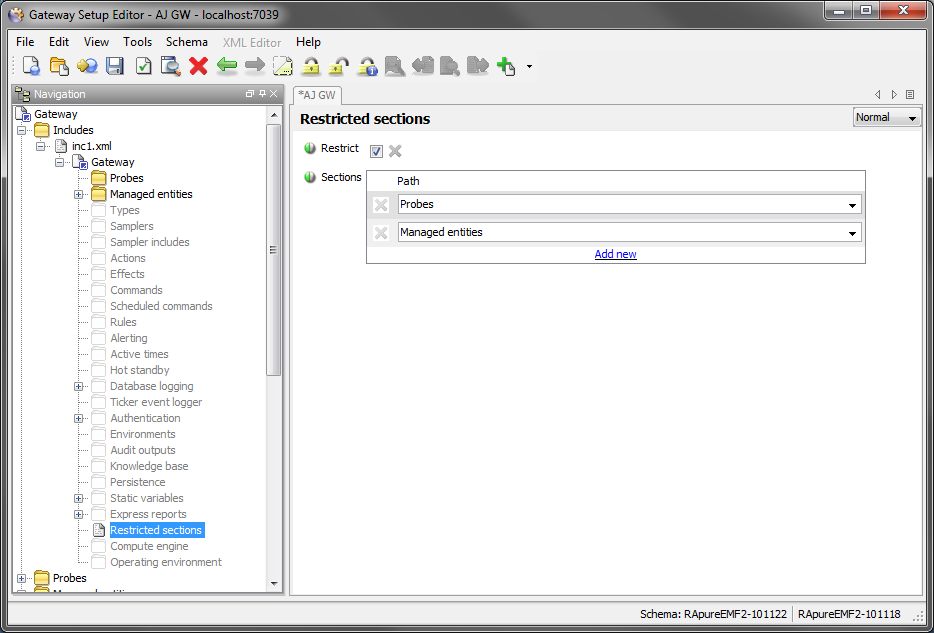
Restricted Sections Copied
Gateway setup files (main and includes files) can be configured to contain (show) only specific sections. Each file contains a “Restricted sections” section which contains the list of sections that are allowed/not allowed in that file depending upon whether the Restrict flag is selected or not. If the “Restricted sections” section does not exist all sections are allowed.
Using the “Restricted” setting restricted sections can be specified in two ways:
- To restrict all sections but allow the selected ones
- To allow all sections but to not allow the selected ones
When a top-level section is allowed (e.g. Database logging) it implies that its sub-sections (Tables, Items) are also selected. In cases when only the sub-section is allowed but not the top-level section only the sub-section will be modifiable and the top-level section will be empty.
If a restricted section exists in the include file the gateway will send an error message and the setup will not be applied. All restricted sections will be hidden by default in the Gateway Setup Editor however they can be shown using “View -> Show restricted sections” menu.
Configuration Options Copied
restrictedSections Copied
This top level section contains settings to restrict/unrestrict particular sections in the setup file.
Mandatory: No
Default: (Everything is unrestricted)
restrictedSections > restrict Copied
A Boolean flag determining whether to restrict
or unrestrict sections. A value of true means all sections are
restricted, a value of false means all sections are
unrestricted. All exceptions are listed in restrictedSections > restrict > sections
below. Restricted sections are greyed out in the
Gateway Setup Editor and users cannot select or
modify them. Unrestricted sections appear as
normal.
Mandatory: No
Default: true
restrictedSections > restrict > sections Copied
This is a list of paths (setup file sections) that can be specified as exceptions to the general rule of restricted/unrestricted flag.
Mandatory: No
Default: (No sections means no exceptions)
restrictedSections > restrict > sections > section Copied
A place (wrapper) where the name of section that is an exception to the restricted sections rule is specified.
Mandatory: No
Default: (No sections means no exceptions)
restrictedSections > restrict > sections > section > path Copied
The name/path of the section that is an exception to the restricted sections rule. It is a dropdown list of all sections present in that setup file.
Mandatory: No
Default: (No sections means no exceptions)
Remote Include Files Copied
The Gateway provides a mechanism for accessing remote, read-only included setup files from a remote location via HTTP and HTTPS protocols.
To make configuration more flexible include file groups allow you to specify authentication and connection details common to a group of files in one place. All of the files within the group will default to these details.
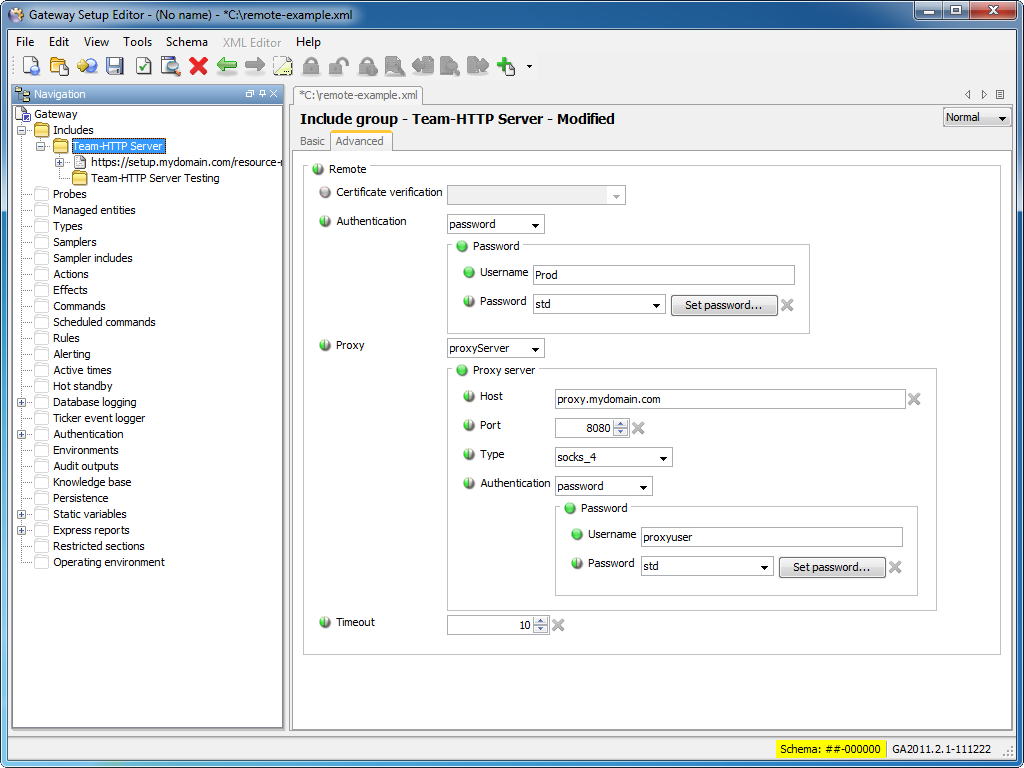
It is possible to override these within a nested group.
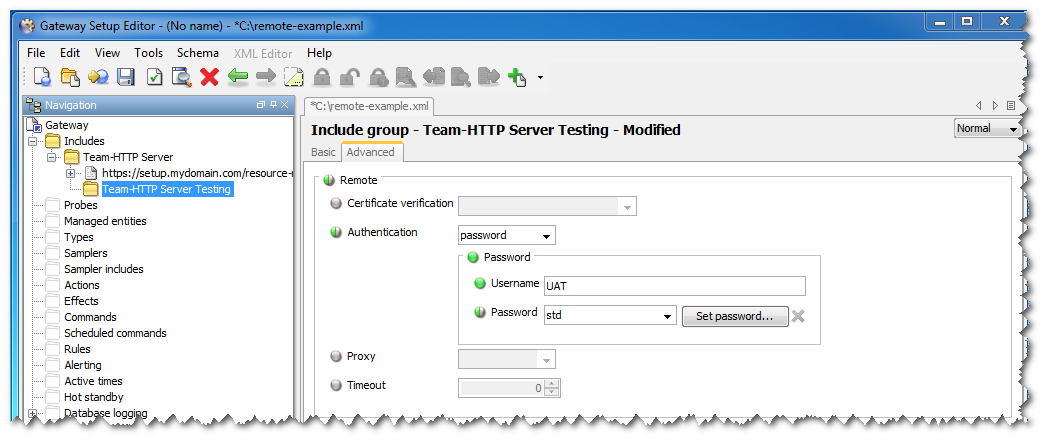
In the figure above, a new group has been added which inherits the settings from the preceding group but changes the authentication details for the testing environment.
Include files themselves may specify all or none of the detail choosing to inherit from a parent group. The location setting for the include file should be the full URL to the include file.
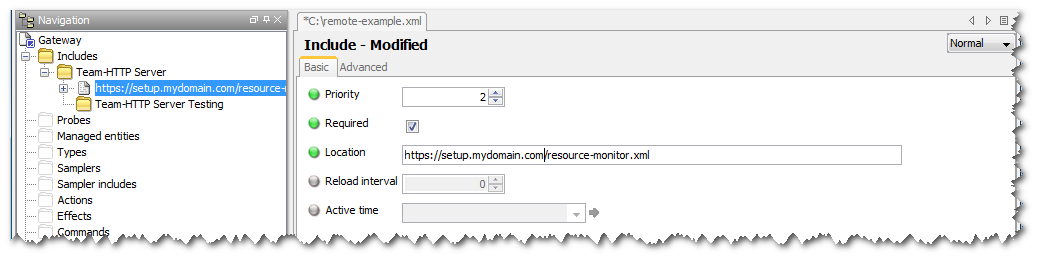
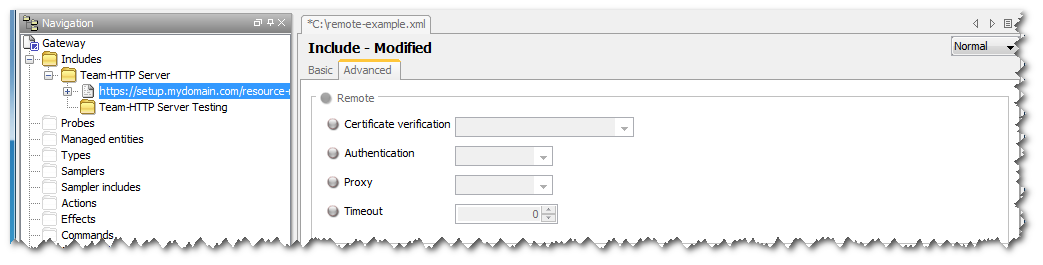
The figure above shows the actual include file being configured. Using the information contained in the parent group and the location configured above the file will be retrieved from the configured URL using the team proxy server and production environment credentials.
Points to Note
- Remote setups are cached as per the Gateway’s caching scheme
- Should the setup be unreachable the gateway will attempt to fall back to the last cached version
- The cURL library should be present on the Gateway’s library search path. Not all configuration options will be supported if it is not and there may be some performance issues as a result.
Common configuration options are described in Remote Include File.
Examples Copied
Merging different departments gateway setup files with a global set of rules Copied
Creating the global rules Copied
Create a new gateway setup file using the gateway setup editor; this setup file will contain all of our global rules. The setup file needs to have a new rule group called “Hardware Rules” which contains 2 rules called “CPU Overloaded” and “Network Overloaded”. The setup editor should look the same as Figure 4-7.
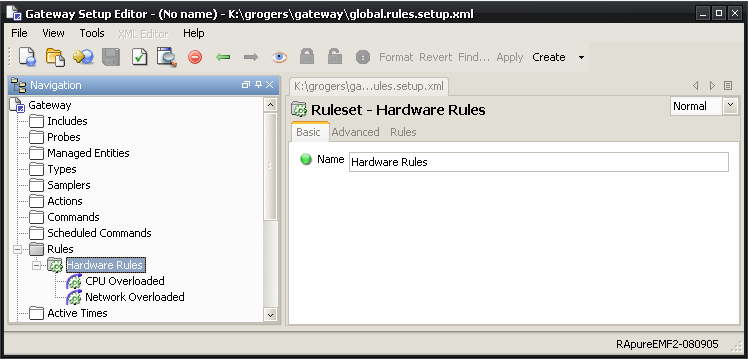
Figure 4-7 Gateway Setup Editor - Creating Rules
Next the target and rule need to be set for “CPU Overloaded”. Click on the edit button and make the path selection dialog contain the following with “Filter on selected elements” ticked:
| Element | Attribute | Value |
|---|---|---|
| Sampler | Type | Hardware Type |
| Sampler | Name | Hardware |
| row | Name | cpuUtilisation |
| cell | Column | Value |
The rule needs to be set to the following:
if value > 90 then
severity critical
;elseif value > 80 then
severity warning
else
severity ok
endif
Figure 4-8 shows what the setup editor should look like after making these changes.
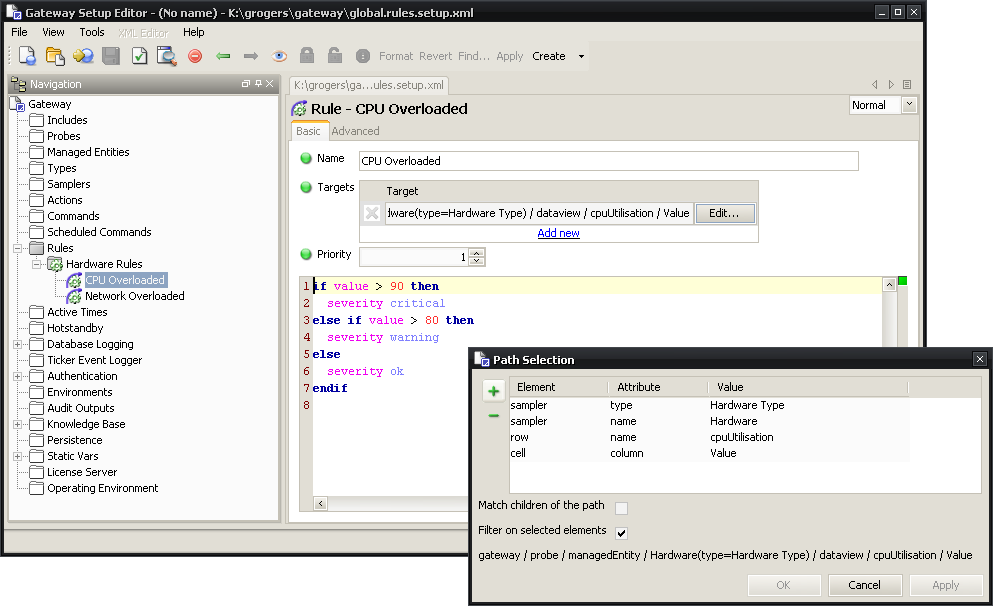
Figure 4-8 Gateway Setup Editor - CPU Overloaded Rule
The “Network Overloaded” rule follows the same setup as the “CPU Overloaded”. The target needs to be set to the following with “Filter on selected elements” ticked:
| Element | Attribute | Value |
|---|---|---|
| sampler | Type | Hardware Type |
| sampler | Name | Network |
| cell | Column | percentSendErrors |
The rule needs to be set to the following:
if value <> 0 then
severity critical
else
severity ok
endif
Figure 4-9 shows what the setup editor should look like after making these changes.
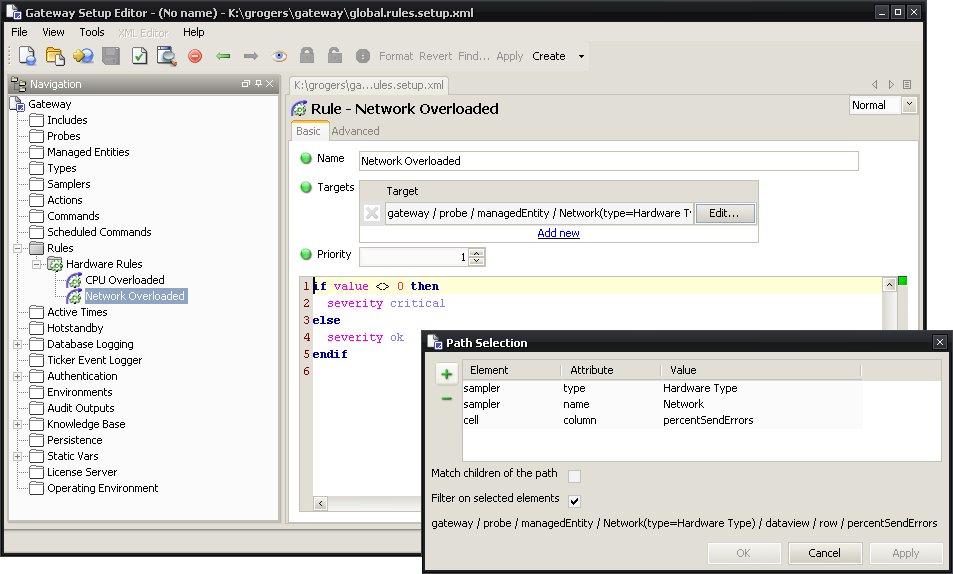
Figure 4-9 Gateway Setup Editor - Network Overloaded Rule
The global rules setup file is now complete and needs to be saved as “global.rules.setup.xml”.
Creating the department gateway setup file Copied
e.g. Equities and fixed income department
Create a new gateway setup file using the gateway setup editor. The setup file needs to have the following configured:
Samplers:
- Hardware
- Network
Types:
- Hardware Type, which references the samplers Hardware and Network
Probes:
- aSolarisMachine
- aLinuxMachine
- aWindowsMachine
Managed Entities:
- aSolarisManagedEntity that references the probe aSolarisMachine and the type Hardware Type.
- aLinuxManagedEntity that references the probe aLinuxMachine and the type Hardware Type.
- aWindowsManagedEntity that references the probe aWindowsMachine and the type Hardware Type.
Includes:
- Priority set to 1.
Included file global.rules.setup.xml with a priority of 2.
Save this file as equities.gateway.setup.xml and save a copy as fixedincome.gateway.setup.xml. These setup files will share the same base configuration for simplicity.
Benefit of merging the files Copied
The equities and fixed income departments now rely on global rules. This means that if the rule for “CPU Overloaded” needed to be changed so that severity is critical when the value reaches 85% instead of 90% it only has to be done in 1 place, this makes maintenance easier.
Adding a rule to the equities setup file Copied
The equities department want to add a rule for the windows network sampler that is not specified by the global rule due to the columns being named differently. To do this a new rule set needs to be created in the equities.gateway.setup.xml file. This will be called “Windows Rules” and will contain a rule called “Network Overloaded”.
Note
It is possible to have rules with the same name in a gateway setup file as long as they belong to different rule groups.
The target needs to be set to the following with “Filter on selected elements” ticked:
| Element | Attribute | Value |
|---|---|---|
| sampler | name | Network |
| cell | column | packetSentErrorRate |
The rule needs to be set to the following:
if value unlike "0.00*" then
severity critical
else
severity ok
endif
How merging works Copied
Each setting in the setup file that does not contain a name or reference. E.g. the top-level samplers section will be merged recursively; any settings inside this section will be merged providing they too do not have a name or reference. If there are any settings that cannot be merged the setup file with the highest priority’s setting will be kept. The first exception is the tickerEventLogger section will never be merged. The second exception is that groups used for setup management (e.g. probeGroup, samplerGroup, managedEntityGroup, and ruleGroup elements) will all be merged recursively even though they have a name or reference. Any settings that exist in a lower priority setup file but are not in a higher priority file will be added.
To see the rules with examples for merging please refer to Setup Merging Rules.
Figure 4-10 shows what the setup editor should look like after making these changes.
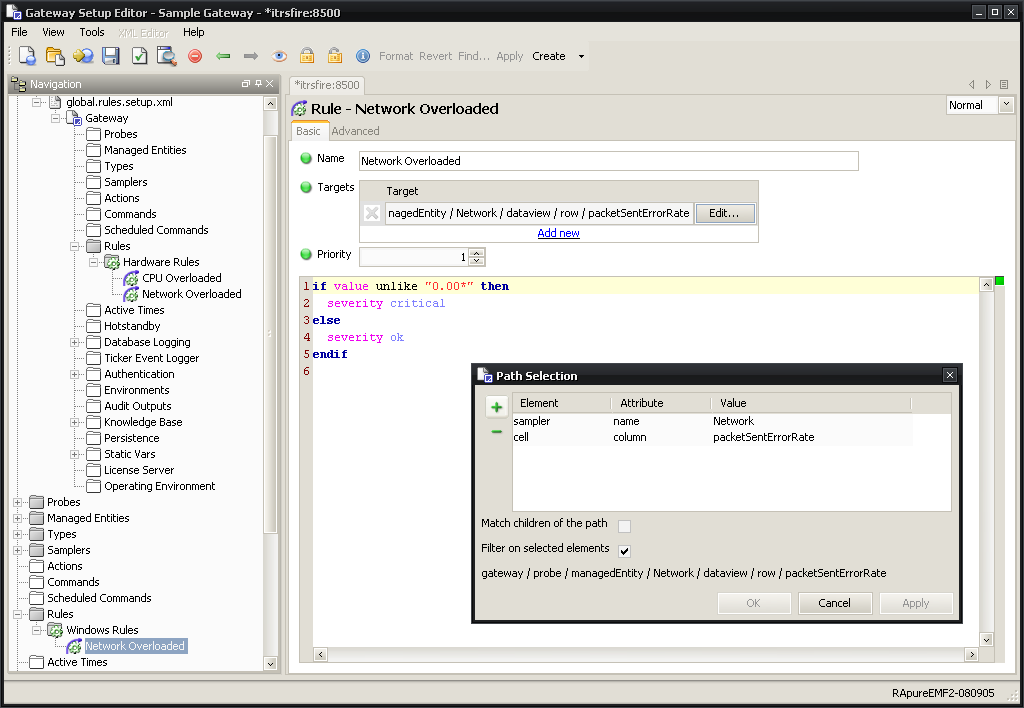
Figure 4-10 Gateway Setup Editor - Network Overloaded Rule
When equities.gateway.setup.xml is now sent to the gateway it will include all of the global rules and the additional rule setup for the windows network sampler.
Overriding a global rule in the fixed income setup file Copied
The fixed income department want to override the global rule called “CPU Overloaded” and change the rule to set the severity to warning if the CPU goes over 50%. To do this a new rule group needs to be created in the fixedincome.gateway.seutp.xml. This will be called “Hardware Rules”.
Note
The “Hardware Rules” in the fixed income setup file will overwrite the one in the global rules setup file due to the fixed income setup file having the higher priority.
The “CPU Overloaded” rule can be copied and pasted from the global rules section to the fixed income rules section. In the rule the value 80 would be changed to 50.
When fixedincome.gateway.setup.xml is now send to the gateway it will only include the fixed income rule. This is a problem as the “Network Overloaded” rule is now no longer included because it belonged to the “Hardware Rules” in the global rules setup file. To solve this problem the “Network Overloaded” rule would need to be moved to a separate rule group called “Network Rules” in the global rules setup file.
After making these 2 changes the fixed income setup file will now correctly overwrite the “CPU Overloaded” rule and include the “Network Overloaded” rule from the global rules setup file.
Configuration Options Copied
The options for configuring multiple setup files are listed below:
includes Copied
Only the main setup file can contain an includes top-level section, which specifies all the additional files to be included. This prevents cycles where (for example) setup file A includes file B, which includes file A again.
includes > priority Copied
The priority controls the importance of a file when merging. Sections in a higher priority file will take precedence over sections in a lower priority file (see the File merging section above). The priority is specified as an integer value in the range 1 to (231 -1) inclusive, with 1 being the highest priority. This particular priority setting affects the priority of configuration in the main setup file, rather than any included setup files.
includes > reloading Copied
This section controls when a gateway will reload its setup. Normally the gateway does not reload its setup unless a user edits the setup via the Gateway setup editor. This section allows the users to automatically reread the setup or to disable reloading of the setup even when the Gateway setup editor sends an update.
includes > reloading > reloadInterval Copied
The interval time in seconds between each reload of the setup.
If this is set, then the Gateway attempts to reload the setup after the reload interval. If the file has changed, then it will be reloaded.
Reload time starts counting down from your first GSE save state after making the new configuration change. Any subsequent manual saves reset the reload timer.
Mandatory: No
includes > reloading > activeTime Copied
This active time controls the times the gateway setup can be changed. If not set then gateway setup changes are applied when they are detected.
If the active time value is set and the gateway is running outside the active time then the setup will not change.
If the Gateway setup editor is used to change the setup while this active time is inactive then the setup file(s) will be changed on disk but the gateway will keep running using the old setup. If the gateway is then restarted the gateway will keep running using the old setup (which it has stored in its cache).
If the file on disk is changed by another source and the reload interval has been set, the changed file will be ignored while the active time is inactive.
When the active time switches from inactive to active, the files on disk will be checked and a new setup applied if available.
If the gateway reloads a setup due to receiving a SIGUSR1 signal, then the setup will be reloaded from disk, ignoring the activeTime settings.
Mandatory: No
includes > reloading > applyToIncludes Copied
If this is set to true then the active time and the reload interval will be applied to the main setup and any include files otherwise it will only apply to the main setup file.
Mandatory: No
Default: false
includes > includeGroup Copied
Include groups allow include files to be placed in logical groupings. For remote include files that reside on a webserver, these also allow for the grouping of common server and access settings for the group. These settings may be overridden by a nested group or directly by the include file configuration.
includes > includeGroup > name Copied
The name of the include group.
Mandatory: Yes
includes > includeGroup > remote Copied
This setting is used when accessing remote, read-only include file(s) from a remote location such as webserver via HTTP and HTTPs protocols. The values specified in this section applies to all individual include files within this includeGroup (and its nested includeGroups) unless they choose to override them.
The location setting for the remote include file should be the full URL path to the include file. For example:
http://setup.mydomain.com/include.xml
https://mydomain.com:2345/setups/include.xml
Mandatory: No
See Remote Include Files for an explanation of how to retrieve configuration from a webserver. See Detailed Configuration for Remote Include Files for a detailed discussion of the common configuration options for Remote Include files.
includes > includeGroup > remote > certificateVerification Copied
The connection to proxy server can be http (unencrypted) or https (SSL encrypted).When using SSL connections the certificate can also be verified. This setting specified what to check within the certificate.
| Setting | Description |
|---|---|
| None | Will succeed as long as any certificate is present. |
| Against authority | Checks the certificate to ensure it has been signed by a Certificate Authority (CA) that is trusted, but doesn’t check that the hostname matches. |
| Against authority and hostname | Checks that the certificate has been signed by a trusted CA and that the hostname matches |
When checking the certificate against a Certificate Authority then a CA Bundle in PEM format must be used. This file specifies the CAs that is to be trusted. If the operating system has not come with a CA or it is out of date then a CA Bundle should be specified.
This can either be constructed (if, for example, you wish to add your own trusted authorities when self-signing) or downloaded. If you wish to generate your own then please search online for ‘Creating a PEM CA bundle’. If you just wish to download an existing one then you can do so from the cURL page describing how to extract CA certificates from Mozilla:
http://curl.haxx.se/docs/caextract.html
Mandatory: No
Default: none
includes > includeGroup > remote > authentication Copied
This setting specifies the credentials that the webserver may require to authenticate users trying to retrieve include files. One can configure the username and password. The password may be encrypted in the setup.
Mandatory: No
Default: No authentication
includes > includeGroup > remote > authentication > none Copied
This setting means no authentication is required to access remote include file hosted on a webserver.
Mandatory: No
Default: No authentication
includes > includeGroup > remote > authentication > password Copied
This section specifies the username and password one would require to access remote include file hosted on a secured webserver.
Mandatory: No
includes > includeGroup > remote > authentication > password > username Copied
The username with which one can access the remote include file.
Mandatory: No
includes > includeGroup > remote > authentication > password > password Copied
The password configuration allows gateway to specify the password with which it can access the remote include files.
Mandatory: No
includes > includeGroup > remote > authentication > password > plaintext Copied
This option specifies the password in un-encrypted format.
Mandatory: No
includes > includeGroup > remote > authentication > password > std Copied
This option specifies the password using std encryption.
Mandatory: No
includes > includeGroup > remote > authentication > password > stdAES Copied
This option specifies the password using AES 256 encryption.
See: Using Secure Passwords on the Gateway
Mandatory: No
includes > includeGroup > remote > authentication > password > method Copied
Allows Basic and GSS-Negotiate (Kerberos) HTTP authentication methods to be selected.
Both methods are enabled by default, but is recommended that you select only one method to speed up the request.
Kerberos authentication requires -kerberos-principal and -kerberos-keytab to be set using the command line. See Gateway Command Line options.
Note
Kerberos authentication is only available on Linux systems.
Mandatory: No
Default: Both methods are enabled.
includes > includeGroup > remote > proxy Copied
This option specifies the settings of a proxy server, that a request to access remote include file, might have to pass through.
Mandatory: No
Default: No proxy server
includes > includeGroup > remote > proxy > none Copied
This option is used to explicitly disable proxy server.
Mandatory: No
Default: No proxy server
includes > includeGroup > remote > proxy > proxyServer Copied
This setting specifies the proxy server settings to access remote include file.
Mandatory: No
includes > includeGroup > remote > proxy > proxyServer > host Copied
This setting specifies the hostname for the proxy server.
Mandatory: Yes
includes > includeGroup > remote > proxy > proxyServer > port Copied
This setting specifies the port the proxy server is listening on.
Mandatory: Yes
Default: 80 (http) or 443 (https)
includes > includeGroup > remote > proxy > proxyServer > type Copied
The setting specified the type of proxy server to use. Six types are currently supported.
| Type | Description |
|---|---|
| HTTP | Http 1.1 |
| HTTP 1.0 | Http 1.0. |
| SOCKS 4 | Socks 4. |
| SOCKS 4A | Socks 4a. |
| SOCKS 5 | Socks 5 but resolve the hostname locally. |
| ‘SOCKS 5 Hostname" | Socks 5 and let the proxy resolve the hostname. |
Mandatory: Yes
includes > includeGroup > remote > proxy > proxyServer > authentication Copied
This setting specifies the credentials that the proxy server may require to authenticate users trying to retrieve include files. One can configure the username and password. The password may be encrypted in the setup.
Mandatory: No
Default: None
includes > includeGroup > remote > proxy > proxyServer > authentication > none Copied
This setting is used to explicitly disable authentication to proxy server.
Mandatory: No
includes > includeGroup > remote > proxy > proxyServer > authentication > password Copied
This section specifies the username and password combinations to be sent to proxy servers.
Mandatory: No
includes > includeGroup > remote > proxy > proxyServer > authentication > password > username Copied
The username with which one can access the remote include file using the proxy server.
Mandatory: No
includes > includeGroup > remote > proxy > proxyServer > authentication > password > password Copied
The password configuration allows gateway to specify the password with which it can access the remote include files using the proxy server.
Mandatory: No
includes > includeGroup > remote > proxy > proxyServer > authentication > password > password > plaintext Copied
This option specifies the proxy server password in un-encrypted format.
Mandatory: No
includes > includeGroup > remote > proxy > proxyServer > authentication > password > password > std Copied
This option specifies the proxy server password using std encryption.
Mandatory: No
includes > includeGroup > remote > proxy > proxyServer > authentication > password > password > stdAES Copied
This option specifies the proxy server password using AES 256 encryption.
See: Using Secure Passwords on the Gateway
Mandatory: No
includes > includeGroup > remote > timeout Copied
Fetching the remote include file may take too long due to demands on the server or network traffic. This setting allows you specify in seconds how long the Gateway should wait for the transfer to complete.
Mandatory: No
Units: Seconds
Default: 0 (no timeout)
includes > include Copied
The includes section can contain any number of include elements, each of which specifies a single file to include.
includes > include > priority Copied
Controls the importance of a specific includes file while merging.
includes > include > required Copied
Marks an included setup file as being required or
not. This is a Boolean value and should be set to
either true or false. If an included setup file
is inaccessible for some reason, this setting then
controls gateway behaviour. For files which are
required (this setting is set to true) the gateway
will not apply the setup if the file is inaccessible.
Non-required files which are inaccessible will
generate a warning, but gateway will continue to load
and apply the setup.
includes > include > location Copied
Specifies the location of the file to include.
This should be specified in the form of a file URL
(i.e. file://<pathtofile>) and can be specified as
either an absolute or relative path. Relative paths
are relative to the location of the main setup
file.
For remote include files the path should always be the full URL from which to retrieve the file.
See Remote Include Files for an explanation of how to retrieve configuration from a webserver. See Detailed Configuration for Remote Include Files for a detailed discussion of the common configuration options for Remote Include files.
includes > include > reloadInterval Copied
The interval time in seconds between each reload of this include file. This overrides the setting in the includes > reloading section if applyToIncludes has been set to true.
Mandatory: No
includes > include > activeTime Copied
Specifies an active time to apply when using checking this include file for changes. This overrides the setting in the includes > reloading section if applyToIncludes has been set to true.
Mandatory: No
includes > include > remote Copied
This setting is used when accessing remote, read-only include file(s) from a remote location such as webserver via HTTP and HTTPs protocols. The values specified in this section will override any values specified in the ancestor includeGroups.
The location setting for the remote include file should be the full URL path to the include file. For example:
http://setup.mydomain.com/include.xml
https://mydomain.com:2345/setups/include.xml
Mandatory: No
See Remote Include Files for an explanation of how to retrieve configuration from a webserver. See Detailed Configuration for Remote Include Files for a detailed discussion of the common configuration options for Remote Include files.
includes > include > remote > certificateVerification Copied
The connection to proxy server can be http (unencrypted) or https (SSL encrypted).When using SSL connections the certificate can also be verified. This setting specified what to check within the certificate.
| Setting | Description |
|---|---|
| None | Will succeed as long as any certificate is present. |
| Against authority | Checks the certificate to ensure it has been signed by a Certificate Authority (CA) that is trusted, but doesn’t check that the hostname matches. |
| Against authority and hostname | Checks that the certificate has been signed by a trusted CA and that the hostname matches. |
When checking the certificate against a Certificate Authority then a CA Bundle in PEM format must be used. This file specifies the CAs that is to be trusted. If the operating system has not come with a CA or it is out of date then a CA Bundle should be specified.
This can either be constructed (if, for example, you wish to add your own trusted authorities when self-signing) or downloaded. If you wish to generate your own then please search online for ‘Creating a PEM CA bundle’. If you just wish to download an existing one then you can do so from the cURL page describing how to extract CA certificates from Mozilla:
http://curl.haxx.se/docs/caextract.html
Mandatory: No
Default: none
includes > include > remote > authentication Copied
This setting specifies the credentials that the webserver may require to authenticate users trying to retrieve include files. One can configure the username and password. The password may be encrypted in the setup.
Mandatory: No
Default: No authentication
includes > include > remote > authentication > none Copied
This setting means no authentication is required to access remote include file hosted on a webserver.
Mandatory: No
Default: No authentication
includes > include > remote > authentication > password Copied
This section specifies the username and password one would require to access remote include file hosted on a secured webserver.
Mandatory: No
includes > include > remote > authentication > password > username Copied
The username with which one can access the remote include file.
Mandatory: No
includes > include > remote > authentication > password > password Copied
The password configuration allows gateway to specify the password with which it can access the remote include files.
Mandatory: No
includes > include > remote > authentication > password > plaintext Copied
This option specifies the password in un-encrypted format.
Mandatory: No
includes > include > remote > authentication > password > plaintext > std Copied
This option specifies the password using std encryption.
Mandatory: No
includes > include > remote > authentication > password > plaintext > stdAES Copied
This option specifies the password using AES 256 encryption.
See: Using Secure Passwords on the Gateway
Mandatory: No
includes > include > remote > authentication > password > method Copied
Allows Basic and GSS-Negotiate (Kerberos) HTTP authentication methods to be selected.
Both methods are enabled by default, but is recommended that you select only one method to speed up the request.
Kerberos authentication requires -kerberos-principal and -kerberos-keytab to be set using the command line. See Gateway Command Line options.
Note
Kerberos authentication is only available on Linux systems.
Mandatory: No
Default: Both methods are enabled.
includes > include > remote > proxy Copied
This option specifies the settings of a proxy server, that a request to access remote include file, might have to pass through.
Mandatory: No
Default: No proxy server
includes > include > remote > proxy > none Copied
This option is used to explicitly disable proxy server.
Mandatory: No
Default: No proxy server
includes > include > remote > proxy > proxyServer Copied
This setting specifies the proxy server settings to access remote include file.
Mandatory: No
includes > include > remote > proxy > proxyServer > host Copied
This setting specifies the hostname for the proxy server.
Mandatory: Yes
includes > include > remote > proxy > proxyServer > port Copied
This setting specifies the port the proxy server is listening on.
Mandatory: Yes
Default: 80 (http) or 443 (https)
includes > include > remote > proxy > proxyServer > type Copied
The setting specified the type of proxy server to use. Six types are currently supported.
| Type | Description |
|---|---|
| HTTP | Http 1.1 |
| HTTP 1.0 | Http 1.0. |
| SOCKS 4 | Socks 4. |
| SOCKS 4A | Socks 4a. |
| SOCKS 5 | Socks 5 but resolve the hostname locally. |
| SOCKS 5 Hostname | Socks 5 and let the proxy resolve the hostname. |
Mandatory: Yes
includes > include > remote > proxy > proxyServer > authentication Copied
This setting specifies the credentials that the proxy server may require to authenticate users trying to retrieve include files. One can configure the username and password. The password may be encrypted in the setup.
Mandatory: No
Default: None
includes > include > remote > proxy > proxyServer > authentication > none Copied
This setting is used to explicitly disable authentication to proxy server.
Mandatory: No
includes > include > remote > proxy > proxyServer > authentication > password Copied
This section specifies the username and password combinations to be sent to proxy servers.
Mandatory: No
includes > include > remote > proxy > proxyServer > authentication > password > username Copied
The username with which one can access the remote include file using the proxy server.
Mandatory: No
includes > include > remote > proxy > proxyServer > authentication > password > password Copied
The password configuration allows gateway to specify the password with which it can access the remote include files using the proxy server.
Mandatory: No
includes > include > remote > proxy > proxyServer > authentication > password > password > plaintext Copied
This option specifies the proxy server password in un-encrypted format.
Mandatory: No
includes > include > remote > proxy > proxyServer > authentication > password > password > std Copied
This option specifies the proxy server password using std encryption.
Mandatory: No
includes > include > remote > proxy > proxyServer > authentication > password > password > stdAES Copied
This option specifies the proxy server password using AES 256 encryption.
See: Using Secure Passwords on the Gateway
Mandatory: No
includes > include > remote > timeout Copied
Fetching the remote include file may take too long due to demands on the server or network traffic. This setting allows you specify in seconds how long the Gateway should wait for the transfer to complete.
Mandatory: No
Units: Seconds
Default: 0 (no timeout)
Detailed Configuration for Remote Include Files Copied
The Remote Include Files section was an overview of how to include configuration hosted on a webserver. This appendix seeks to continue this in more depth discussing the options available for configuration at a group and individual include file level.
To retrieve setup from a remote server you need to connect to a host using a particular protocol, possibly authenticate yourself and there may be a proxy server your request has to pass through. You may also need a way to cancel the operation if file retrieval is taking too long.
The settings to accomplish this are common to Include Groups and individual Include files. The figure below shows an example containing the common settings. Most of these are self-explanatory but we’ll discuss them in detail below.
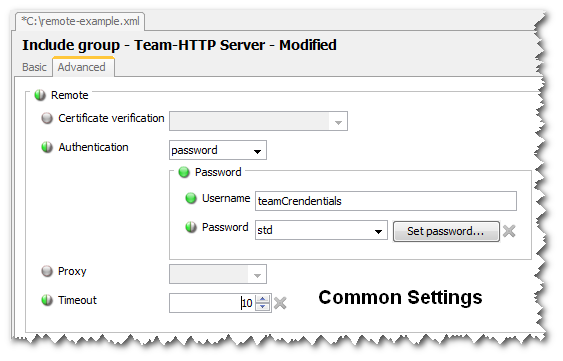
Figure 41-1 - Common Remote Include settings
Connecting to the host and file retrieval Copied
The basic settings necessary for using remote include files are the location as a URL, along with a timeout.
Location
This setting is specific to individual include files. The location is the complete URL used to retieve the include file including protocol (http, https) and possibly port. See includes > include for details.
For example:
http://setup.mydomain.com/include.xml
https://mydomain.com:2345/setups/include.xml
Timeout
Fetching the file may take too long due to demands on the server or network traffic for example. This setting allows you specify in seconds how long the Gateway should wait for the transfer to complete.
Authenticating against the HTTP server Copied
The webserver may be configured to authenticate users trying to retrieve files. The authentication section of the configuration deals with this.
Here you configure the username and password. The password may be encrypted in the setup.
Authentication methods Copied
All supported authentication methods are enabled by default. Kerberos authentication (GSS-Negotiate) requires additional configuration prior to use.
IPv6 with NTLM
In a few cases timeout issues have been seen when using NTLM authentication with some types of IPv6 environments.
If you experience any issues then please contact ITRS support so that we can gather more information to diagnose the root cause.
Authenticating with Kerberos Copied
Before setting the Gateway to use Kerberos authentication to connect to a web server, the client machine must first acquire a Kerberos ticket-granting ticket from that web server. The following guidelines describe how to acquire the ticket on a Linux client machine with support for Kerberos. The Gateway currently supports Kerberos authentication on this platform only.
- Verify that the Kerberos realm of the web server is defined in the Kerberos configuration of the client. The configuration file is in /etc/krb5.conf. Below is an example of the realms section of the configuration file:
...
[realms]
EXAMPLE.COM = {
kdc = kerberos.example.com:88
admin_server = kerberos.example.com:749
default_domain = example.com
}
...
- Check that the realm of the web server is defined with the corresponding names of the kdc, admin server and default domain.
- Generate the Kerberos ticket-granting ticket for an authorized user and store it in the default location. This can be done by running kinit <user@realm> on the command line. Enter the password when prompted.
# kinit User@EXAMPLE.COM
- Run klist on the command line to view the generated ticket. Verify that ticket is stored in the default location, i.e. /tmp/krb5cc_0.
# klist
The ticket has a finite lifetime and the client machine will need to regenerate it once it expires. The lifetime of a ticket is controlled by the Kerberos Key Distribution Center (KDC) of the web server, which issues the tickets. The default expiration is typically set to 8 or 10 hours, but can be configured to a longer duration in the KDC. Ticket renewal polices can also be set between the web server and client. Consult your web server administrator on how to configure Kerberos the ticket lifetime and renewal.
Configuring a Proxy server Copied
The default proxy configuration is “none”. That is it’s assumed that there is no proxy server. If you need to configure a proxy server you should populate the following fields.
Host
This is the machine on which the proxy server is running. It can be specified as an IP-address or server name. The default value if not configured is “localhost”.
Port
The port on which the proxy server is listening for connections, if not set this is defaulted to port 80.
Type
Six types of proxy server are supported.
| Proxy Server | Version Type |
|---|---|
| HTTP | Http 1.1. |
| HTTP 1.0 | Http 1.0. |
| SOCKS 4 | Socks 4. |
| SOCKS 4A | Socks 4a. |
| SOCKS 5 | Socks 5 but resolve the hostname locally. |
| SOCKS 5 Hostname | Socks 5 and let the proxy resolve the hostname. |
Authentication
The authentication section for the Proxy Server matches that of the HTTP Server.
Viewing Remote Include files from the Setup Editor Copied
The Gateway Setup Editor allows you to view remote include files. Remote files cannot be saved, and will therefore be loaded read-only to prevent editing.
The GSE downloads remote include files via the Gateway. This means that it’s not necessary for the files to be visible from the machines running the GSE, but does mean that the main setup file needs to have been loaded via a Gateway (rather than the main setup file being a local file) and that the relevant Gateway connection is up.
Remote include files were introduced in version 3.0.10, and the Gateway must be that version or newer. If an include file is behind a proxy server, or is protected with authentication, then the GSE must also have been upgraded to this version as it needs to provide additional information to the Gateway. If the remote include can be accessed by the Gateway without using these advanced features, then an older GSE may be used to view the remote include files.
Gateway Operating Environment Copied
The gateway operating environment top-level section contains gateway settings which affect the gateway as a whole, and which do not belong to any other section. Almost all of the settings in this section are optional.
The only mandatory setting in this section is the gatewayName. This name is displayed to all users which connect to the gateway, and is also used in name lookup and database logging. It is strongly recommended that this name be unique for each gateway on a particular site.
The gateway listen ports can also be set in the operating environment (operatingEnvironment > listenPorts). The listen ports are used by components connecting to gateway (such as ActiveConsole 2 or WebSlinger) to request monitoring data for display to users.
Note
This does not include Netprobe connections, as configuration for these are contained within the probes top-level section. If not configured, the gateway listen port will default to port7039for insecure channel and7038for secure channel.
The listen port can also be specified as a command-line argument to gateway. If this is done, then the command-line value is used for the lifetime of the gateway process - it cannot be overridden or altered by editing the gateway setup file. An example of using this command-line option is shown below:
gateway2 -port 12345
Configuration Options Copied
The following configuration options are settable in the operating environment.
General Options Copied
operatingEnvironment Copied
Gateway wide options are configured here.
operatingEnvironment > gatewayId Copied
Note
This setting has been deprecated because the Gateway name is now used to uniquely identify a gateway.
This setting specifies a unique gateway identifier, which is used internally to gateway. In addition, it may also be used in future to amalgamate data from various sources into a single stream. Typically this identifier is automatically generated by hashing the gateway name, but can be overridden as required (e.g. if two different gateway names hash to the same value). Valid values for the gateway id are from 1 to 4,000,000,000 (inclusive).
Mandatory: No
Default: Generated by hashing the gatewayName.
operatingEnvironment > gatewayName Copied
A short name identifying the gateway. This name is also logged to the database and used to identify records for this gateway, when using database logging functionality.
Mandatory: Yes
operatingEnvironment > description Copied
An optional description of the gateway.
Mandatory: No
operatingEnvironment > maxLogFileSizeMb Copied
The size (in megabytes) that the gateway should allow the file to which it is logging, before it rolls that log file over. Valid values are in the inclusive range 1 to 2047 for 32-bit Gateways.
Mandatory: No
Default: 10 MB
operatingEnvironment > logArchiveScript Copied
The name of a batch file or shell script that should be executed when the log file is rolled over.
Note
Using operatingEnvironment > logArchiveScript overrides LOG_ARCHIVE_SCRIPT (if set).
Mandatory: No
operatingEnvironment > listenPort Copied
Deprecated: The insecure gateway listen port for incoming connections. Specify an integer in the range 1-65535. The operatingEnvironment > listenPorts should be used instead of this setting.
Mandatory: No
Default: 7039
operatingEnvironment > listenPorts Copied
The gateway listen ports for incoming connections.
If operatingEnvironment > listenPorts > secure is set and operatingEnvironment > listenPorts > insecure is not set, then the gateway will only listen on a secure port.
If operatingEnvironment > listenPorts > secure is not set then the gateway will only listen on an insecure port.
If both operatingEnvironment > listenPorts > secure and operatingEnvironment > listenPorts > insecure are set then the gateway will listen on two ports. One secure and one insecure.
See Secure Communications for more details.
Mandatory: No
Default: The gateway will listen insecurely on port 7039
operatingEnvironment > listenPorts > secure Copied
This specifies that the gateway should listen securely. In order to listen securely, a SSL certificate needs to be provided using either the -ssl-certificate or -ssl-certificate-key command line option. By default if configured to be secure, the gateway will listen on port 7038. This can be overriden by using the child setting operatingEnvironment > listenPorts > secure > listenPort.
Mandatory: No
Default: The gateway will not listen securely on any port
operatingEnvironment > listenPorts > secure > listenPort Copied
This value overrides the default secure listenPort. Specify an integer in the range 1-65535.
Mandatory: No
Default: 7038
operatingEnvironment > listenPorts > insecure Copied
This specifies that the gateway should insecurely. By default if configured to allow insecure connections, the gateway will listen on port 7039. This can be overriden by using the child setting operatingEnvironment > listenPorts > insecure > listenPort.
Mandatory: No
Default: See operatingEnvironment > listenPorts
operatingEnvironment > listenPorts > insecure > listenPort Copied
This value overrides the default insecure listenPort. Specify an integer in the range 1-65535.
Mandatory: No
Default: 7039
operatingEnvironment > timezone Copied
The time zone the gateway will run in. This allows a Gateway in one country to monitor Netprobes in another country whilst keeping the time zones the same.
The time zone is specified in the format:
std[+/-offset]
Where std represents one of the standard time
zones. Available valid time zones can be found by
examining the system time zone database, found in
/usr/share/lib/zoneinfo on
Solaris or /usr/share/zoneinfo on Linux.
If you specify an offset explicitly, it will override the definition in the system time database, including the rules to automatically adjust for daylight savings time.
It is interpreted as the number of hours necessary to add or subtract to get Coordinated Universal Time (UTC).
For example, if you want your gateway to run in US Eastern Standard Time, you can:
(recommended) specify the timezone as America/New\_York, or
- Specify the timezone as
EST, or - (not recommended) Specify the timezone as
EST+5EDT,M3.2.0/2,M11.1.0/2(see the POSIX documentation for theTZvariable), or - (not recommended) Specify the timezone as
EST+5when DST is not in effect and change it toEST+6when DST is in effect.
The Gateway will attempt to validate your choice of timezone against the zoneinfo directories, issuing a warning if the timezone cannot be verified.
Mandatory: No
Default: Gateway uses the value of the TZ environment variable or, if this is not set, the local time of the machine it is running on.
operatingEnvironment > timezone Copied
abbreviation
A list of time zone abbreviations and their default timezone regions. This is used to over-ride the timezone abbreviation interpretations in Rules timezone parsing/printing.
operatingEnvironment > heartbeatInterval Copied
When gateway does not receive any communication from a connected component within this number of seconds, it sends a heartbeat message to the component. Gateway will then expect a reply within the number of seconds specified by the connectWait setting. If the reply is not received within this time, the connection is terminated and re-established. The valid range for the heartbeat interval is 20-300 seconds inclusive.
Mandatory: No
Default: 75 (seconds)
operatingEnvironment > connectWait Copied
The time to wait (in seconds) for a connection to Netprobe to be established. (i.e. The maximum duration of time the gateway will wait after sending the initial TCP SYN segment, for a SYN/ACK reply from the Netprobe). The valid range is 1-300 seconds inclusive.
Mandatory: No
Default: 30 (seconds)
operatingEnvironment > dnsCacheExpiryTime Copied
When Gateway resolves a hostname to an IP address, it will cache the result for the time period specified by this setting.
The valid values are from 0-2880 minutes inclusive. If a value of 0 is used, hostnames are cached indefinitely (duplicating Gateway 1 behaviour).
If enabled, DNS entries are altered based on the value keyed in the DNS cache expiry time. However, you must disconnect the Netprobe from the Gateway for the new DNS entries to take effect. This is because Netprobe is in control of the communication between Gateway and Netprobe.
Note
Gateway only initiates the handshake communication between Gateway and Netprobe. Once communication is established, the Netprobe takes the control of the communication from the Gateway.
Mandatory: No
Default: 720 (12 hours)
operatingEnvironment > internalQueueSizeLimit Copied
This setting controls the maximum length of the internal update queue. Updates to data-items (e.g. a severity change as the result of running a rule) are placed in the queue temporarily between data updates.
The default maximum limit should be adequate for normal gateway operation. If a pair (or more) of rules are configured such that an update caused by rule A makes rule B fire and update, then this can cause the internal queue to fill faster than it is processed. If the queue is completely filled an error message will be logged, and gateway performance is likely to be affected. The solution is to write rules A and B to be more selective, so that they do not fire each other.
Certain compute engine rules (typically involving wildcarded paths) can also fill the processing queue during gateway startup. The queue limit can be increased to prevent warning messages if required, however this should only be done if it is known that this situation is a “one off”.
Mandatory: No
Default: 4000
operatingEnvironment > numRuleEvaluationThreads Copied
Specifies the maximum number of rule evaluation threads the gateway can run. These threads are used to execute rules on data changes, and can be enabled if rule execution is becoming a bottleneck on a busy gateway.
It is recommended that this is not set too high as doubling the number of threads will not double throughput. It should not be set higher than the number of CPU cores available. For more detailed information about the optimum value to use please see the Gateway Performance Tuning document.
This setting specifies a maximum number of threads only, the actual number of threads used will be the minimum of this value and the number of available processors (as specified by taskset on Linux or psrset on Solaris). The number of rule threads used will be recorded in the gateway log. If the available number of processors is changed while the gateway is running then the number of threads to use will be re-evaluated at the next setup change.
A hard limit can also be placed on the number of rule threads by setting the environment variable MAX_RULE_THREADS to a positive integer.
Mandatory: No
Default: 0 (no threads used)
operatingEnvironment > historyFiles Copied
The maximum number of history files that the gateway is allowed to create when receiving set-up changes. Valid values are in the inclusive range 0 to 9999. To suppress history file creation altogether, set this to zero.
Mandatory: No
Default: 10
operatingEnvironment > dataDirectory Copied
Allows a user to specify where temporary files which the gateway may produce while running should be stored. If not set, then files default to being stored in the current working directory. If the directory specified already contains any of these temporary files, then they will be over-written. The data directory must have read, write and execute permissions as it will need to be able to read, write and search within it.
Mandatory: No
Default: The current working directory
operatingEnvironment > duplicateRowAlerts Copied
When duplicate rows in a single dataview are detected, gateway will alert the user of this fact as it indicates a configuration error. These alerts can be adjusted using this setting.
| Value | Effect |
|---|---|
| NONE | No alerts regarding duplicate rows are produced. |
| STATUS | The dataview samplingStatus headline is updated with an error message warning about duplicate rows. |
| TICKER_AND_STATUS | The samplerStatus headline is updated as above, and additionally an event ticker event is created regarding the duplicate rows. |
Mandatory: No
Default: TICKER\_AND\_STATUS
operatingEnvironment > insecurePasswordLevel Copied
In a number of places throughout the Gateway configuration, passwords have to be specified. Examples of this might be plugins that require logins to systems to retrieve the data they need, the gateway’s connection to the database, or the configuration of users. In most of these places it’s possible to enter the password in a number of different formats (depending on context), from a completely unobscured plaintext format, to more secure formats such as AES (for two way) and crypt (for one way).
While it may be useful to use a plaintext format in a UAT or testing environment, you may prefer to ensure that a secure format is used when in a production environment. This setting will help locate these, by causing each insecure password to generate an issue at the specified level. This will then show up when validating or saving the setup.
Note
We have deemed standard encoded passwords (std) to be insecure since they are encoded rather than encrypted, and these will be flagged in the same way as plain text passwords.
With the setting at the lowest level (none) then no checks will be performed on the security of the passwords and no issues will be reported. With the setting at the highest level (critical) then it will not be possible to save the setup or start the gateway with any insecure passwords present. With one of the other levels set, the ability to save the setup with insecure passwords present will depend on whether the -max-severity command line parameter is set. See the Gateway Command Line options section for more details on this parameter.
The level that this is set to is reported in the Gateway Data plugin.
Mandatory: No
Default: none
operatingEnvironment > allowComputeEngine Copied
Specifies whether the Gateway compute engine feature is available to add additional data to existing dataviews. Although, by default it is allowed, administrators and users can use this setting to actually disallow compute engine features. Refer to Compute Engine for more details.
Mandatory: No
Default: true
operatingEnvironment > clientConnectionRequirements > minimumComponentVersion > minimumForAllComponents Copied
This instructs the Gateway to reject connections from every component with versions older than the specified version.
You can specify the minimum version using the:
- Version number. For example, GA4.7.0, or GA2011.2.1.
- Version number with the build date. For example, GA4.7.0-180529.
Mandatory: No
operatingEnvironment > clientConnectionRequirements > minimumComponentVersion > components > component > name Copied
Name of a Geneos component type. The drop-down list has the following options:
- Active Console
- Gateway
- Licence Daemon
- Netprobe
- Web Dashboard
- Webslinger
Mandatory: No
operatingEnvironment > clientConnectionRequirements > minimumComponentVersion > components > component > version Copied
The minimum version of the component selected in operatingEnvironment > clientConnectionRequirements > minimumComponentVersion > components > component > name that the Gateway accepts connections from.
You can specify the minimum version using the:
- Version number. For example, GA4.7.0, or GA2011.2.1.
- Version number with the build date. For example, GA4.7.0-180529.
Mandatory: No
operatingEnvironment > clientConnectionRequirements > requireCertificates Copied
This allows the gateway to require certificates when connections are made to the gateway for certain connection types. This can be enabled/disabled for each supported connection type. The following connection types are supported:
- Netprobe: Incoming connections from netprobes (this will include Floating Netprobes and Self-announcing Netprobes).
- Importing Gateways: Incoming Importing Gateway connections
- Importing Gateways: Incoming Gateway connections from Importing Gateways (to which this gateway will export data).
- Secondary Gateways: Incoming Gateway connections from the secondary Gateway in a Hot Standby configuration.
Mandatory: No
Default: Certificates are not required for any incoming connections.
operatingEnvironment > httpConnectionRequirements Copied
This group of settings allow HTTP requests made to the Gateway (e.g. from a web browser) to be restricted.
operatingEnvironment > httpConnectionRequirements > internalData Copied
The internal data web pages provide low level information about various parts of the system. They may be requested by ITRS support when debugging issues. They do not form part of the normal operation of the Gateway so can safely be restricted to Geneos administrators.
The internal data pages available, and the information available on each page, can vary by version. However, the connection requirements cover all internal data pages, so will secure any pages added in future versions.
operatingEnvironment > httpConnectionRequirements > internalData > acceptHosts Copied
This allows the internal data web pages, used for debugging issues, to be viewed only from particular locations.
To allow access from any host, ‘all’ may be selected. To prevent access completely, ’none’ may be selected. To allow access only from the local loopback interface where the Gateway is running (127.0.0.1), then ’local’ may be selected.
If ‘specific’ is selected then a list of locations may be entered. Each item in the list can be specified as a hostname (if a reverse DNS entry is available for the remote host) or as an IP address. The source of any HTTP requests must then match at least one item in the list otherwise they will be rejected. If no items have been specified in the list then access will also be prevented completely.
The remote hostname and IP address are written to the Gateway log file, along with the URL requested, for any attempts that are blocked. This can be useful to see if the Gateway host is able to access a reverse DNS entry for the remote host and therefore what would need to be added to the ‘specific’ list for the request to be accepted. If a hostname is not available then the IP address will be seen instead of the name in the log file, so will appear twice.
Mandatory: No
Default: local
operatingEnvironment > DNS > maxAcceptableDNSLookupTime Copied
The maximum time in seconds that the Gateway is allowed to perform a reverse DNS lookup.
If this time is exceeded, reverse DNS lookups are disabled for the IP address for the number of units of time specified in DNSReverseLookupDisableTime.
For non-Gateway components, maxAcceptableDNSLookupTime defaults to the time specified in the environment variable $HR_TIMEOUT.
Mandatory: No
Default: 1
operatingEnvironment > DNS > DNSReverseLookupDisableTime > value Copied
Number of units of time that reverse DNS lookups are disabled for after exceeding maxAcceptableDNSLookupTime.
The unit of time is specified using DNSReverseLookupDisableTime > units.
Once the time has elapsed, reverse DNS lookups are re-enabled for the IP address.
For non-Gateway components, DNSReverseLookupDisableTime can be specified using the environment variable $HR_REVERSE_LOOKUP_DISABLE_TIME.
Mandatory: No
Default: 5
operatingEnvironment > DNS > DNSReverseLookupDisableTime > units Copied
The unit of time used to determine how long DNS lookups are disabled for after exceeding maxAcceptableDNSLookupTime.
There are two options:
minutesseconds
Mandatory: No
Default: minutes
operatingEnvironment > var Copied
List of user environment variable definitions. See the section Environment Configuration for details on how to configure environment variables.
operatingEnvironment > debug Copied
A list of gateway debug settings. These should only be used to diagnose issues with gateway operation. Please contact ITRS support for assistance with these options.
These settings are only intended for debugging error conditions and should be enabled with care. Use of these setting is likely to adversely impact the performance of the Gateway and should only be enabled when debugging a particular configuration and in coordination with ITRS support staff.
Load monitoring statistical output Copied
operatingEnvironment > writeStatsToFile Copied
The “write stats to file” section contains settings controlling how load monitoring statistics are written out from the gateway. These statistics can then be read by the Gateway Load Monitoring plugin. Also see the Gateway Performance Tuning for more information.
Mandatory: No
Default: No statistics written.
operatingEnvironment > writeStatsToFile > filename Copied
The file to which statistics will be written.
Mandatory: Yes
operatingEnvironment > writeStatsToFile > enablePeriodicWrite Copied
Specifies whether to write data to file periodically. If not enabled, statistics will only be written when the “write statistics” command is executed.
Mandatory: No
Default: true
operatingEnvironment > writeStatsToFile > writeInterval Copied
The interval in seconds, at which statistics will be written to file if periodic writes are enabled.
Mandatory: Yes
Default: 20 seconds
Data Quality Options Copied
The settings in this section control the data quality algorithm that gateways use to maintain a consistent level of service under excessive load. This algorithm runs throughout the lifetime of a gateway (unless disableChecks is set) and operates as follows:
- A gateway monitors dataview updates to determine if the oldest pending update becomes stale (as controlled by the maxDataAgeMs setting). If this occurs, a probe connection will be dropped to reduce the gateway’s load and restore timely data processing.
- The gateway determines which connection to drop based upon CPU usage, processing the incoming data, over the last minute. The connection with the highest load is then suspended for a period (see the connectionSuspensionDuration setting) before the gateway reconnects.
- Once a connection has been suspended, no further suspensions will occur until a grace period (see the suspendGracePeriod setting) has elapsed, allowing time to evaluate the effect of the suspension on the quality of the data.
- Setup changes represent a special case where the data age metrics may spike in the gateway. During setup application no incoming data from netprobes is processed, leading to a backlog of updates to be applied. To avoid unnecessary netprobe suspensions, the algorithm is disabled during setup changes and for suspendGracePeriod seconds afterwards.
Probes suspension may additionally be controlled by the “suspend probe” and “unsuspend probe” commands. See the commands appendix for details.
The algorithm is controlled by the settings listed below.
operatingEnvironment > dataQueues > disableChecks Copied
Enable this setting to disable the data quality checking algorithm.
Mandatory: No
Default: false (algorithm is run)
operatingEnvironment > dataQueues > maxDataAgeMs Copied
This setting specifies the maximum acceptable age in milliseconds for a pending update to a dataview. The limit is inclusive, so an update must be older than the set value to cause a connection to be suspended.
For more details on how this setting is used, see the data quality algorithm description.
Note
The default value is set to approximate the behaviour of Gateway versions prior to the introduction of the data quality feature.
Mandatory: No
Default: 77000 (77 seconds)
operatingEnvironment > dataQueues > connectionSuspensionDuration Copied
This setting specifies the length of time in seconds that a connection (to a Netprobe) will be suspended before the gateway reconnects.
For more details on how this setting is used, see the data quality algorithm description.
Mandatory: No
Default: 300 (5 minutes)
operatingEnvironment > dataQueues > suspendGracePeriod Copied
This setting specifies how long the gateway will wait, after suspending a connection, before allowing further connections to be suspended.
For more details on how this setting is used, see the data quality algorithm description.
Mandatory: No
Default: 60 seconds
Memory Protection Copied
When data-quality is disabled, or in extreme situations when it cannot suspend sufficient probes to prevent the gateway becoming overloaded, the gateway will throttle the reading of TCP data to prevent the backlogged data-queues from unbounded growth. This is necessary but less preferable to a managed data-quality suspension as, if it continues without recovery, netprobe connections will either flow-control or timeout and netprobes will be dropped at random.
There are two threshold levels, a low-priority threshold and a high-priority threshold. When the low-priority threshold is breached the gateway will throttle reads from all importing (netprobe) connections but remain responsive to downstream components such as Active Console. In the very unlikely event that this fails to prevent memory growth and the high-priority threshold is breached, the gateway will throttle reads from all connections and become unresponsive until it recovers.
The low-priority threshold is set by default to 250 MB. This is calculated to be enough to buffer 77-second’s (the default maxDataAge setting) worth of data on a high bandwidth gateway (approximately 30,000 cell updates per second) - in practice it will likely take a substantially longer period. This is in order to give the data-quality algorithm time to step in and save the situation before the threshold is reached.
Note
These thresholds govern memory usage by unprocessed EMF messages only, the gateway memory footprint as a whole is typically far more influenced by other factors and could potentially exceed these thresholds without issue. It is unusual for unprocessed EMF messages to account for more than a few megabytes in a normally operating gateway.
operatingEnvironment > dataQueues > memoryProtection Copied
Allows overriding the default data-queue memory protection settings.
For more details on how this setting is used, see the memory protection description.
Mandatory: No
operatingEnvironment > dataQueues > memoryProtection > lowPriorityThresholdMB Copied
The threshold size (in megabytes) for backlogged EMF messages at which the gateway throttles read-data from low-priority connections. Low priority connections are importing EMF connections (currently netprobe connections only). All other gateway connections continue to operate normally.
For more details on how this setting is used, see the memory protection description.
Mandatory: Yes
Default: 500
operatingEnvironment > dataQueues > memoryProtection > highPriorityThresholdMB Copied
The threshold size (in megabytes) for backlogged EMF messages at which the gateway throttles read-data from all connections. In practice it is very unlikely for even a heavily overloaded gateway to hit this threshold, as the low-priority threshold will have been hit first.
For more details on how this setting is used, see the memory protection description.
Mandatory: Yes
Default: 750
Conflation Copied
Conflation is an optional and less drastic method of coping with an overloaded gateway than a data-quality suspension. When the data-queues (which contain incoming sampler updates from the netprobes) become backlogged due to the gateway being unable to process them as fast as they arrive, conflation allows the gateway to discard out-of-date cell updates and only process and publish the latest cell values.
Because this could potentially result in the gateway discarding important updates, or missing short-lived events, conflation is disabled by default and should only be used with care.
Examples Copied
Rapid Cell Updates Copied
Where the netprobe has published several updates to the same cell before the gateway has processed the first update.
- Update cell from 1 to 2
- Update cell from 2 to 3
- Update cell from 3 to 4
- Update cell from 4 to 5
The gateway will only publish the latest value.
- Update cell from 1 to 5
Updates To A Recently Created Row Copied
Where the netprobe updates values in a recently created row before the gateway has processed the create.
- Create row newRow with three cells: 100,200,300.
- Update first cell in newRow from 100 to 111.
- Update second cell in newRow from 200 to 222.
The gateway will add the row to the dataview with the latest values.
- Create row newRow with three cells: 111,222,300.
Updates To Row That Is Then Removed Copied
Where the netprobe updates values in a row and then removes the row before the gateway has processed the updates.
- Update first cell in row1 from 100 to 111.
- Update second cell in row1 from 200 to 222.
- Remove row row1.
The gateway will discard the updates and only process the row-removal.
- Remove row row1.
Short Lived Rows Copied
Where the netprobe creates a row and then removes it again before the gateway has processed the create.
- Create row newRow with four cells: 100,200,300,400.
- Update first cell in newRow from 100 to 111.
- Remove row newRow.
The gateway will conflate away the update as normal but will not conflate away the entire row.
- Create row newRow with four cells: 111,200,300,400.
- Remove row newRow.
Potential Issues Copied
Conflation can prevent a gateway from becoming overloaded, and ensure that published values are always up-to-date, but there are a number of potential issues which users should be aware of before enabling it.
Lost Spikes Copied
A dataview cell that updates from 32% to 34% to 33% is unlikely to cause issues by having the intermediate update conflated away, but one that updates from 32% to 99% to 33% may miss an important spike.
Similarly a cell that goes from OK to ERROR to OK again, could cause an alert to be missed if conflation is enabled.
This might also affect compute-engine rules that use statistical functions such as maximum or minimum.
The Rate Function Copied
Because the Rate function triggers off the time an update is processed rather than the time it is generated its general performance will likely be improved by conflation.
Note
Spikes in the rate-of-change in a cell may be conflated away.
Database Logging Copied
Cell updates that are discarded by conflation will not be logged.
sampleTime and Copied
logNetprobeSampleTimeForDataItems
If logNetprobeSampleTimeForDataItems is configured, cell updates may be logged with sample-times later than they were produced with. This is because the sample-time is published by the netprobe along with the sample-data and will be conflated to the latest value.
E.g. A series of updates produced at twenty second intervals by the netprobe:
- Update cell1 @ 09:25:02
- Update cell2 @ 09:25:22
- Update cell3 @ 09:25:42
Might be conflated into a single update with the latest sample-time.
- Update cell1, cell2, and cell3 @ 09:25:42
The updates to cell1 and cell2 may be logged with this later sample-time. Similarly, rules that reference the sample-time may only see the later value.
Configuration Copied
operatingEnvironment > conflation Copied
Settings to control conflation of incoming monitoring data.
Mandatory: No
operatingEnvironment > conflation > enabled Copied
Whether or not conflation is enabled. Conflation can significantly aid an overloaded gateway and ensure that that all published data is as up-to-date as possible, but it does so by discarding out-of-date cell updates and should not be enabled is this is unacceptable.
For more details on how this setting is used, see the conflation description.
Mandatory: Yes
operatingEnvironment > conflation > strategy Copied
Specify the strategy for controlling gateway conflation, so that conflation is only enabled when required and no updates are unnecessarily discarded.
Mandatory: Yes
operatingEnvironment > conflation > strategy > maxDataAgeThreshold Copied
Under this strategy the gateway does not enable conflation unless the maximum age of backlogged updates (as displayed by the probeData plugin) exceeds a certain threshold.
Conflation works best when it is preventing stale data from building up rather than clearing large backlogs (not only does it have fewer backlogged messages to process, but it minimises the amount of updates conflated away) and the threshold should not be set too high. An ideal value for the threshold is the minimum sampleInterval used in the setup. For this reason it defaults to the default sampleInterval of twenty seconds.
Mandatory: No
operatingEnvironment > conflation > strategy > maxDataAgeThreshold > threshold Copied
The threshold maxDataAge above which conflation is enabled, in milliseconds. An ideal value for this setting is the minimum sampleInterval used in the setup.
Mandatory: No
Default: 20000
operatingEnvironment > conflation > strategy > alwaysOn Copied
Under this strategy the gateway permanently enables conflation. This strategy will always result in the most up-to-date data being published, but may cause updates to be discarded when it is not strictly necessary to do so and the gateway could have published them all in a timely manner.
Mandatory: No
Directory Configuration Copied
Overview Copied
The monitoring configuration of the gateway is also known as the “directory configuration”. This configuration defines which systems will be monitored and the Netprobes to connect to in order to do this, but does not include any settings to process this data once gathered (e.g. Rules or Actions).
The directory configuration is split across several sections in the setup file, which are combined to form a tree-like structure called directory. This structure represents the structure of the monitoring system, and is broken down into groups of components as listed below. During runtime the directory is populated with data collected by Netprobes, where it is then processed by the Gateway and exported to the visualization layer for viewing by programs such as Active Console.
The component parts of the directory are as follows:
Directory
The directory can be regarded as a gateway, since it holds the monitoring data for an entire gateway.
Probe
A probe represents a single Netprobe process running on a host.
Managed Entity
A managed entity is a logical grouping of samplers on a probe, which is typically used to group monitoring data from a particular system or area of functionality.
Sampler
A sampler represents a sampler running on a Netprobe, which collects and publishes data according to its configuration as specified in the gateway setup file.
Dataview
A dataview is a table containing monitoring data gathered by a sampler. A sampler may produce multiple dataviews containing different types of metrics of a monitored system.
Each component listed above can contain zero or more child components of the following type. So Directory can contain zero or more Probes, each of which can contain zero or more Managed Entities and so on.
The image below shows an example directory
structure, as displayed by the Active Console state
view. In the example the Managed Entity linuxME contains 5 samplers and is
running on the Probe linuxTestProbe. The hardware Sampler is also expanded
so that its single hardware dataview is visible in the
tree.
Prior users of Gateway 1 will notice that the directory structures are similar, but have been expanded to include the probe and sampler component types. This change was made so that it is clearer on which managed entities are being hosted on a particular Netprobe process.
This layout also provides additional scope for customization by allowing sorting and searching for specific hosts or sampler types. Users can also revert to a more traditional view by using the “logical” view mode of the AC State Tree.
Figure 6-1 The State Tree View from Active Console in “physical” mode, showing an example directory structure
Probes Configuration Copied
Basic Configuration Copied
Netprobe connection settings are configured in the
Probes top-level section of the
gateway setup. Configuration consists of a list of
probe definitions, each containing as a minimum the
hostname and port that the gateway should connect to.
Each probe is identified by a user-supplied name,
which must be unique among all other probes to
prevent ambiguity.
Steps to create a new probe using the Gateway Setup Editor are listed below.
- Select the Probes top-level section. If this section does not yet exist, select “Yes” when you are prompted to create the section.
- Select the “New probe” button to create a new probe definition.
- Give the new probe a unique name. This name will be used to reference the probe in the managed entity, and also for configuring rules and database logging.
Note
Names are case sensitive.
- Specifies the hostname that the Netprobe is running on. Gateway will connect to the Netprobe on this machine, send down the sampler setup and receive monitoring data.
- Configure the probe port.
- Optionally specifies the probe port - this should be the Netprobe listen port. If not specified gateway will connect using the default port.
- The default probe port can optionally be configured here. If not specified, gateway will use the default port of 7036.
Once these steps have been completed a new probe will now be available and can be referenced from a managed entity. See the managed entity basic configuration section for more detail on this topic.
Figure 6-2 Gateway Setup Editor - Probes top-level section view
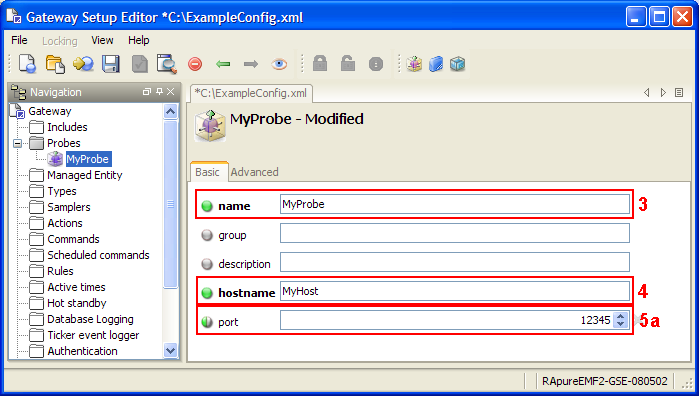
Figure 6-3 Gateway Setup Editor - Basic probe definition view
Virtual Probes Copied
In addition to probes described above, virtual probes can also be configured. These appear in the directory structure as regular probes but do not make a TCP connection to an external Netprobe process. Virtual probes are intended to be used to configure gateway plug-ins and for creating user defined dataviews using compute engine.
Steps to create a new virtual probe using the Gateway Setup Editor are listed below.
- Select the Probes top-level section. If this section does not yet exist, select “Yes” when you are prompted to create the section.
- Select the “New virtual probe” button to create a new probe definition.
- Give the new probe a unique name. This name will be used to reference the probe in the managed entity, and also for configuring rules and database logging. Names must be unique across all virtual and non-virtual probes.
- Virtual probes do not require network configuration parameters.
Floating Probes Copied
In addition to probes described above, floating probes can also be configured. These are exactly the same as regular probes except no TCP connection details are required; instead the netprobe is configured to connect to the gateway when it starts up. This allows probes to be configured to follow monitored application in a cloud computing environment.
Steps to create a new floating probe using the Gateway Setup Editor are listed below.
- Select the Probes top-level section. If this section does not yet exist, select “Yes” when you are prompted to create the section.
- Select the “New floating probe” button to create a new probe definition.
- Give the new probe a unique name. This name will be used to reference the probe in the managed entity, and also for configuring rules and database logging. Names must be unique across all types of probe.
- Floating probes do not require network configuration parameters.
Grouping Copied
Probes can be grouped in the Gateway Setup Editor for ease of management, by means of a probe group. These groups are ignored by gateway and have no effect on the resulting directory structure produced by the setup.
Steps to create a probe group are listed below:
- To create a probe group, right-click on the Probes top-level section and select the “New probeGroup” menu option. This will create a new group section.
- Name the probe group. This can be a descriptive name e.g. “Windows Probes”.
- Add (or remove) probes for the group.
- New probes can be created in the group using the “New probe” button.
- Probes can also be added or removed from the group using drag-and-drop in the Navigation tree.
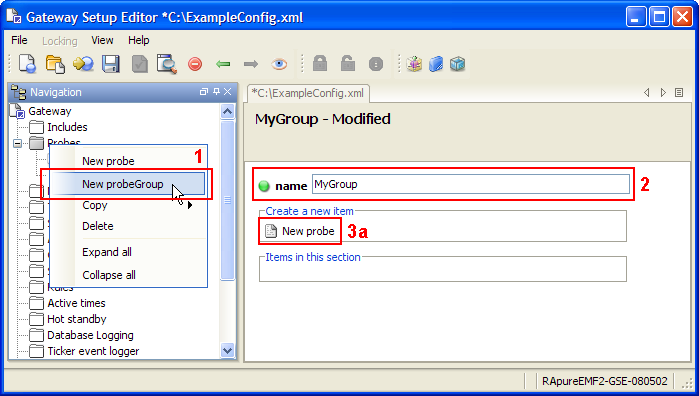
Figure 6-4 Gateway Setup Editor - Probe group definition view
Probe runtime states Copied
The Probe object represents a TCP connection from
the gateway to a netprobe process on a remote
machine. It has a number of runtime states that can
be used if required for alerting which are set as a
runtime parameter "ConState":
| Name | Meaning |
|---|---|
Unknown |
The gateway has just started or the Probe has just been added and the true state has not been established. |
Up |
The gateway is connected to a netprobe process and has sent monitoring configuration. |
Down |
The gateway contacted the configured machine but there is no process running on the specified port. |
Unreachable |
The gateway could not make contact with the specified machine. |
Rejected |
The gateway connected to the netprobe process but this gateway was rejected. When in this state additional runtime parameters "RejectionReason" and "RejectionMessage" will be set to contain the message and reason for rejection. |
Removed |
The probe is set to this state for a short period of time when it is deleted or disabled from the setup. |
Unannounced |
The gateway is waiting for the floating probe to announce itself and provide connection details. |
Suspended |
The probe is set to this state if the probe to gateway connection is suspended |
WaitingForProbe |
The gateway is waiting for the floating probe to connect |
Note
Runtime parameters of data-items can be viewed from the ActiveConsole front end or accessed by rules for alerting.
Configuration Settings Copied
This section describes all configuration settings available in the Probes top-level section.
Navigation pane Copied
The following sections are available from the Gateway Setup Editor navigation tree, after the appropriate definition has been created.
probes Copied
The probes top-level section contains the configuration details of all the probes gateway should connect to and monitor.
probes > probeGroup Copied
A probe group allows grouping of probe definitions for ease of management in the Gateway Setup Editor. A probe group can contain probe definitions or other probe groups.
Probe group settings pane Copied
The following settings are available in the settings pane for a probe group definition.
probes > probeGroup > name Copied
Specifies the name of the probe group. This name is not read by gateway, and can be used for descriptive purposes.
Mandatory: Yes
probes > probe Copied
The definition of a probe that gateway should connect to. The probe must have unique name among all other probe entries in the probes section.
Probes settings pane Copied
The following settings are available in the settings pane for the probes top-level section.
probes > defaultPort Copied
Sets the default port for Netprobes. This must be an integer in the range 1-65535 inclusive.
Mandatory: No
Default: 7036
Probe settings pane - basic Copied
settings
The following settings are available in the settings pane for a probe definition, under the “basic” settings tab.
probes > probe > name Copied
Specifies the name for the probe. This name must be unique among all other configured probes, to avoid ambiguity when the probe is referenced by other part of the gateway setup (e.g. managed entities). The probe name is case-sensitive.
Mandatory: Yes
probes > probe > group Copied
Optionally specifies a group name. See the group metadata section for more details.
Mandatory: No
Default: (no group)
probes > probe > description Copied
Optionally specifies a description. See the description metadata section for more details.
Mandatory: No
Default: (no description)
probes > probe > displayName Copied
Defines a name that is displayed by the Active Console in place of the actual name of the probe in the State Tree view. Other views such as Metrics view are not affected. This name is used for display purposes only - the original name of the probe must be used for all references to the data view (e.g. in rules).
Mandatory: No
Default: (original name of the probe)
probes > probe > hostname Copied
Specifies the hostname (or IP address) of the host that the Netprobe is running on.
Mandatory: Yes
probes > probe > port Copied
The port that the Netprobe is listening on which the gateway should connect to. If not specified, the defaultPort value is used instead.
Mandatory: No
Default: (uses defaultPort value)
probes > probe > secure Copied
Setting this flag indicates that the gateway should connect to the probe using secure protocol. The probe must be have been started using the -secure flag in order for this to work. See Secure Communications for more details.
Mandatory: No
Default: (false)
probes > probe > timezone Copied
The timezone in which the probe is running. If this is not set the probe is assumed to be running in the same timezone as the Gateway. Currently this is primarily used by publishing to convert the published date/times to UTC in ISO 8601 format.
Mandatory: No
Default: Uses the same timezone as the Gateway.
Probe settings pane - advanced Copied
settings
The following settings are available settings pane for a probe definition, under the “advanced” settings tab.
probes > probe > encodedPassword Copied
A password encoded using the UNIX crypt
command-line utility, which is then requested when
users attempt to execute a Netprobe command. The
password can only be configured on the Netprobe by
gateway when the ALLOW\_ENCODED\_PASSWORD\_DOWNLOAD
Netprobe environment variable has been set.
Mandatory: No
Default: (no password - disables commands)
probes > probe > permissions Copied
Permission settings controlling which RMS commands can be executed on this Netprobe.
Mandatory: No
Default: (no permissions)
probes > probe > permissions > RMSGET Copied
Boolean value controlling the RMS GET command. True means that this command can be executed and false means it cannot.
This permission is only applied when running the RMS GET command to obtain files from outside of the probe directory. No permission is required to use RMS GET to obtain a file that is located from inside the netprobe directory.
Mandatory: No
Default: false
probes > probe > permissions > RMSPUT Copied
Boolean value controlling the RMS PUT command. True means that this command can be executed and false means it cannot.
This permission is only applied when running the RMS PUT command to place files outside of the probe directory. No permission is required to use RMS PUT to place a file inside the netprobe directory.
Mandatory: No
Default: false
probes > probe > permissions > RMSEXEC Copied
Boolean value controlling the RMS EXEC command. True means that this command can be executed and false means it cannot.
Mandatory: No
Default: false
probes > probe > trustedAPIHosts Copied
Specifies an optional list of hostnames which are permitted to the API plug-in on this Netprobe. If specified, hosts not in this list will be rejected. See the API plug-in documentation for more details.
Mandatory: No
Default: (if unspecified, all hosts can connect to the API plug-in)
probes > probe > maxLogFileSize Copied
The maximum file size of the Netprobe log file in megabytes. This must be an integer in the range 1-4096 inclusive. Once this size is exceeded the current log file is archived and a new empty log is created.
Mandatory: No
Default: (uses value as set on Netprobe, which is typically 10 MB)
probes > probe > processListCommand Copied
A probe-wide setting which affects all PROCESSES plug-ins for legacy Netprobes. This setting specifies a command to obtain process details for a legacy Netprobe.
Mandatory: No
Default: ps -ef (varies according to target operating system)
probes > probe > wideProcessListCommand Copied
A probe-wide setting which affects all PROCESSES plug-ins running on a Solaris Netprobe. This setting specifies the command to obtain the full process name for processes with names longer than 75 characters.
Mandatory: No
Default: /usr/ucb/ps -axww
probes > probe > cacheProcessNames Copied
A Boolean value specifying whether to cache process names on Linux. Set to false if process names can change during execution.
Mandatory: No
Default: true
probes > probe > heartbeatInterval Copied
Similar to the gateway heartbeatInterval setting, this setting is sent down to the Netprobe and controls Netprobe behaviour. The valid range for the heartbeat interval is 20-300 seconds inclusive.
Mandatory: No
Default: 70
probes > probe > connectWait Copied
Similar to the gateway connectWait setting, this setting is sent down to the Netprobe and controls Netprobe behaviour.
Mandatory: No
Default: 15
probes > probe > maxDatabaseConnections Copied
This sets the maximum amount of connections that a netprobe can make to any database e.g. if managed entity 1 belonging to probe 1 uses 3 SQL-TOOLKIT plug-ins, 1 Sybase plug-in and 1 Oracle plug-in and managed entity 2 belonging to probe 1 uses the same they will have used 10 database connections in total. If probe is using the default value this means no more database connections could be made.
Mandatory: No
Default: 10
probes > probe > disableSelfAnnounce Copied
A Boolean value specifying whether the Netprobe self-announcing feature should be disabled. If clicked and unticked, the Netprobe will self-announce itself. By default, Netprobe does not self-announce itself.
Mandatory: No
Default: true
probes > probe > casesensitiveFilename Copied
A probe-specific boolean switch indicating whether filename matching in Unix based operating systems is case insensitive. This setting will affect the way probe detects files for monitoring. When checked, the latest among the case-insensitive filename matches will be selected, regardless of the existence of a file that matches the exact case of the configured filename.
Once turned ON, the processing of filenames for the following plugins will be affected:
- FTM
- FKM
- Fidessa
- GL SLC
- GL SLC Relay
- GL SLE
- Sets SLC
- IX-MA
- GL Greffon
- Trading Technologies
Mandatory: No
Default: false
probes > probe > commandTimeOut Copied
This sets the maximum time (in seconds) the netprobe waits for a user command to finish before it resumes and continues sampling.
Mandatory: No
Default: 30
probes > probe > fkmLockFilePath Copied
A probe-wide setting which affects all FKM plug-ins running on a netprobe. This sets the path where FKM plug-ins would look for sampler and netprobe lock files to check if FKM sampling on a sampler or an entire probe should be suspended. The default path is the current working directory of the netprobe. The setting does not apply to single lock files used to suspend FKM sampling on individual files.
Mandatory: No
Default: .
probes > probe > maxToolkitProcesses Copied
A probe-wide setting which affects all toolkit plug-ins running on a netprobe. Each toolkit spawns a thread that executes the specified script. This setting controls the maximum number of toolkit threads that can execute at the same time.
Setting the value to 1 executes the toolkit threads one-by-one. This means that the netprobe will wait until the first toolkit script is finished or timed-out before executing the next script.
Setting the value to a value greater than 1 allows the netprobe to execute a number of toolkit scripts in parallel depending on the value set by the user in this setting. If the user has X toolkits, and set Y as the max toolkit processes, Y toolkits would be executed in parallel, while (X - Y) toolkits would be executed one-by-one.
Minimum value is set to 1, while the maximum value is set to 32768.
Mandatory: No
Default: 1
probes > probe > pluginConnectionsToApplications > connectionFailureThreshold Copied
A probe-wide setting which manages how a connection back off strategy for a probe’s plugins will behave (if applicable). This setting is a positive integer indicating the number of connection failures that will be allowed before going initiating a back off. The actual behaviour for the back off may vary, depending on the type of plugin. If this isn’t set or set to zero, back off will be disabled.
Currently, a connection failure back off strategy has been implemented for the following plugins:
- mq-queue
- mq-qdetails
- mq-qoverview
- mq-qinfo
- mq-channel
- mq-cdetails
- mq-coverview
Refer to reference guides for the above plugins for more details.
Mandatory: No
Default: 0
probes > probe > pluginConnectionsToApplications > connectionFailureStopTime Copied
A probe-wide setting which manages how a connection back off strategy for a probe’s plugins will behave (if applicable). This setting is a positive integer indicating the number of seconds to back off from attempting new connections when the connection failure threshold has been reached. The actual behaviour for the back off may vary, depending on the type of plugin. If this isn’t set or set to zero, back off will be disabled.
Mandatory: No
Default: 0
Virtual probe settings Copied
The following settings are available in the settings pane for a virtual probe definition, under the “basic” settings tab.
probes > virtualProbe Copied
The definition of a virtual probe that will exist on this gateway.
probes > virtualProbe > name Copied
Specifies the name for the virtual probe. This name must be unique among all other configured probes and virtual probes, to avoid ambiguity when the probe is referenced by other part of the gateway setup (e.g. managed entities). The probe name is case-sensitive.
Mandatory: Yes
probes > virtualProbe > group Copied
Optionally specifies a group name. See the group metadata section for more details.
Mandatory: No
Default: (no group)
probes > virtualProbe > description Copied
Optionally specifies a description. See the description metadata section for more details.
Mandatory: No
Default: (no description)
probes > virtualProbe > displayName Copied
Defines a name that is displayed by the Active Console in place of the actual name of the probe in the State Tree view. Other views such as Metrics view are not affected. This name is used for display purposes only - the original name of the probe must be used for all references to the data view (e.g. in rules).
Mandatory: No
Default: (original name of the probe)
Floating Probe settings pane - basic Copied
settings
The following settings are available in the settings pane for a probe definition, under the “basic” settings tab.
probes > floatingProbe > name Copied
Specifies the name for the floating probe. This name must be unique among all other configured probes, to avoid ambiguity when the probe is referenced by other part of the gateway setup (e.g. managed entities). The probe name is case-sensitive.
Mandatory: Yes
probes > floatingProbe > group Copied
Optionally specifies a group name. See the group metadata section for more details.
Mandatory: No
Default: (no group)
probes > floatingProbe > description Copied
Optionally specifies a description. See the description metadata section for more details.
Mandatory: No
Default: (no description)
probes > floatingProbe > displayName Copied
Defines a name that is displayed by the Active Console in place of the actual name of the probe in the State Tree view. Other views such as Metrics view are not affected. This name is used for display purposes only - the original name of the probe must be used for all references to the data view (e.g. in rules).
Mandatory: No
Default: (original name of the probe)
Floating Probe settings pane - advanced Copied
settings
The following settings are available settings pane for a probe definition, under the “advanced” settings tab.
probes > floatingProbe > encodedPassword Copied
A password encoded using the UNIX crypt
command-line utility, which is then requested when
users attempt to execute a Netprobe command. The
password can only be configured on the Netprobe by
gateway when the ALLOW\_ENCODED\_PASSWORD\_DOWNLOAD
Netprobe environment variable has been set.
Mandatory: No
Default: (no password - disables commands)
probes > floatingProbe > permissions Copied
Permission settings controlling which RMS commands can be executed on this Netprobe.
Mandatory: No
Default: (no permissions)
probes > floatingProbe > permissions > RMSGET Copied
Boolean value controlling the RMS GET command. True means that this command can be executed and false means it cannot.
This permission is only applied when running the RMS GET command to obtain files from outside of the probe directory. No permission is required to use RMS GET to obtain a file that is located from inside the netprobe directory.
Mandatory: No
Default: false
probes > floatingProbe > permissions > RMSPUT Copied
Boolean value controlling the RMS PUT command. True means that this command can be executed and false means it cannot.
This permission is only applied when running the RMS PUT command to place files outside of the probe directory. No permission is required to use RMS PUT to place a file inside the netprobe directory.
Mandatory: No
Default: false
probes > floatingProbe > permissions > RMSEXEC Copied
Boolean value controlling the RMS EXEC command. True means that this command can be executed and false means it cannot.
Mandatory: No
Default: false
probes > floatingProbe > trustedAPIHosts Copied
Specifies an optional list of hostnames which are permitted to the API plug-in on this Netprobe. If specified, hosts not in this list will be rejected. See the API plug-in documentation for more details.
Mandatory: No
Default: (if unspecified, all hosts can connect to the API plug-in)
probes > floatingProbe > maxLogFileSize Copied
The maximum file size of the Netprobe log file in megabytes. This must be an integer in the range 1-4096 inclusive. Once this size is exceeded the current log file is archived and a new empty log is created.
Mandatory: No
Default: (uses value as set on Netprobe, which is typically 10 MB)
probes > floatingProbe > processListCommand Copied
A probe-wide setting which affects all PROCESSES plug-ins for legacy Netprobes. This setting specifies a command to obtain process details for a legacy Netprobe.
Mandatory: No
Default: ps -ef (varies according to target operating system)
probes > floatingProbe > wideProcessListCommand Copied
A probe-wide setting which affects all PROCESSES plug-ins running on a Solaris Netprobe. This setting specifies the command to obtain the full process name for processes with names longer than 75 characters.
Mandatory: No
Default: /usr/ucb/ps -axww
probes > floatingProbe > cacheProcessNames Copied
A Boolean value specifying whether to cache
process names on Linux. Set to false if process names can
change during execution.
Mandatory: No
Default: true
probes > floatingProbe > heartbeatInterval Copied
Similar to the gateway heartbeatInterval setting, this setting is sent down to the Netprobe and controls Netprobe behaviour. The minimum is 20.
Mandatory: No
Default: 70
probes > floatingProbe > connectWait Copied
Similar to the gateway connectWait setting, this setting is sent down to the Netprobe and controls Netprobe behaviour.
Mandatory: No
Default: 15
probes > floatingProbe > maxDatabaseConnections Copied
This sets the maximum amount of connections that a netprobe can make to any database e.g. if managed entity 1 belonging to probe 1 uses 3 SQL-TOOLKIT plug-ins, 1 Sybase plug-in and 1 Oracle plug-in and managed entity 2 belonging to probe 1 uses the same they will have used 10 database connections in total. If probe is using the default value this means no more database connections could be made.
Mandatory: No
Default: 10
Managed Entities Configuration Copied
Basic Configuration Copied
Managed Entities are configured in the
ManagedEntities top-level section of the
gateway setup. Configuration consists of a set of
managed entity definitions, each of which contains
the configuration for that entity. Each managed
entity must be named using a name unique among all
other managed entities, so that they can be
referenced by this name.
The minimum configuration for a managed entity consists of the probe that the entity will run on, and a list of samplers which will be run. The probe and samplers are specified by referencing the probe or sampler definition by name. It is a checked error to specify a probe which does not exist.
Multiple samplers can be specified in the sampler list, but specifying the same sampler multiple times in a managed entity definition will generate a warning. When using the same sampler the sampler configuration will be the same for each of the samplers run, and therefore the systems monitored will also be the same - it would be unnecessary to monitor the same system repeatedly.
Steps to create a new managed entity using the Gateway Setup Editor are listed below. These steps assume that a probe and sampler definition exist to reference in the managed entity. Please see the probe or sampler basic configuration sections for more details on how to do this.
- Select the Managed Entities top-level section. If this section does not yet exist, select “Yes” when you are prompted to create the section.
- Select the “New managedEntity” button to create a new entity definition.
- Give the new managed entity a unique name. This name will be used to refer to the managed entity in other parts of the gateway, such as rules.
Note
Names are case sensitive.
- Specify the probe that this entity will be hosted on. The drop-down combo list will contain the names of all other probes which have been configured, allowing for easy selection.
- To configure the list of samplers, click on the “Samplers” tab at the top of the settings pane.
- If the sampler list has not previously been specified, enable it by clicking on this button. Samplers can be added or removed by using the plus (+) and minus (-) buttons to the left of the list.
- The drop-down combo list will contain the names of samplers which have been configured, allowing for easy selection.
Once these steps have been completed a new managed entity will have been configured on a probe, with zero or more samplers. This will now appear in Active Console, and provided the specified Netprobe is running can be examined for monitoring data.
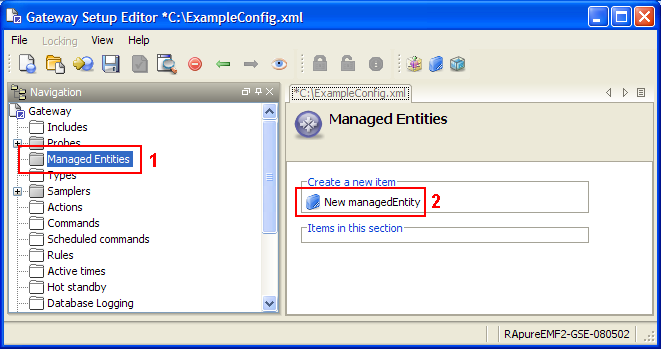
Figure 6-5 Gateway Setup Editor - Managed Entities top-level section view
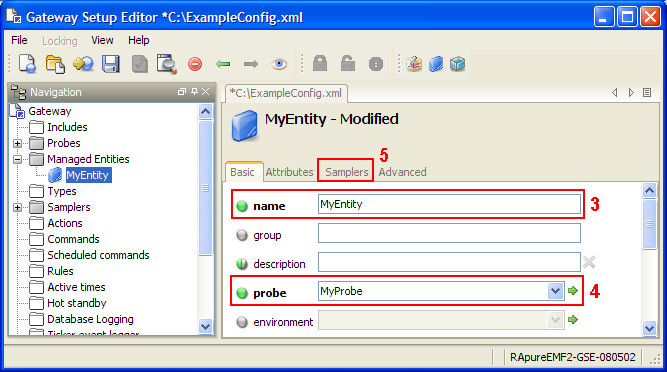
Figure 6-6 Gateway Setup Editor - Basic managed entity definition view
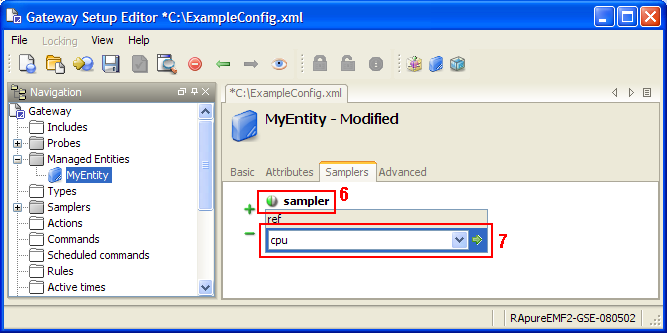
Figure 6-7 Gateway Setup Editor - Samplers managed entity definition view
Types Copied
Typically it is useful to use the same list of samplers across several managed entities. This can be done by using a type, which is essentially a list of samplers (see the types section below). Types are referenced in a managed entity definition in a similar way to probes and samplers. As for the sampler list, a warning is generated if the same type is referenced multiple times.
Types can be added to an entity by referencing the type in the addTypes setting. When types are added, they can contain an additional reference to an environment (see the environments section below for more detail). Samplers referenced from these types will then resolve variables by looking in the specified environment first.
Types inherited from a containing managed entity group can be removed by referencing the type in the removeTypes setting. The removeTypes setting is processed before the addTypes setting, so that it is possible to remove a type and then add it back again using a different environment.
An example screenshot showing both added and removed types is shown below.
Figure 6-8 Gateway Setup Editor - Basic managed entity definition view showing added and removed types
Attributes Copied
Managed entities can optionally contain a number of user configured name-value pairs called attributes. These attributes can be used for naming or grouping managed entities for use by other gateway features. They can also be used by ActiveConsole 2 for searching and sorting purposes. Attributes are typically used with the logical mode of the ActiveConsole 2 state tree, which Gateway 1 / ActiveConsole 1 users may recognize.
Attributes are configured as a list of values similar to the list of samplers. Attributes are inherited from a containing managed entity group, and can be overridden by specifying a new attribute value in the managed entity definition. It is a checked error to configure multiple attributes with the same name in a single managed entity definition.
Figure 6-9 Gateway Setup Editor - Attributes managed entity definition view
Figure 6-10 Example showing managed entity configuration with attributes. On the left is the navigation tree from Gateway Setup Editor, showing the attributes configured on the managed entity groups. On the right is an Active Console state tree, configured in logical mode using the view path “Country, City”.
Managed Entity Groups Copied
Managed entity groups allow a set of managed entities to be grouped in the gateway setup. These groupings can be used simply to provide a more structured view in the Gateway Setup Editor, but they can also be used to simplify the configuration of managed entities.
As stated previously above, a managed entity group
can contain definitions for types and attributes.
These are then inherited by any child groups or
entity definitions. Types can be removed by using the
removeTypes setting in a group or
entity definition, and attributes can be overridden
by specifying a new value.
Steps to create a managed entity group are listed below:
- To create a managed entity group right-click on the Managed Entities top-level section and select the “New managedEntityGroup” menu option. This will create a new group section.
- Name the managed entity group. This can be a descriptive name e.g. “PATS systems”.
- Optionally add or remove types to the group.
- Attributes for the group can be configured in the attributes section, accessible from the “Attributes” tab at the top of the settings pane.
- Add (or remove) managed entities for the group.
- New managed entities can be created in the group using the “New managedEntity” button.
- Entities can also be added or removed from the group using drag-and-drop in the Navigation tree.
- Add (or remove) child managed entity groups.
- Child groups can be added by right-clicking on the group in the Navigation tree and selecting the “New managedEntityGroup” menu option.
- As for managed entities, groups can also be added and removed using drag-and drop in the Navigation tree.
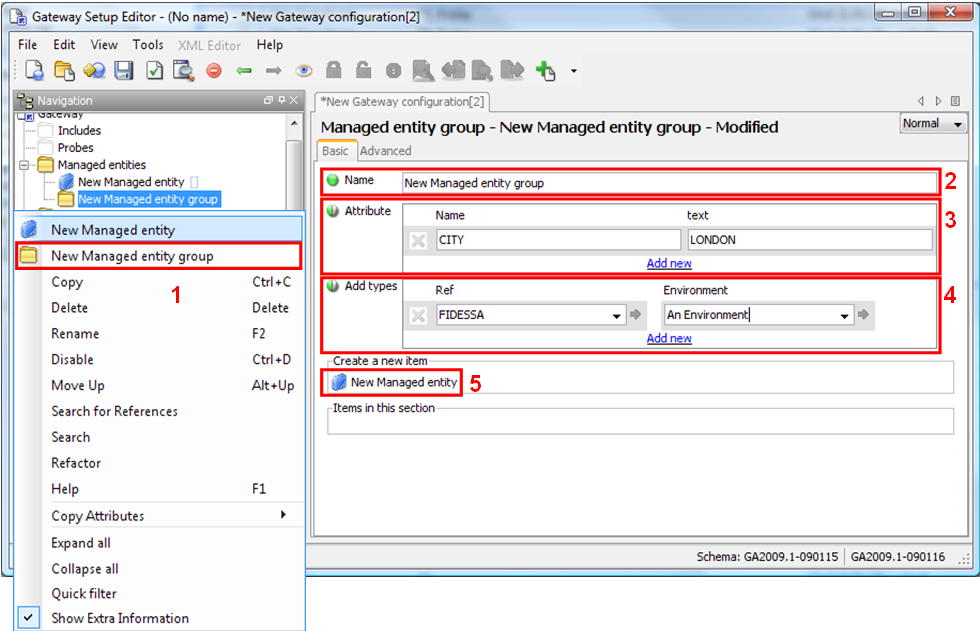
Figure 6-11 Gateway Setup Editor - Managed entity group definition view
The screenshot below shows the Gateway Setup Editor navigation tree for an example configuration. The image has been annotated with the configured attributes, and the resulting attributes that are applied for each managed entity.
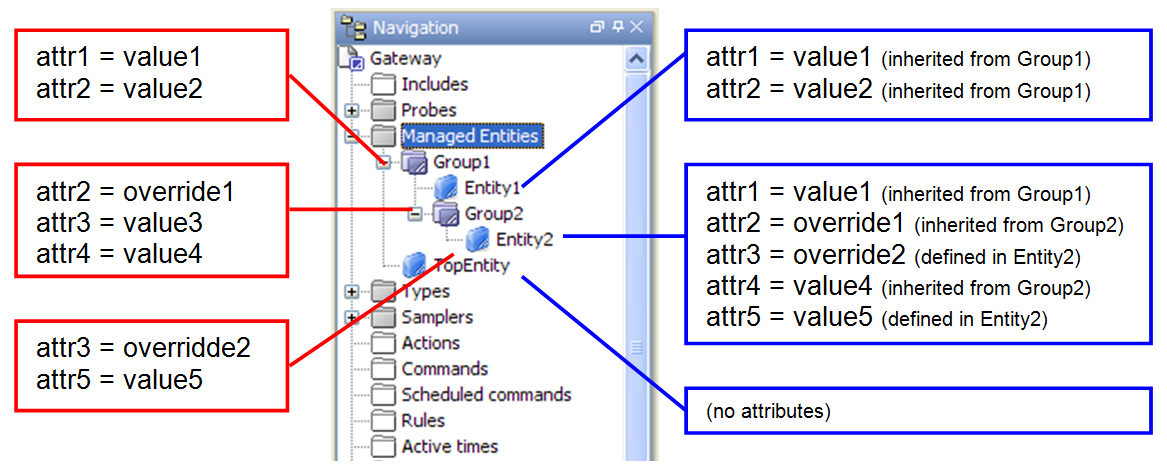
Figure 6-12 Example showing managed entity groups and attributes with inheritance. Values on the left (in red) indicate attributes defined in the gateway setup. The values on the right (in blue) show the resulting attributes for each entity.
Banner Variables Copied
Banner variables allow users to quickly see the value of the most important monitoring metric for a specific managed entity, for example the current CPU load. Each managed entity can be optionally configured with a single banner variable. The value of this variable is displayed as part of the managed entity icon in ActiveConsole 2, and is updated as the variable changes.
To configure a banner variable, enable the banner setting in the advanced entity settings pane and supply the name of the data-item to display in the banner. This name can be either an absolute name or a relative name which starts from the managed entity being configured. For a full explanation of naming please see the naming documentation.
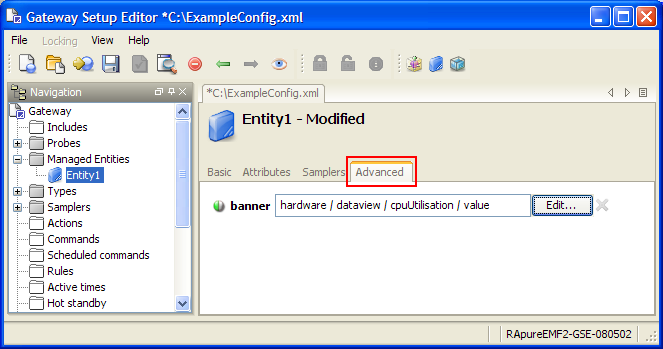
Figure 6-13 Gateway Setup Editor - Advanced managed entity definition view
This produces the following icon in ActiveConsole 2:

Configuration Settings Copied
This section describes all configuration settings available in the Managed Entities top-level section.
Navigation pane Copied
The following sections are available from the Gateway Setup Editor navigation tree, after the appropriate definition has been created.
managedEntities Copied
The managed entities top-level section contains the configuration details of all the managed entities the gateway will configure and monitor. This section can contain a number of entities and groups.
managedEntities > managedEntityGroup Copied
A managed entity group allows grouping of managed entity definitions for ease of management.
Groups can contain both managed entities, and other groups. Contained items inherit any types or attributes specified in the group, which allows an entity to be quickly configured by being placed within the appropriate group.
managedEntities > managedEntity Copied
Contains the definition for a single managed entity. Each entity must have a unique name among all other managed entity definitions in this section.
Managed Entity settings pane Copied
The following settings are available in the settings pane for a Managed Entity definition.
managedEntities > managedEntity > name Copied
Specifies the name for the managed entity. This name must be unique among all other configured entities, to avoid ambiguity when using the name in other parts of the gateway setup (e.g. rules). The managed entity name is case sensitive.
Mandatory: Yes
managedEntities > managedEntity > group Copied
Optionally specifies a group name. See the group metadata section for more details.
Mandatory: No
Default: (no group)
managedEntities > managedEntity > description Copied
Optionally specifies a description. See the description metadata section for more details.
Mandatory: No
Default: (no description)
managedEntities > managedEntity > displayName Copied
Defines a name that is displayed by the Active Console in place of the actual name of the managed entity in the State Tree view. Other views such as Metrics view are not affected. This name is used for display purposes only - the original name of the managed entity must be used for all references to the data view (e.g. in rules).
Mandatory: No
Default: (original name of the managed entity)
managedEntities > managedEntity > probe Copied
A named reference to the probe definition. The managed entity will then be hosted on the Netprobe specified by this definition. It is a checked error to specify an invalid probe definition name.
Mandatory: Yes
managedEntities > managedEntity > environment Copied
An optional named reference to an environment. See environment configuration used for resolving variables in the sampler configuration for this entity.
Mandatory: No
managedEntities > managedEntity > attribute Copied
A managed entity definition can contain any number of attributes. Each attribute is specified as a name-value pair containing a textual value (the attribute value). These attributes can then be used for searching and sorting in ActiveConsole 2. See the managed entity attributes section for more details.
Mandatory: No
managedEntities > managedEntity > removeTypes Copied
The remove types setting allows the removal of
inherited types from a managed entity definition.
Types to be removed are listed (referenced) by name
in this setting. removeTypes are processed after
inheritance, but before addTypes
to allow “overriding” of an inherited type.
See the managed entity types section, or the types top-level section for more details.
Mandatory: No
managedEntities > managedEntity > removeSamplers Copied
The remove samplers setting allows the removal of samplers from inherited types from a managed entity definition. Samplers to be removed are listed (referenced) by name and the type they belong to in this setting.
Mandatory: No
managedEntities > managedEntity > addTypes Copied
The add types setting allows types to be added (from the top-level types section of the gateway setup) to a managed entity. Types are referenced by name, and can be linked to an optional environment. See the managed entity types section for more details.
Mandatory: No
managedEntities > managedEntity > addTypes > type > environment Copied
The environment setting allows an optional environment to be linked to a type reference, within a particular managed entity definition. Samplers defined in the type will then use this environment to resolve any variables in the configuration. See the managed entity types section for more details.
Mandatory: No
managedEntities > managedEntity > var Copied
Any number of variable definitions, configured with a name and value similar to attributes. Managed entity variables override the entity environment if specified variables are used when resolving sampler configurations which contain variables. See environment configuration.
Mandatory: No
managedEntities > managedEntity > var> name Copied
The name that is used to identify the variable. The name must be unique within each variable scope.
Mandatory: Yes
managedEntities > managedEntity > var > ipAddress Copied
Specify the IP address of variable in Managed entity. This can be used in sampler configuration where the machine name or IP address is required.
Mandatory: No
managedEntities > managedEntity > var > activeTime Copied
Specifies a variable of type activeTime reference which refers to an active time in the system.
Mandatory: No
managedEntities > managedEntity > var > boolean Copied
Specifies a variable of type Boolean which can take a value of true or false.
Mandatory: No
managedEntities > managedEntity > var > double Copied
Specifies a variable of type double which can take a double precision floating point numerical value.
Mandatory: No
managedEntities > managedEntity > var > externalConfigFile Copied
Specifies a variable which can take the name of an external configuration file.
Mandatory: No
managedEntities > managedEntity > var > integer Copied
Specifies a variable which can take a numerical integer value.
Mandatory: No
managedEntities > managedEntity > var > nameValueList Copied
Specifies a variable which can take a list of name value pairs.
Mandatory: No
managedEntities > managedEntity > var > nameValueList > item Copied
Specifies a single name/value pair in the list.
Mandatory: No
managedEntities > managedEntity > var > nameValueList > item > name Copied
Specifies the name in a single name/value pair in the list.
Mandatory: No
managedEntities > managedEntity > var > nameValueList > item > value Copied
Specifies the value in a single name/value pair in the list.
Mandatory: No
managedEntities > managedEntity > var > regex Copied
Specifies a variable which can take a regular expression.
Mandatory: No
managedEntities > managedEntity > var > string Copied
Specifies a variable which can take a string.
Mandatory: No
managedEntities > managedEntity > var > stringList Copied
Specifies a variable which can take a list of strings.
Mandatory: No
managedEntities > managedEntity > var > stringList > string Copied
Specifies a single string in the string list.
Mandatory: No
managedEntities > managedEntity > var > macro Copied
Specifies a variable that takes the value from the gateway itself. The macros supported are listed in the environment section.
Mandatory: No
managedEntities > managedEntity > sampler Copied
A managed entity definition can contain any number of sampler references, which are run on the host Netprobe for this entity. Each sampler is referenced by name from the samplers top-level section. Samplers referenced multiple times in the same entity definition will produce an error message.
Mandatory: No
managedEntities > managedEntity > samplerInclude Copied
A managed entity definition can contain any number of samplerInclude references. This references a samplerInclude configuration section which will be applied to this ManagedEntity. SamplerInclude sections define parts of sampler configuration that will be combined into a sampler. For example a list of processes that will be added to an instance of a processes sampler.
Mandatory: No
managedEntities > managedEntity > sampler > disabled Copied
Disables the referenced sampler.
Mandatory: No
managedEntities > managedEntity > banner Copied
An optional name specifying the data-item to display as the representative value for this managed entity (see the banner variables section for more details). Names can be specified either as an absolute name, or a relative name starting from the managed entity level.
Mandatory: No
Default: (no banner variable is displayed)
Managed Entity group settings Copied
pane
managedEntities > managedEntityGroup > name Copied
Specifies the name of the managed entity group. Groups names are not read by gateway, and so can be used for descriptive purposes.
Mandatory: Yes
managedEntities > managedEntityGroup > group Copied
Optionally specifies a group name, which will then be inherited by contained managed entities (or groups). See the group metadata section for more details.
Mandatory: No
Default: (no group)
managedEntities > managedEntityGroup > attribute Copied
An entity group definition can contain any number of attributes. Each attribute is specified as a name-value pair containing a textual value (the attribute value). These attributes can then be used for searching and sorting in ActiveConsole 2. See the managed entity attributes section for more details.
Mandatory: No
managedEntities > managedEntityGroup > removeTypes Copied
The remove types setting allows the removal of
inherited types from an entity group definition.
Types to be removed are listed (referenced) by name
in this setting. removeTypes are processed after
inheritance, but before addTypes
to allow “overriding” of an inherited type.
See the managed entity types section, or the types top-level section for more details.
Mandatory: No
managedEntities > managedEntityGroup > removeSamplers Copied
The remove samplers setting allows the removal of samplers from inherited types from a managed entity group definition. Samplers to be removed are listed (referenced) by name and the type they belong to in this setting.
Mandatory: No
managedEntities > managedEntityGroup > addTypes Copied
The add types setting allows types to be added (from the types top-level section of the gateway setup) to an entity group. Types are referenced by name, and can be linked to an optional environment. See the managed entity types section for more details.
Mandatory: No
managedEntities > managedEntityGroup > addTypes > type > environment Copied
The environment setting allows an optional environment to be linked to a type reference, within a particular entity group definition. Samplers defined in the type will then use this environment to resolve any variables in the configuration. See the managed entity types section for more details.
Mandatory: No
managedEntities > managedEntityGroup > var Copied
Any number of variable definitions, configured with a name and value similar to attributes. Entity group variables override the entity environment if specified. Variables are used when resolving sampler configurations which contain variables, see environment configuration.
Mandatory: No
Types Configuration Copied
Types allow managed entities to be configured logically by a shared property, rather than by explicitly adding a list of samplers to every managed entity with that property. A type consists of a list of samplers and optionally environments for user variables. This list of samplers will be added to every managed entity which references the type. Future changes to the sampler list can then be confined to the type definition, rather than editing the definitions for a set of managed entities.
For example a user could configure a set of samplers for monitoring a Linux-based system as a “Linux” type definition. This type can then be referenced by managed entities running on Linux machines (or better, referenced by a managed entity group which contains these entities). Additional Linux machines added later can then reference this type, or extra samplers can be added to the type to extend monitoring of all Linux systems.
Another example might be to monitor servers for a particular trading system, e.g. Fidessa. Samplers to monitor a Fidessa system may be listed in a type “Fidessa”, with system-specific file locations specified using a variable value. Managed entities could then reference the type, with an environment that sets the specific paths used on that system.
Entities can be configured with multiple types by referencing the required types by name. To avoid ambiguity types must be configured with a unique name among all types in the top-level section. A managed entity which references the same type multiple times will only load the samplers for that type once; otherwise the managed entity will run several samplers with the same configuration and perform unnecessary work. Similarly a warning is generated if the same sampler is referenced multiple times within a type.
Configuration Guide Copied
Steps to create a new type using the Gateway Setup Editor are shown below:
- Select the Types top-level section. If this section does not yet exist, select “Yes” when you are prompted to create this section.
- Select the “New type” button to create a new type definition.
- Give the new type a unique name. This name will be used to reference the type in other parts of the gateway setup (primarily managed entities).
Note
Names are case sensitive.
- An optional environment can be specified for the type, which will be used to resolve variables in sampler configurations. See environment configuration.
- Configure the sampler list for this type. Samplers are referenced by name from the Samplers top-level section. Configuring the same sampler multiple times will lead to a validation warning.
- Variables can optionally be configured using this button. A variable configured in the type will override a variable configured in the environment referenced at step 5 (if any).
- Types can be grouped for ease of management in Gateway Setup Editor. To create a new type group, right-click on the Types top-level section and select the “New typeGroup” menu option.
- Specify the name for the new type. Names of groups are not read by gateway and so can be used for descriptive purposes.
- Add types to the type group. New types can be created in the group by selecting the “New type” button. Types can also be added and removed from the group using drag-and-drop in the Navigation tree.
- Type groups can be added and removed from other type groups using drag-and-drop in the Navigation tree. New type-groups can also be added to a group by right-clicking on the group in the tree and selecting the “New typeGroup” menu option.
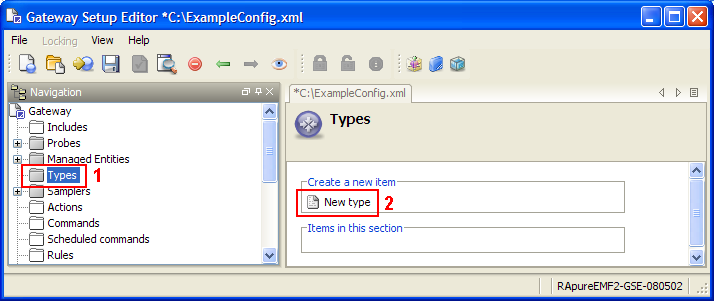
Figure 6-14 Gateway Setup Editor - Types top-level section view
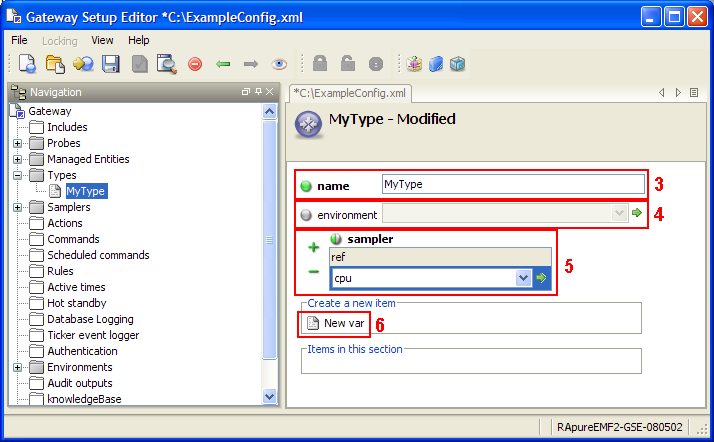
Figure 6-15 Gateway Setup Editor - Type definition view
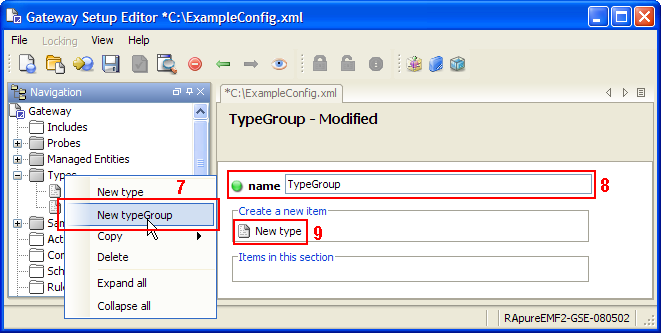
Figure 6-16 Gateway Setup Editor - Type group definition view
Configuration Settings Copied
This section describes all configuration settings available in the Types top-level section.
types Copied
The types top-level section contains the definition of all types in the gateway setup. These types are referenced in managed entities, and are intended to simplify gateway setup configurations by enabling reuse of common lists of samplers.
Mandatory: No
types > type Copied
A type definition specifies a single type. This consists of a list of samplers, an optional environment for variable resolution in sampler configuration, and optional variable declarations for overriding values in the environment.
types > type > name Copied
Specifies the name for the type. This name must be unique among all other configured types, to avoid ambiguity when the type is referenced (for example in a managed entity). The type name is case-sensitive.
Mandatory: Yes
types > type > environment Copied
Optional named reference to an environment see environment configuration used for resolving variables in the samplers referenced in this type.
Mandatory: No
types > type > var Copied
Any number of variable definitions, configured with a name and value. Variables specified here override those in the environment if specified.
Mandatory: No
types > type > var > name Copied
The name that is used to identify the variable. The name must be unique within each variable scope.
Mandatory: Yes
types > type > var > activeTime Copied
Specifies a variable of type activeTime reference which refers to an active time in the system.
Mandatory: No
types > type > var > boolean Copied
Specifies a variable of type Boolean which can take a value of true or false.
Mandatory: No
types > type > var > double Copied
Specifies a variable of type double which can take a double precision floating point numerical value.
Mandatory: No
types > type > var > externalConfigFile Copied
Specifies a variable which can take the name of an external configuration file.
Mandatory: No
types > type > var > integer Copied
Specifies a variable which can take a numerical integer value.
Mandatory: No
types > type > var > nameValueList Copied
Specifies a variable which can take a list of name value pairs.
Mandatory: No
types > type > var > nameValueList > item Copied
Specifies a single name/value pair in the list.
Mandatory: No
types > type > var > nameValueList > item > name Copied
Specifies the name in a single name/value pair in the list.
Mandatory: No
types > type > var > nameValueList > item > value Copied
Specifies the value in a single name/value pair in the list.
Mandatory: No
types > type > var > regex Copied
Specifies a variable which can take a regular expression.
Mandatory: No
types > type > var > string Copied
Specifies a variable which can take a string.
Mandatory: No
types > type > var > stringList Copied
Specifies a variable which can take a list of strings.
Mandatory: No
types > type > var > stringList > string Copied
Specifies a single string in the string list.
Mandatory: No
types > type > var > macro Copied
Specifies a variable that takes the value from the gateway itself. The macros supported are listed in the environment section.
Mandatory: No
types > type > sampler Copied
Any number of named references to samplers. These samplers will be loaded each managed entity which references this type. The same sampler should not be referenced multiple times for in a single type, and will generate a validation warning.
Mandatory: No
types > type > samplerInclude Copied
A type definition can contain any number of samplerInclude references. This references a samplerInclude configuration section which will be applied to all managedEntities of this type. SamplerInclude sections define parts of samplers that will be combined into a sampler. For example a list of processes that will be added to an instance of a processes sampler.
Mandatory: No
types > type > sampler > disabled Copied
Disables the referenced sampler.
Mandatory: No
types > typeGroup Copied
Type groups can be used to group types in the gateway setup. Groups can contain both type definitions and additional type groups.
types > typeGroup > name Copied
Specifies the name of the type group. This name is not used by gateway, and so can be used for descriptive purposes.
Mandatory: Yes
Samplers Configuration Copied
Samplers perform the real work of the Geneos monitoring system. Each Netprobe hosts a set of samplers which are responsible for collecting the monitoring data and forwarding it to gateway for processing. The monitoring configuration for each Netprobe is controlled by gateway, allowing for a centralised management approach. The configuration that is sent to Netprobe is made up largely of samplers defined within this section.
Samplers running on Netprobe typically gather and publish data (sample) every 20 seconds to the rest of the system, the process of which is called regular sampling. The delay between samples is called the sample interval. Additional samples can be prompted by the user, and can also be configured in the sampler definition. These settings are discussed in more detail below.
Basic configuration Copied
The samplers top-level section contains a list of sampler definitions. Each definition must be uniquely named among all other sampler definitions to avoid ambiguity, since samplers are referenced in other parts of the gateway setup (e.g. in types and managed entities) by name.
Steps to create a new sampler using the Gateway Setup Editor are shown below:
- Select the samplers top-level section. If this section does not yet exist, select “Yes” when prompted on whether to create the section.
- Select the “New sampler” button to create a new sampler definition.
- Give the new sampler a unique name. This name will be used to reference the sampler from other parts of the gateway setup.
Note
Names are case-sensitive.
- By default samplers will collect data (sample)
every 20 seconds. You can optionally change that
value here using the
sampleIntervalsetting. - The main sampler configuration is contained under the “Plugin” tab. Here you can select the plug-in to run and configure plug-in specific settings. Please see the specific plug-in documentation for a full description of these configuration settings.
- For the purposes of configuring an example sampler, select the CPU plug-in from the drop-down combo-list. The CPU plug-in does not need any additional configuration in order to run - the default values are sufficient.
Once a sampler has been created, it can then be referenced with a type of managed entity. For an example usage, please see the basic configuration guide for a managed entity.
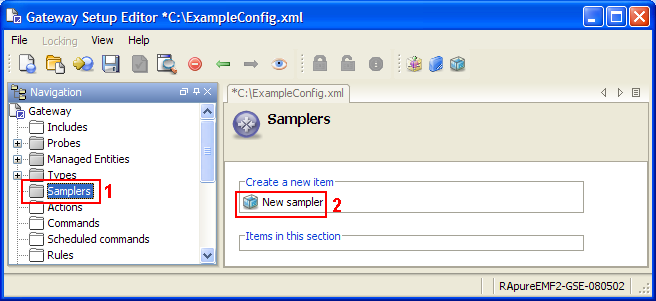
Figure 6-17 Gateway Setup Editor - Samplers top-level section view
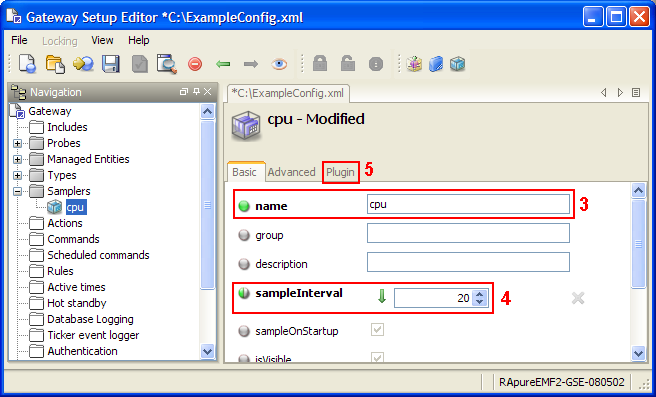
Figure 6-18 Gateway Setup Editor - Sampler definition settings view
Grouping Copied
Samplers can be grouped in the Gateway Setup Editor for ease of management, by means of a sampler group. These groups are ignored by gateway and have no effect on the resulting directory structure produced by the setup.
Steps to create a sampler group are listed below:
- To create a sampler group right-click on the Samplers top-level section and select the “New samplerGroup” menu option. This will create a new group section.
- Specify the name for the sampler group. This name is not read by gateway, and so can be used to describe the contents of the group.
- Add (or remove) samplers from the group by using drag-and-drop in the Navigation pane. New samplers can be created within the group by clicking the “New sampler” button.
- Sampler groups can also contain nested sampler groups. These can be created using the right-click menu in the Navigation pane, and managed using drag-and-drop in the same manner as for sampler definitions.
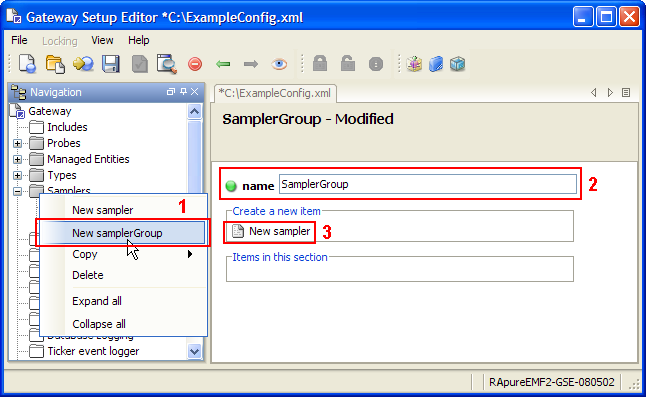
Gateway Setup Editor - Sampler group definition view
Additional Settings Copied
Samplers allow a range of additional settings to more finely control how a plug-in is run. These settings can be applied to any sampler, regardless of the particular plug-in type that the sampler has been configured with. Some of these settings are discussed below.
Sampling Copied
There are several settings to configure in the sampler descriptor, which can control when a sampler collects data (samples). These are described below:
sampleInterval Copied
The sample interval controls how often the sampler checks for changes in monitored data. This value is in seconds, and defaults to 20 seconds. A value of 0 seconds will prevent the sampler from sampling. Users can force a sample using the “sample now” command accessible through ActiveConsole 2, or by configuring another sample control method below.
sampleOnStartup Copied
By default all samplers sample once when the
sampler configuration is sent to NetProbe. Setting
this parameter to false will prevent this
behaviour, which is typically used in conjunction
with a sampleInterval of 0.
sampleTimes Copied
This setting can configure a sampler to sample
at specific times during the day. This is often
used in conjunction with a sampleInterval of 0 to disable
regular sampling. Times are configured as a
comma-delimited list of times in the format HH:MM
using 24-hour clock. These times will cause a
sample regardless of any active times that have
been specified unless sampleTimesOverride is set
false (see below).
sampleTimesOverride Copied
By default sample times will cause a sample regardless of any active times that have been specified. Setting this setting to false will allow the active times to enable and disable the sample times.
fileTrigger Copied
A file trigger is a path to a file accessible by
Netprobe. When the modification time of the file is
updated (e.g. using the UNIX utility touch) it causes the sampler to
sample. This will cause a sample regardless of any
active times that have been specified.
activeTimes Copied
Active times allow users to specify a range or set of times, during which the sampler should be active (i.e. sampling). Outside of these times regular sampling will be disabled (similar to setting sampleInterval to 0). This can be helpful when monitored data is only valid during working hours, for example.
Expect Rows Copied
Expect rows are a mechanism for forcing a row to appear in a dataview. When using “expect rows” an additional column “Availability” is added to the dataview, showing whether an expected row is “present” or “absent”. This allows users to set rules on data which the user expects to be present but is in fact unavailable for some reason.
To use this feature, simply configure the name of each row that is expected to be present using the expectRows setting.
Each individual expect row can be configured using static strings and string variables as shown below;

It is also possible to use a single variable to define all of the expected rows. To do this you must create a stringList variable and set the expect rows setting to var and then select the stringList from the variable dropdown as shown below;

Note
Expect rows works only with Netprobe published dataviews and is not designed to work with Gateway created dataviews using compute engine (when createOnGateway setting is enabled).
An example of the result is shown in Figure 6-20 below.
Figure 6-20 Example TCP-LINKS plug-in with expect rows
Filtering Data Copied
Samplers can optionally be instructed to filter data from the dataview. This filtering is done mostly at a Netprobe level, meaning that the data will not be available for setting of rules. Filtering can also be performed by ActiveConsole 2, if users do not wish to see certain values. For Gateway Plugins, the filtering will be done by the Gateway.
hideColumns Copied
Allows users to specify a list of dataview columns which are then “hidden” by Netprobe. These columns are not transmitted to Gateway for processing, and so cannot be used in rules.
You may use regular expressions to specify the columns. However the expression must match the whole column name. So if you wanted to exclude all columns containing “time” you would need “^.*[Tt]ime.*” as your expression.
hideRows Copied
Similar to hideColumns above, hideRows allows users to specify a list of dataview rows which are then hidden. Once again, these rows are not transmitted to Gateway, and so cannot be used in rules.
You may use regular expressions to specify the rows. However the expression must match the whole row name. So if you wanted to exclude all rows containing “time” you would need “^.*[Tt]ime.*” as your expression.
publish Copied
The publish setting controls whether Netprobe publishes any dataviews for that sampler. If set to false, this dataview will not be published and so any data it contains is not transmitted to Gateway and so will not be usable for rules.
This setting is typically used in conjunction with the COMBO plug-in, which combines multiple dataviews. Since the combined dataview is published (unless publish is set to false on the sampler) this can lead to duplication of data on the Gateway. To avoid this the views which COMBO plug-in are taking as inputs are set to not publish.
isVisible Copied
The isVisible setting controls whether or not a dataview is visible in ActiveConsole. For this setting to take effect the dataview must be published (and so available in Gateway / ActiveConsole).
Legacy Parameters Copied
The legacyParameters setting is used to store additional sampler parameters. These parameters may arise because they have not been converted to the Gateway 2 setup file format yet, or during testing of a new plug-in where the setup format has not been finalised. In this case, parameters can be specified in this section as a name-value pair.
Configuration Settings Copied
This section describes all configuration settings available in the Samplers top-level section.
samplers Copied
The samplers top-level section contains the configuration details of all the samplers which the gateway will use to monitor data.
samplers > samplerGroup Copied
A sampler group allows grouping of sampler definitions for ease of management in the Gateway Setup Editor. A sampler group can contain both a list of sampler definitions, and nested sampler groups.
samplers > samplerGroup > name Copied
Specifies the name of the sampler group. This name is not read by gateway and so can be used as a description of the group.
Mandatory: Yes
samplers > sampler Copied
A sampler definition contains the configuration needed to monitor an aspect of a system. This configuration contains both general settings which can be applied to any sampler and plug-in specific configuration which specifies what to monitor and how to obtain the data.
Sampler settings pane - basic settings Copied
The following settings are available in the settings pane for a sampler definition, under the “basic” settings tab.
samplers > sampler > name Copied
Specifies the name of the sampler. This name is used to reference the sampler from types and managed entities so to avoid ambiguity the sampler name must be unique among all other samplers.
Mandatory: Yes
samplers > sampler > var-group Copied
Optionally specifies a group name. See the group metadata section for more details.
Mandatory: No
Default: (no group)
samplers > sampler > description Copied
Optionally specifies a description. See the description metadata section for more details.
Mandatory: No
Default: (no description)
samplers > sampler > displayName Copied
Defines a name that is displayed by the Active Console instead of the actual name of the sampler in the State Tree view. The Metrics view are not affected. This name is used for display purposes only - the original name of the sampler must be used for all references to the data view (for example in rules).
Note
This setting only affects the name of the sampler, and not any of its dataviews. To change the display name of a dataview in the state tree, see samplers > sampler > dataviews > dataview > displayName.
Mandatory: No
Default: (original name of the sampler)
samplers > sampler > sampleInterval Copied
An optional setting controlling the period between two samples taken by the sampler, measured in seconds. The value should be set to a non-negative integer value. A value of 0 indicates that regular sampling should be disabled.
Mandatory: No
Default: 20 (seconds)
samplers > sampler > plugin Copied
Optionally specifies a plugin to be associated with this sampler.
Mandatory: No
samplers > sampler > sampleOnStartup Copied
An optional setting which controls whether the
sampler should perform an initial sample on
start‑up, when the gateway sends down the sampler
configuration to netprobe. This is a Boolean
setting so takes values true or false. A value of false is only effective in
conjunction with a sampleInterval
set to 0.
Mandatory: No
Default: true
samplers > sampler > isVisible Copied
This setting controls whether the dataview is visible in ActiveConsole, and only applies if the dataview is actually published.
Mandatory: No
Default: true
samplers > sampler > publish Copied
This setting controls whether the dataview is
published to gateway by netprobe. A dataview which
is not published will not present in Gateway or
ActiveConsole 2 and cannot have rules set on it.
This is a Boolean setting so takes values
true or false. A value of false is typically used when
the view is an input to COMBO plug-in - the data
contained in the non-published view will be
published in the COMBO plug-in instead.
Mandatory: No
Default: true
samplers > sampler > fileTrigger Copied
File triggers allows external control of a sampler. Netprobe will monitor all configured files for a change in modification time. When a change is detected, the sampler will sample. This setting is typically used when regular sampling has been disabled.
Mandatory: No
samplers > sampler > fileTrigger > filename Copied
Specifies the file to monitor for a file trigger.
Mandatory: Yes (if using a file trigger)
samplers > sampler > fileTrigger > maxPerMinute Copied
Specifies the maximum number of times that a file trigger can be triggered per minute. The value must be a positive integer (greater than 0).
Mandatory: No
Default: 5
samplers > sampler > expectRows Copied
This setting allows the configuration of expect rows for a sampler. This setting should only be used for samplers which produce a single dataview. For a more detailed description see the expect rows section above.
samplers > sampler > expectRows > data > expectRow Copied
Specifies the name of the row to be expected.
samplers > sampler > expectRowsInitialDelay Copied
The initial delay specifies a time in seconds from when the sampler is first started, until the expect rows are applied. This is necessary for some samplers which must connect to an external data source before producing data (e.g. RMC plug-in). The value must be a positive integer (greater than 0).
Mandatory: No
Default: (no initial delay)
Sampler Settings Pane - Advanced Settings Copied
The following settings are available in the settings pane for a sampler definition, under the “advanced” settings tab.
samplers > sampler > sampleTimesOverride Copied
If this setting is enabled, the sampler will sample for any sampleTimes that have been specified, regardless of any active times that have been specified.
If disabled (set to false), a sampler which is inactive due to active times will not sample for any sample times that fall within the inactive period.
Mandatory: No
Default: true
samplers > sampler > sampleTimes Copied
This setting specifies a list of times at which the sampler should perform a sample. The times specified in this list are taken as local times on the Netprobe host. This list is typically used when regular sampling is disabled by setting SampleInterval to 0 and SampleOnStartUp to false, and is processed regardless of any active times.
Mandatory: No
samplers > sampler > sampleTimes > time Copied
Specifies the time of day at which the sampler should sample. The format should be HH:MM using 24-hour clock, given in the local time of the Netprobe host.
Mandatory: Yes
samplers > sampler > var-hideColumns Copied
Specifies a list of dataview columns to hide. See the section on filtering data above for more details.
Mandatory: No
samplers > sampler > var-hideRows Copied
Specifies a list of dataview rows to hide. See the section on filtering data above for more details.
Mandatory: No
samplers > sampler > activeTimes Copied
Specifies a list of active times, during which the sampler should perform regular sampling. Outside of these times regular sampling will not be performed, but sampleTimes will still be processed. Active times are referenced by name.
Note
Active times can be Netprobe controlled or Gateway controlled (if gatewayControlledProbeActiveTimes is set). In the latter case, one cannot use timezones or seconds precision in active times. For further details, refer to gatewayControlledProbeActiveTimes.
Mandatory: No
samplers > sampler > legacyParameters Copied
This section allows legacy sampler parameters to be specified. See the legacy parameters section above for more details. Parameters are specified as name-value pairs, and parameter names must be unique.
Mandatory: No
Dataviews Copied
Samplers can also contain additional configuration for the dataviews they produce. This is placed in the samplers section rather than a top-level dataviews section because the dataview name alone does not make it unique in the setup. Several samplers may produce dataviews with the same names, and some plug-ins even generate dataview names based on information read from a log file.
To configure dataview settings the dataview must be referenced by name. To use this functionality, it is recommended that users configure and run a plug-in first, and then copy the name using the ActiveConsole 2 copy name command. Settings which can be used to configure dataview behaviour are described briefly below.
Expect rows Copied
Expect rows for dataviews work in exactly the same
way as for sampler expect
rows. They can be configured on a dataview
to allow users to apply expect rows to a specific
view, in the case where a sampler produces multiple
views. Expect rows are configured using the
expectRows setting.
Metadata Copied
Some items of metadata can be set on a dataview, namely the group and an overviewType. The group name can optionally be used for grouping dataviews in the ActiveConsole 2 metrics view, in addition to searching and sorting functions.
The overview type is used when creating combining several dataviews into a single metrics view. This functionality is known as a metrics overview (or dynamic overview in ActiveConsole 1). By default, views are combined using the plug-in name. This is sufficient for most plug-ins, but for views created using the TOOLKIT plug-in for example the data within the view may not be the same for all TOOLKIT samplers. Setting the overview type in these instances will allow ActiveConsole 2 to match dataviews according to their user‑specified type, producing a better metrics overview.
Additional data Copied
Gateway 2 can optionally create additional data inside a dataview. This includes extra headlines, columns and also rows. These extra cells are initially empty when created, and are typically used to provide extra metrics for a dataview which are then populated using the Compute Engine functionality see compute engine.
When creating this additional data, users have the choice of whether to create a completely new dataview on the gateway, or to augment an existing dataview coming from Netprobe. This choice is controlled by the createOnGateway setting.
Configuration Settings Copied
The configuration settings for dataviews are stored within the definition of the sampler which produces the configured dataview(s). The available settings are listed below.
samplers > sampler > dataviews Copied
The dataviews setting within a sampler definition contains all the configuration settings to control the behaviour of dataviews produced by that sampler.
Mandatory: No
samplers > sampler > dataviews > dataview > name Copied
Specifies the name of the dataview the contained configuration settings should apply to. This name is best obtained by first running the sampler, and copying the name of the views produced from within ActiveConsole 2.
Mandatory: Yes
samplers > sampler > dataviews > dataview > description Copied
Specifies a description of what the dataview displays. This would typically be used with the createOnGateway setting.
Mandatory: No
samplers > sampler > dataviews > dataview > displayName Copied
Defines a name that is displayed by the Active Console in place of the default name of the data view. Other views such as Metrics view are not affected. This name is used for display purposes only - the original name of the data view must be used for all references to the data view (e.g. in rules).
Mandatory: No
Default: (original name of the data view)
samplers > sampler > dataviews > dataview > expectRows Copied
This setting allows the configuration of expect rows for a dataview. For a more detailed description see the expect rows section for samplers above.
Mandatory: No
samplers > sampler > dataviews > dataview > expectRowsVar Copied
This setting allows the configuration of expect rows for a dataview. For a more detailed description see the expect rows section for samplers above.
Mandatory: No
samplers > sampler > dataviews > dataview > firstColumn Copied
This setting is used to add a contrived first column to the data view. The cells on the first column can be populated using a combination of existing columns and literals, as specified in this section.
Typically, the feature would be used to attempt create a first column with unique values (i.e. unique row names) in cases where the existing first column does not provide one.
For example:
A data view has a first column A, which has duplicate values. It is known that Column A + Column B would result in unique values. This feature can be then used to add a contrived first column C, and it can be specified that the column be populated by concatenating the corresponding cell values from Column A and Column B, with a separator “-” in-between for the sake of readability.
Mandatory: No
samplers > sampler > dataviews > dataview > firstColumncreate > columnName Copied
The name (heading) of the added first column. See samplers > sampler > dataviews > dataview > firstColumn for more details.
Mandatory: Yes
samplers > sampler > dataviews > dataview > firstColumn > create > combineColumns > column Copied
Specifies the name of an existing column, of which the cell values will be concatenated to populate the cells on the first column. See samplers > sampler > dataviews > dataview > firstColumn for more details.
samplers > sampler > dataviews > dataview > firstColumn > create > combineColumns > literal Copied
Specifies a literal which will be used in place to populate the cells on the first column. This would typically be used to add a separator between cell values taken from existing columns, for the sake of readability. See samplers > sampler > dataviews > dataview > firstColumn for more details.
samplers > sampler > dataviews > dataview > expectRows > initialDelay Copied
The initial delay specifies a time in seconds from when the sampler is first started, until the expect rows are applied. This is necessary for some samplers which must connect to an external data source before producing data (e.g. RMC plug-in). The value must be a positive integer (greater than 0).
Mandatory: No
Default: (no initial delay)
samplers > sampler > dataviews > dataview > createOnGateway Copied
This optional Boolean setting specifies whether
the dataview matching this configuration should be
created on the gateway (true), or whether the settings
should be applied to a dataview published by
netprobe (false). This setting is used to
create a dataview for use by the Compute Engine of
Gateway 2.
This setting is not intended to work with Expect Rows.
Mandatory: No
Default: false
samplers > sampler > dataviews > dataview > createOnGateway > enabled Copied
This Boolean setting specifies whether the
dataview matching this configuration should be
created on the gateway (true), or whether the settings
should be applied to a dataview published by
netprobe (false).
Mandatory: Yes
Default: true
samplers > sampler > dataviews > dataview > createOnGateway > firstColumn Copied
This is the name of the first column created in the dataview.
Mandatory: Yes
samplers > sampler > dataviews > dataview > var-group Copied
Optional group setting. See the group metadata section for more details.
Mandatory: No
Default: (no group)
samplers > sampler > dataviews > dataview > overviewType Copied
The optional overview typesetting allows users to specify the name of the overview type for a dataview, which can help to produce better displays in ActiveConsole 2 when using the metrics overview feature. See above for more details.
Mandatory: No
Default: (plug-in name is used as type)
samplers > sampler > dataviews > dataview > additions Copied
The additions setting allow the configuration of additional space in the dataview for extra data to be added. This feature is typically used in conjunction with the Compute Engine feature of Gateway 2.
Mandatory: No
samplers > sampler > dataviews > dataview > additions > var-headlines Copied
Specifies a list of extra headline variables to be added to the dataview. Headlines which already exist will not be added.
Mandatory: No
samplers > sampler > dataviews > dataview > additions > var-columns Copied
Specifies a list of extra columns to be added to the dataview. Columns which already exist will not be added.
Mandatory: No
samplers > sampler > dataviews > dataview > additions > var-rows Copied
Specifies a list of extra rows to be added to the dataview. Rows which already exist will not be added.
Mandatory: No
Directory Metadata Copied
All directory components configured in the gateway setup can have additional metadata attached to them. This metadata is used in the visualisation layer - primarily by ActiveConsole 2 - to provide additional data to users which are not directly related to the gateway setup. The current list of metadata-items which can be configured is listed below.
Groups Copied
Directory components can be configured an additional group name setting. These groups are typically used in ActiveConsole 2 for grouping in addition to the sorting and searching functionality which ordinary attributes provide.
Groups can be specified as a setting inside the definition of a probe, managed entity, managed entity group, sampler or dataview. The value should be a short descriptive tag and cannot contain new-line characters.
Descriptions Copied
Components can contain additional user-comments to more fully describe their purpose. These comments are typically displayed as a tool-tip popup in ActiveConsole 2, and allow users to quickly check (for example) what the item is monitoring or who to contact for support.
Descriptions are configured by specifying a value for the description setting in the definition of the component being described. These settings can hold any arbitrary text spaced over multiple lines. Valid sections which can contain a description include probe, managed entity and sampler definitions. The description for the entire gateway can also be configured in the gateway operating environment.
Note
Any indentation used for formatting the document within the description will be counted as being part of the description. Thus for multi-line comments the text should be aligned with the left margin to avoid unwanted effects.
Sampler Includes Copied
Sampler Includes allow users to configure subsets of sampler information. The information from all relevant sampler include sections is combined and passed to relevant samplers. Examples of usage of this would be to define a set of processes to be monitored in a samplerInclude and then to include that set into various Processes samplers. Currently three plug-ins support this construct: Processes, FKM and Disk. See the appropriate plug-in reference guide for details of these plug-ins.
Use of SamplerIncludes Copied
SamplerIncludes are configured in the top level SamplerIncludes section of the gateway setup file and are named sections that can be referenced elsewhere (section 1 below).
The SamplerInclude must be configured to reference one or more Sampler instances in the setup file. These are the set of Samplers that it is valid for this Sampler Includes to be included in (section 2 below). The Samplers referenced here must have the same plug-in type as the samplerInclude, otherwise the sampler reference is ignored and a setup error is logged (section 4 below).
The plug-in section defines the plug-in specific configuration items that will be included by the sampler include. This is typically a list of processes or files to be monitored. This is seen in section 3 below.
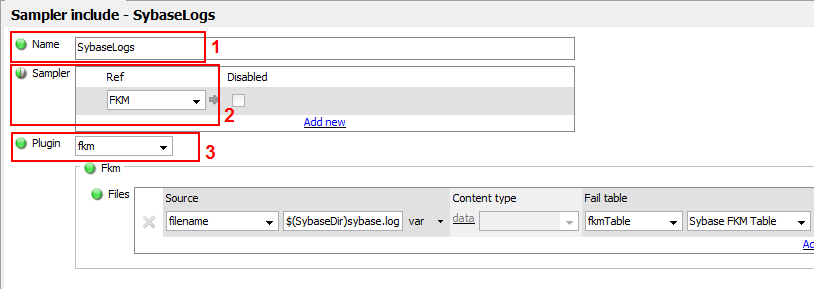
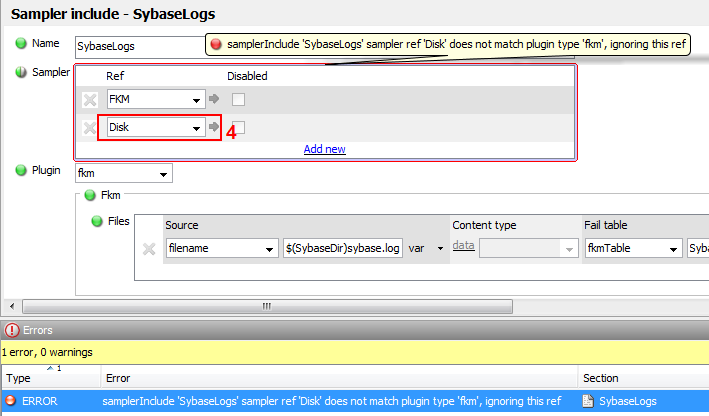
The SamplerInclude must then be referenced from a managedEntity or type section in the same way as a Sampler would be.
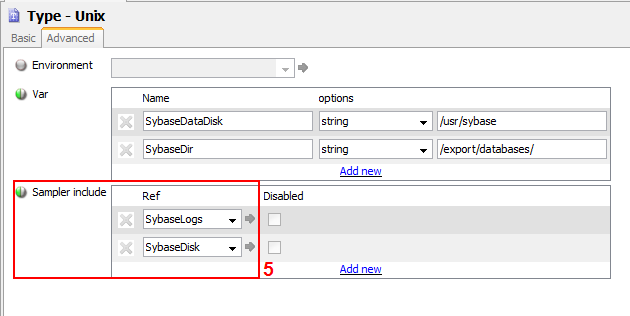
In order to complete the SamplerInclude an instance of one of the samplers referenced by the SamplerInclude must be realised on the target managedEntity. This could be via any type or directly on the managedEntity. If multiple Samplers referenced by the SamplerInclude exist on a managedEntity the SamplerInclude will be applied to all of them.
Variables in SamplerIncludes Copied
As is it possible to use variables in SamplerInclude sections these must be appropriately scoped. During configuration, variable lookup will bind to the managedEntity or type that the SamplerInclude is referenced from irrespective of where the Sampler is referenced from.
On any post configuration lookup (egg rules being applied to dataviews) the variable lookup will bind to the managedEntity or type that the Sampler was referenced from. The usual scoping rules apply in both cases.
Configuration Settings Copied
samplerIncludes > samplerInclude > name Copied
A named instance of a sampler include configuration.
Mandatory: No
samplerIncludes > samplerInclude > sampler Copied
One or more references to named samplers to which this sampler include will apply. The samplers referenced here must have the same plugin type as this samplerinclude or they will be ignored and a setup error will be logged.
Mandatory: Yes (at least one reference is required)
samplerIncludes > samplerInclude > plugin Copied
The plug-in specific configuration node for the sampler include. See the plug-in reference guide for details of configuration under this.
Mandatory: Yes
Active Times Copied
Active times provide time-based control over gateway features, allowing configured functions to be enabled or disabled based on user-defined time periods.
Time-based control can be useful for several reasons. The main feature which utilises active times are in gateway rules. For example, trading links which must be kept operational during trading hours can often be taken down for maintenance during off hours. Rules monitoring these links can reference an active time describing the trading hours, so that alerts are not triggered if the link is down outside of this time.
Additionally features such as actions can be configured to prevent or delay an action being fired using an active time. This could be used to prevent an email action from emailing an administrator outside of office hours, as they would not be present to deal with the error. Active times are configured in the top-level “Active times” section of the gateway setup, and are then referenced by name in other parts of the gateway setup. Thus, active times must be created with a unique name among other active times to avoid ambiguity.
When configuring active times in the Gateway Setup Editor, active time groups can be defined. An active time group contains a logical set of active time definitions. Groups can be added within groups to create a tree structure. Active time groups are purely for ease of use - they allow users to logically organise their active time definitions within their setup. They do not have any affect at a functional level.
Operation Copied
A basic active time is composed of one or more scheduled periods, each of which contains a user-defined time period. When the time on the gateway host enters the range defined by a scheduled period that period becomes active, and correspondingly becomes inactive when the time exits the defined range. A basic active time is considered to be active if at least one of the contained periods is active
Scheduled periods can optionally be configured to be inverted or overridden – the default is none. For an inverted period, the time specified in the period is inactive rather than active. This means that the configured hours actually specify an inactive time. This can be helpful for specifying hours in which you know a particular event in unimportant (e.g. during morning check)
Overriding indicates that a particular time (or day) is a holiday, and should definitely not be active. When the current time enters the specified period the state changes to inactive (overridden) rather than inactive. This prevents the active time from becoming active, even if another period is active at the same time
Combining times Copied
A scheduled period or active time can be in one of three states: inactive, inactive (override) or active. When a time is active gateway features referencing the time will operate as normal otherwise they will be typically be suspended
Active times – in addition to containing several scheduled periods if required – can also reference multiple other active times. When doing this, the state of the referenced times contribute to the state of the active time. In this manner complex active times can be built up by combining several other periods and times as desired
During gateway operation, the state of an active time is calculated from the state of all contained scheduled periods and / or time references. These states are combined according to the table below:
| State 1 | State 2 | Combined State |
|---|---|---|
| Inactive | Inactive | Inactive |
| Active | Inactive | Active |
| Active | Active | Active |
| Inactive | Inactive (override) | Inactive (override) |
| Active | Inactive (override) | Inactive (override) |
| Inactive (override) | Inactive (override) | Inactive (override) |
Note
When combining times it is a checked error to configure a cycle of times which reference each other. For example, configuring a time A which references a time B (A->B), B->C and C->A is disallowed since changes to time A would affect C, which affects B which affects A. This could lead to a possible infinite loop and so will be detected and discarded by gateway.
Timezones Copied
It is possible to specify an ActiveTime to run in a different timezone. If you specify a timezone, the specified times in that ActiveTime will run as if they were a local ‘wall clock’ in the region specified. This can be useful for example if you have rules on a London gateway that monitor a service from Tokyo. The gateway will take into account timezone offsets and daylight savings rules for both the local and specified timezones. The default is to run in the local time to the Gateway.
Specifying an override period Copied
This shows the configuration of a named holiday period.

- The start and end times are not configured. This will default to the whole day.
- The date is explicitly configured to May Day (5th May) holiday 2008.
- The Override flag is set. This means that this ActiveTime will be inactive and override any other referenced ActiveTimes which are active during the specified period.
Specifying time periods Copied
This shows how to specify certain times of the day.

- Explicit start and end time are configured.
- No days or date options are specified so all will be active during the specified time period on all days.
- The previously specified holiday is referenced by this ActiveTime so the holiday specified in ‘May Day’ will apply.
- Either the start time or end time can be left unspecified. If the start time is unspecified, then the start of day (00:00) will be assumed. If the end time is unspecified, then the end of day will be assumed.
Specifying inverted time periods Copied
This shows the configuration of a sample night shift ActiveTime.
- Explicit start and end times are configured.
- The invert flag is specified. The ActiveTime will be active from 0.00 - 06:30 and 19:30 - end of day. The ActiveTime will be inactive outside of these times.
Configuration Copied
activeTimes Copied
The active times top-level section contains the active time configuration. This configuration includes the definition of the time periods, but not which components / features are affected by these times.
Mandatory: No
activeTimes > activeTimeGroup Copied
A logical set of active time definitions. Active time groups are purely to allow users to logically organise their active time definitions within their setup, they do not have any affect at a functional level.
Mandatory: No
activeTimes > activeTimeGroup > name Copied
Specifies the name of the active time group. Although the name is not used internally by gateway, it is recommended to give the group a descriptive name so that users editing the setup file can easily determine the purpose of the group.
Mandatory: Yes
activeTimes > gatewayControlledProbeActiveTimes Copied
By default the netprobe controls the operation of active times assigned to samplers. When this flag is enabled, the control will be shifted to the gateway, resulting in the gateway messaging the netprobe as and when relevant active times are entered and exited. Enabling the flag allows active times assigned to samplers to have timezones specified, as well as use seconds level resolution. One side effect of enabling this feature is that unless the timezone is explicitly specified in the active time definition, the sampler active times will work according to the timezone on the gateway host. If this feature is not enabled, the sampler active times will work according to the time on the netprobe host.
Mandatory: No
activeTimes > activeTime Copied
The definition of an active time for use by other gateway components. This definition is referenced by name, and so all active time definitions must have a unique name within the active times top-level section.
Mandatory: No
activeTimes > activeTime > name Copied
The name used to reference this active time. Each name must be unique within the system.
Mandatory: Yes
activeTimes > activeTime > schedulePeriod Copied
A scheduled period definition contains a description of a time period. There can be many periods specified for a single active time.
Mandatory: No
activeTimes > activeTime > schedulePeriod > startTime Copied
Specifies the start time for the period in HH:MM or HH:MM:SS format, using 24-hour clock. If seconds are not specified then this defaults to 0. The start time is inclusive, and so the period will become active at HH:MM:SS.
Note
Second resolution activetimes are not supported for active times that are applied to samplers unless the gatewayControlledProbeActiveTimes setting is enabled.
Mandatory: No
Default: 00:00:00 (start of day)
activeTimes > activeTime > schedulePeriod > endTime Copied
Specifies the end time for the period in HH:MM or HH:MM:SS format, using 24-hour clock. If seconds are not specified then this defaults to 0. The end time is exclusive, and so the period will become inactive at HH:MM:SS (for Gateway controlled active times) or HH:MM and 00 seconds for probe controlled active times as Netprobe cannot handle seconds’ resolution. To create a scheduled period that lasts until the end of a day, leave this unspecified. As noted earlier, second resolution activetimes are not supported for active times that are applied to samplers unless the gatewayControlledProbeActiveTimes setting is enabled.
Mandatory: No
Default: End of day

activeTimes > activeTime > schedulePeriod > date Copied
Specifies the date that the active time period occurs on. Possible formats include the day (DD), the day and month (DD/MM), or the day, month and year (DD/MM/YYYY). If specified on a day, the time period will apply on that day each month. For a day and month, the time period will apply on that date each year.
Mandatory: No
Default: If day is not specified, then the time period applies every day
activeTimes > activeTime > schedulePeriod > days Copied
Specifies the days of the week on which the time period applies to. This contains a list of Boolean settings selecting the named day.
Mandatory: No
Default: If date is not specified, then the time period applies every day
activeTimes > activeTime > schedulePeriod > day Copied
Specifies the time period as a repeating day. For example, the last Friday in every month of every year, or the first Monday in June every year.
Note
It is not possible to specify the repeating day every month in a given year. For example, you can specify the first Monday of every month of every year, but you cannot specify the first Monday of every month in the year 2020.
Day contains the following options:
- Ordinal — First, Second, Third, Fourth, Last.
- Day — each day Monday–Sunday.
- Month — each month January–December, Every Month.
- (Optional) Year — 2018–2028, year entered by you (for example, 2020).
Mandatory: No
activeTimes > activeTime > schedulePeriod > override Copied
This Boolean setting controls whether this period describes a holiday (true) and hence the time is inactive during this period.
Mandatory: No
Default: false
activeTimes > activeTime > schedulePeriod > invert Copied
This Boolean setting controls whether this period is inverted (true) and so specifies an inactive time rather than an active time.
Mandatory: No
Default: false
activeTimes > activeTime > activeTime Copied
References another active time by name. The state of the referenced time then contributes to the state of this active time.
Mandatory: No
activeTimes > activeTime > timezone Copied
It is sometimes necessary for an ActiveTime to run in a timezone that is different to the local timezone that the Gateway is running in. This might be the case, for example, if you are monitoring services in Tokyo and New York from a New York Gateway. The timezone region can be selected from the list. The timezone feature is used only if the active times are gateway controlled.
Mandatory: No
Default: Runs in local timezone of the Netprobe or Gateway
Hot Standby Copied
Overview Copied
As gateway is responsible for consolidating all monitoring data for distribution to ActiveConsole 2 and other visualisation components, this introduces a single point of failure. To alleviate the problem two gateways can be run as a hot-standby pair, so that if one gateway fails the other gateway will remain in operation until the fault is rectified.
A gateway can be in one of three roles; Stand Alone, Primary or Secondary. A single running gateway runs in Stand Alone mode, while a hot standby pair consists of one Primary and one Secondary gateway.
In the latter configuration, the Primary will be responsible for all gateway operations, collecting and analysing data from Netprobes and distributing the results to connected ActiveConsoles. The secondary gateway remains in an idle state, ready to take over monitoring duties should the primary gateway fail. This is represented by the “Normal Operation” section of the diagram below.
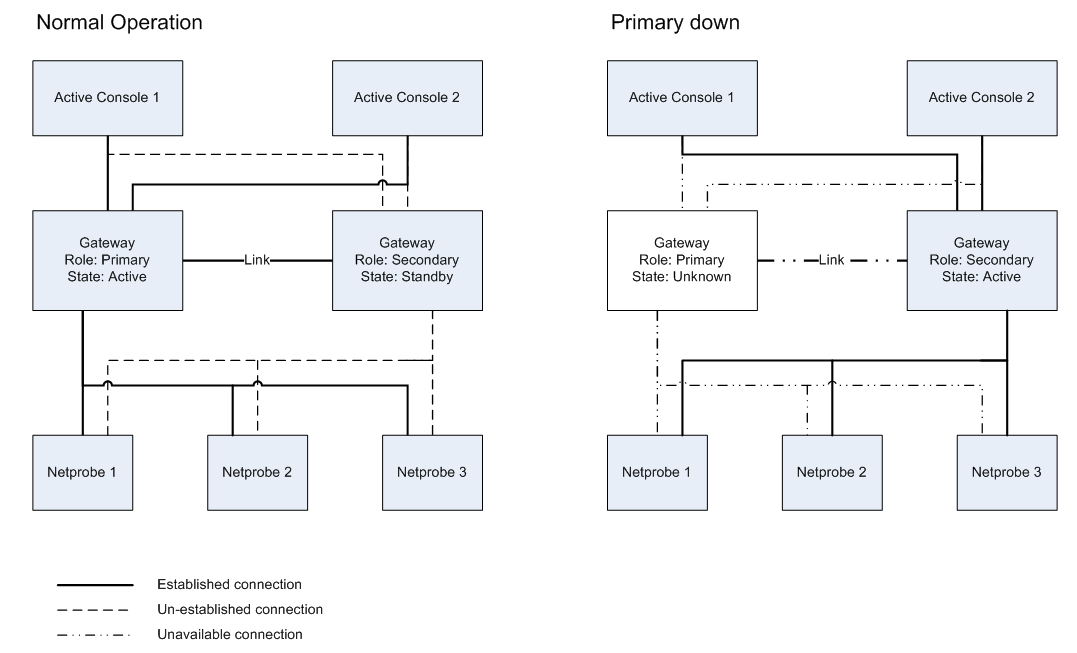
If the primary gateway fails for some reason, the secondary gateway will then connect to Netprobes and take over the gateway duties until the primary gateway becomes operational again. This is represented by the “Primary down” section of the diagram.
Hot standby Failback Copied
Under normal operation restarting the primary gateway will result secondary releasing the probes and the primary regaining control. If you do not want this to happen automatically then both gateways need to be started with the "-manual-failback" option on the command line.
If the Gateway’s are not both started with the same option, the secondary will not successfully connect to the primary and the primary will effectively be running stand alone until this is corrected.
In manual failback mode when a secondary gateway becomes active it doesn’t relinquish control until the “manual failback” command is issued. This allows you to restart your gateway and transfer control at a convenient time.
Note
A Gateway configured for manual failback will not allow connections from clients that do not support this feature. This includes old versions of ActiveConsoles and OpenAccess. ActiveConsole will inform the the user that the connection has been rejected with the following reason:
“Connection to hot-standby Gateway rejected. Gateway is in manual failback mode and client does not support this.”
Scheduling failback Copied
The failback command ("/Gateway:failback") can scheduled like any other internal command. This could be useful to schedule an automatic failback outside of business hours should a secondary take over the role of primary at some point.
The suggested XPath for the target would be:
/geneos/gateway/directory[(param("HotStandbyRole")="Secondary")][(param("HotStandbyManualFailbackActive")="true")][(rparam("HotStandbyState")="Active")
which would ensure that the command is only run on an active secondary in a manual-failback mode.
Configuration Copied
Basic configuration for a Hot Standby pair of gateways consists of specifying the hostname and port for each gateway in the pair. Hostnames can be specified as either the machine hostname (obtained by running the hostname command), as an IP address, or as a fully qualified domain name (e.g. “somehost.somedomain.com”).
When Hot Standby gateway setup is applied, a Gateway will determine whether it is running as the primary or secondary host. It does this by comparing first the primary then the secondary hostname with the identity of the host the Gateway is running on. The first match found will determine the Gateway role; if no settings match the gateway will run as Stand Alone.
Each comparison is performed in the following order:
- First, the gateway checks if a configured hostname is an IP address (e.g. 192.168.1.135); this will be then compared with the IP address(es) of the host.
- Second, if a configured hostname is a fully qualified domain name (e.g. “somehost.somedomain.com”), the whole name as given and then the first part of the configured hostname will be compared with the Gateway host name. For example, “somehost.somedomain.com” will match if the Gateway host name is also “somehost.somedomain.com”, or “somehost” but not if the Gateway host name is “somehost.anotherdomain.com”.
- Otherwise, the gateway will compare the configured hostname with the full Gateway host name and then with the first part of its name. Therefore, if the configured host name is “somehost”, it will match if the Gateway host name is “somehost.somedomain.com” or “somehost”, as well as “somehost.anotherdomain.com”.
A secondary gateway will attempt to connect to the primary gateway on the configured hostname and port. If the hostname is not specified as an IP address, gateway will attempt to resolve this using a forward DNS lookup.
When the primary gateway receives a connection from another gateway, it will then try to authenticate this gateway by matching the incoming connection against the configured secondary gateway. The way this is done is controlled by the primarySecurityCheck setting, which by default will resolve the connecting IP to a hostname using a reverse DNS lookup (if required) and match this against the secondary gateway configuration.
The settings are as follows:
hotStandby Copied
Holds the primary and secondary gateway settings.
hotStandby > primary Copied
Contains settings for the Primary gateway in a hot-standby pair.
hotStandby > primary > hostname Copied
The primary gateway host, specified as either the machine hostname or an IP address. The secondary gateway uses this setting to connect to the primary gateway, and so the hostname must also resolve to an IP address using a forward DNS lookup.
hotStandby > primary > port Copied
The listen port of the primary Gateway. If the Gateway is listening on both a secure and an insecure port, this value must match the secure port the Gateway is listening on.
If the primary and secondary Gateways need to listen on different ports, one or both of the Gateways must be started with the command line -port option to override the port value set in operatingEnvironment > listenPorts. This value must match the port set on the command line if that is used. See Using different ports for primary and secondary gateways.
hotStandby > secondary Copied
Contains settings for the secondary gateway in a hot-standby pair.
hotStandby > secondary > hostname Copied
The secondary gateway host, specified either as the machine hostname or an IP address. The primary gateway will check any incoming gateway connections against this setting, either comparing the IP address directly or by using a reverse DNS lookup to resolve the connecting host to a hostname for comparison.
hotStandby > secondary > port Copied
The listen port of the secondary Gateway. If the Gateway is listening on both a secure and an insecure port, this value must match the secure port the Gateway is listening on.
If the primary and secondary Gateways need to listen on different ports, one or both of the Gateways must be started with the command line -port option to override the port value set in operatingEnvironment > listenPorts. This value must match the port set on the command line if that is used. See Using different ports for primary and secondary gateways.
Basic Configuration Copied
The following shows how to configure a primary gateway on a machine called ultra10 that listens on port 15020 and a secondary gateway on a machine called eqtest2 that listens on port 15020.
- Select the “Hot Standby” node. You should see the Hot Standby configuration options appear in the centre pane.
- Fill in the details for the primary gateway and then for the secondary gateway.
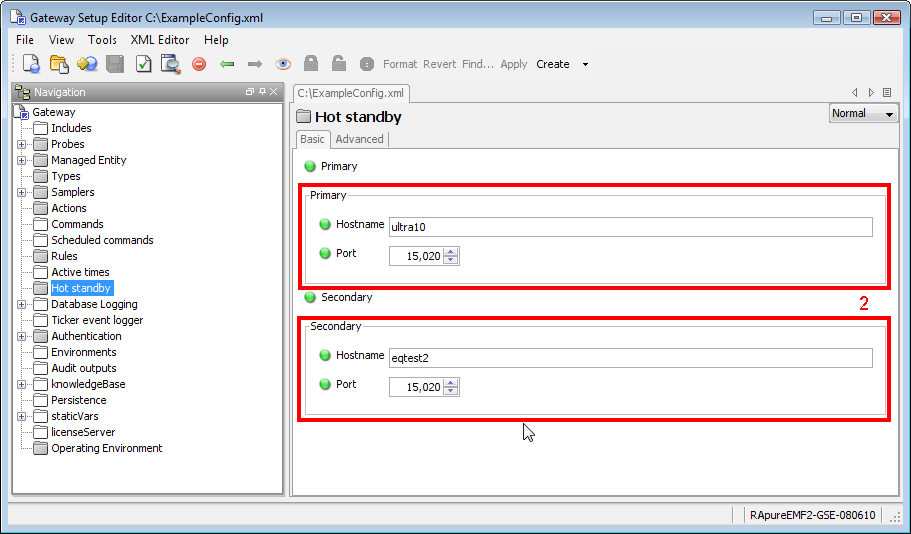
Hot Standby with Secure Ports Copied
To use secure ports with Gateways, configure the Gateway with a secure listen port in operatingEnvironment > listenPorts. The port for both the primary and secondary Gateway must match the secure port set. If you are using different secure ports on the primary and secondary Gateways, see Using different ports for primary and secondary gateways.
Note
It is possible to specify both secure and insecure ports with Hot Standby. However, if you do specify both secure and insecure ports, you cannot specify different ports for primary and secondary Gateways.
Using different ports for primary and secondary gateways Copied
The Gateway setup is synchronised between primary and secondary Gateways. Therefore, configuring the settings with a different value depending upon the Gateway role must be done externally to the Gateway setup file.
This also applies to the listenPort setting for
Gateway. Therefore, to use different ports for
primary and secondary Gateways, you must set the listen port using the ‑port command line option. The ‑port command line option overrides the secure listen port if set, otherwise it overrides the insecure port. For example:
To start the primary gateway:
gateway2.linux -setup hotStandbyExample.xml -port 22040
To start the secondary gateway:
gateway2.linux -setup hotStandbyExample.xml -port 22045
The gateway hotStandby section as displayed in the Gateway Setup Editor (GSE):
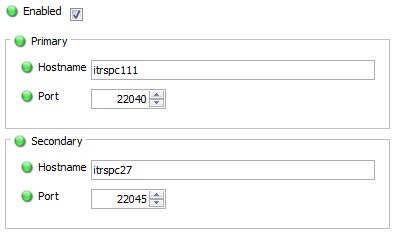
Note
You can only override one port setting using the command line option-port. Therefore, you cannot specify different ports for primary and secondary Gateways if you also need to configure both secure and insecure ports.
Paired operation Copied
It is recommended that primary and secondary gateways run on different hosts. This way failure of the host (or network connectivity of the host) will not affect the secondary gateway and monitoring can continue unaffected.
Once the hot-standby configuration is completed, the setup file should be copied from the primary to the secondary host. This setup should then be applied to the primary gateway first, and then to the secondary gateway.
The primary gateway must be started first because the secondary gateway will attempt to connect to it in order to synchronize operation between gateways. This connection is maintained while both gateways are in operation. Should the connection fail the secondary gateway will become active after a brief time and take over monitoring duties from the failed primary gateway.
While the secondary gateway is active, users should not notice a difference in services between gateways. In particular it is still possible to alter the gateway setup. When the primary gateway is running again the synchronisation between gateways will ensure that the primary gateway receives an up-to-date copy of the setup file before it takes up monitoring operations again.
When the primary gateway is reactivated there will be a short period when the secondary gateway releases control of Netprobes and the primary gateway acquires them again during which monitoring is paused. It is possible to remove this period by switching the (active) secondary gateway to a primary role by altering the gateway setup, before the primary gateway is restarted. When performing this switch, please ensure that the setup for the old primary gateway is also edited so that it runs as a secondary gateway.
A parameter, “HotStandbyRole” and a runtime parameter “HotStandbyState” are available on the directory object. These can be used to alert when hotstandby failovers occur. The following rule is an example of how this could be used.
Target:
/geneos/gateway/directory
Rule:
if param "HotStandbyRole" = "Secondary" and rparam "HotStandbyState" = "Active" then
run "myFailoverAction"
endif
Parameter “HotStandbyRole” and runtime parameter “HotStandbyState” can be described as follows:
If HotStandbyRole = Primary then HotStandbyState will be Active
If HotStandbyRole = Secondary then HotStandbyState will be Active or Inactive
If HotStandbyRole = Stand Alone then HotStandbyState will be Active
Fine tuning Copied
There are three additional settings to further fine tune hot-standby functionality:
hotStandby > primarySecurityCheck Copied
This setting controls how the primary gateway verifies that a connection is from the configured secondary gateway when using hot-standby functionality.
| Value | Effect |
|---|---|
| reverseDns | The IP address of the connecting secondary is resolved to a hostname using a reverse DNS lookup. This hostname is then compared against the configured secondary. |
| forwardDns | If the configured secondary gateway is specified as a hostname, then this is resolved to an IP address. This address is then compared with the address of the connecting secondary gateway. |
| disabled | Security checks are disabled. A connection from a gateway is assumed to be from the configured secondary gateway. |
Mandatory: No
Default: reverseDns
hotStandby > primaryInactiveTimeout Copied
The period of time in seconds a primary gateway will wait at start-up for a secondary gateway to connect to it.
Mandatory: No
Default: 30 seconds
hotStandby > primaryActivePendingTimeout Copied
The period of time in seconds a primary gateway will wait for the secondary gateway to release any Netprobes it controls, after the secondary gateway has connected.
Mandatory: No
Default: 30 seconds
hotStandby > secondaryActivePendingTimeout Copied
The period of time in seconds a secondary gateway will wait to reconnect to the primary gateway after the connection between them goes down.
Mandatory: No
Default: 30 seconds
Basic Configuration Copied
The following shows how to further configure a hot standby set-up by fine tuning timeouts for both the gateways. In the example below, we set the primary gateway’s inactive timeout to 20 seconds, the primary gateway’s active pending timeout to 5 seconds and the secondary gateway’s active pending timeout to 5 seconds.
- Select the Advanced tab of the “Hot Standby” pane and configure the fields as displayed.
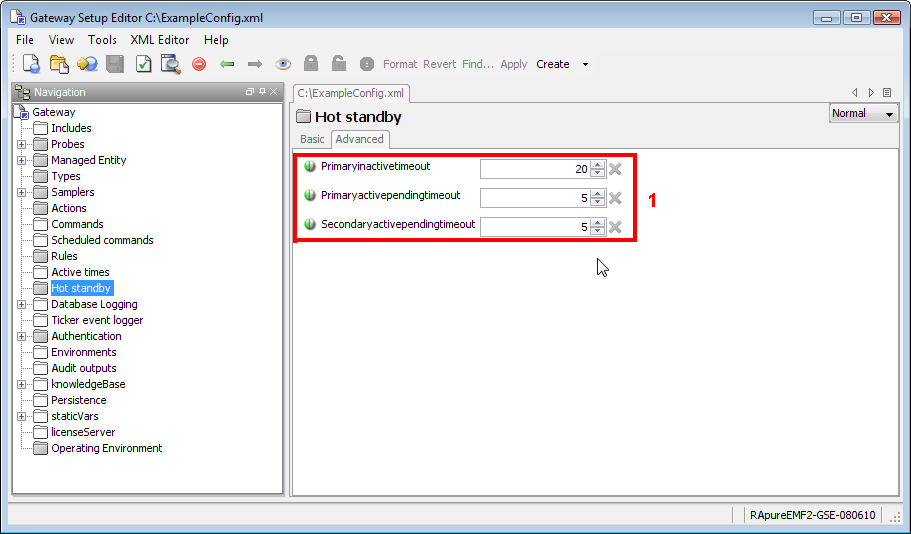
File Synchronization Copied
Hot standby gateways can also be configured with a set of external files to keep synchronized. These files will then be transferred from the active (typically primary) gateway if the file sizes are different between gateways, or the active gateway detects that the file has been modified.
External files are synchronized at 2 points - when a setup change is applied, or if the gateway detects a change while checking external files. The frequency at which external files are checked can be controlled using the externalFilesCheckInterval setting.
Included setup files (see setup file merging) can also optionally be synchronized between gateways, although these files will only be synchronized when a setup change is applied, and not on file modification or size changes.
This feature is configured using the settings below:
hotStandby > syncFiles Copied
Hot standby file synchronization is configured using this section.
hotStandby > syncFiles > setupIncludes Copied
This Boolean setting controls whether included setup files are synchronized between gateways. A value of true indicates that include files will be synchronized.
This should only be done however if there is a separate copy of the include files for both the primary and secondary gateways in the hotStandby pair. Recommended practise for include files is to locate them in a shared location, so that they can be shared between multiple gateways (e.g. a global users file).
Mandatory: No
Default: false
hotStandby > syncFiles > disabledSetupIncludes Copied
This Boolean setting controls whether disabled included setup files are synchronized between gateways. A value of true indicates that disabled include files will be synchronized.
Mandatory: No
Default: false
hotStandby > syncFiles > externalFilesCheckInterval Copied
This setting defines how frequently gateway will check the external files, to see if they need to be re-synchronized. Files are checked to see if the file size is different between gateways, or if the file modification time has been updated since the last check.
The check interval is specified in seconds. After this many seconds since the previous check was made, gateway will check the external files again. External files are also checked when a setup change is applied.
Mandatory: No
Default: 300 (5 minutes)
hotStandby > syncFiles > externalFiles Copied
A list of external files can be defined here, which the gateway will then attempt to keep in sync across the hot-standby pair.
Mandatory: No
hotStandby > syncFiles > externalFiles > externalFile Copied
Defines a single external file, which the gateway will attempt to keep in sync between gateways in a hot-standby pair.
hotStandby > syncFiles > externalFiles > externalFile > primaryPath Copied
Specifies the path of the external file on the primary gateway. The gateway will search here for the file when performing synchronization. This location should be both readable and writable by the gateway.
Mandatory: Yes
hotStandby > syncFiles > externalFiles > externalFile > secondaryPath Copied
Specifies the path of the external file on the secondary gateway. This optional setting allows users to configure external files that are present on both gateways, but in different locations. If a secondary path is not specified, then the path is assumed to be the same as the configured primary path.
Mandatory: No
Default: (same as primaryPath if not specified)
Environments and User Variables Copied
In many places in the setup file it is possible to specify the value of a setting either by entering data directly, or by referencing a variable.
Variables are typically configured for settings in a sampler configuration. This allows the same sampler definition to be used in several places, and the behaviour of the sampler will depend on the values of the variables at the point in which it is used.
Alternatively, the same variable can be referenced by many different samplers (e.g. the sample interval), allowing the user to control their behaviour by altering a single value.
Variables have scoping rules which define where they are valid and hold values. This means that - although Gateway Setup Editor (GSE) may suggest the name of a variable to use - the variable referenced may not be resolvable in a particular instance.
For example, a sampler which references the variable
myVar can be added to managed
entities me1 and me2.
If me1 defines a value for myVar
but me2 does not, then the sampler on
me2 will not be able to resolve this
reference to a value, and will use an empty value
instead.
Gateway will produce setup validation warnings for this occurrence, so it is advisable to check this output when making setup changes.
Referencing Variables Copied
To reference (use the value of) a variable, simply
configure a setting using a variable name instead of a
data value. In the GSE a setting which supports
variables appears with a blue hyperlink stating either
data or var.
Click on this text to switch between data and variable
modes, and supply the data value or variable name
respectively. (See screenshots data and
var below).
Some settings (typically text-valued settings) also
support inline usage of variables, which allow the
value of a variable to be inserted in the middle of
user-supplied text (i.e. a mix of data and var values).
To insert a variable reference, just click on the
var drop-down to the right of the
setting and select a variable to use. (See screenshot
for Inline variable usage
below).
Sample interval without using a variable Copied
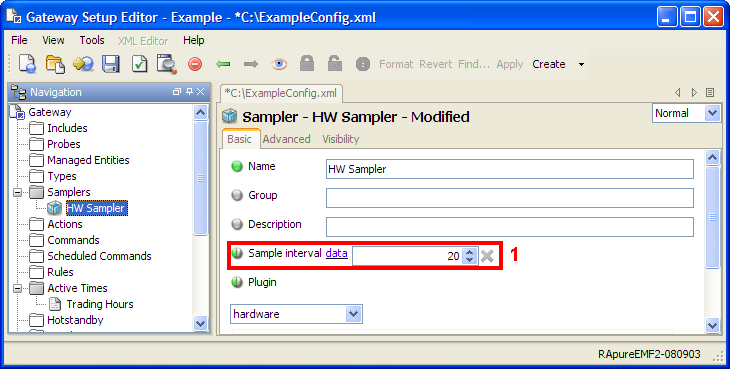
- Here the value is set directly using the ‘data’ option.
Sample interval using a variable Copied
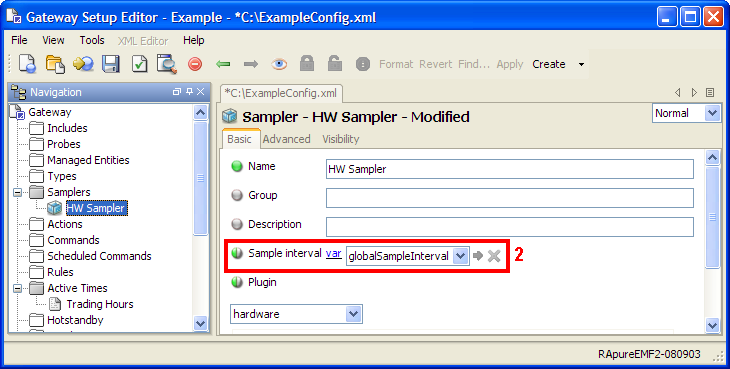
- Here the value is set using a name variable ‘globalSampleInterval’ using a variable reference (var) option.
Inline variable storage Copied
The following screenshot shows an example of
inline variable usage, which allows a mix of
user-supplied (text) data and variables to be used.
Settings which support this will display a
var dropdown menu to the right of
the setting, which will insert a reference to the
selected variable. In the example, the process_user
variable has been inserted into the path for a log
file.
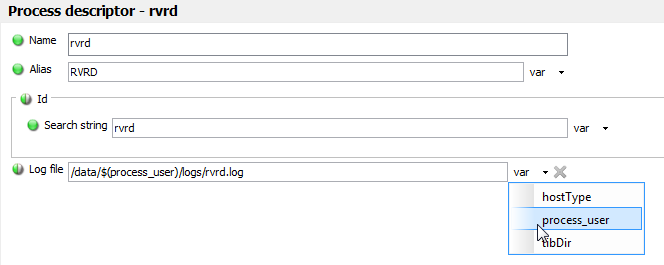
Defining Variables Copied
Variables can be defined in managed entities, managed entity groups, types, environments and operating environment.
A variable definition consists of the variable name and its value. The value can be one of several different types including basic data types such as strings and integers, as awell as more complex types such as a list of items or an active time reference.
Where possible, the variable type should fit the intended usage. For example, the sample interval setting takes integer values and so if using a variable here an integer type should be used. Gateway will attempt to substitute (for instance) a text value where an integer value is expcted, but this will not work for all situations.
To define a new variable using the Gateway Setup
Editor (GSE) simply click on the “Add new” button for
the var section for the desired managed
entity (or type, environment, etc…) and fill in the
variable name and value.
Defining a variable in a Managed Entity Copied
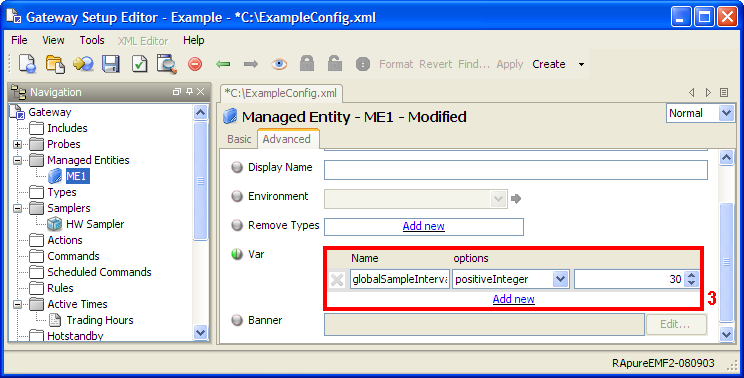
- This example shows the variable ‘globalSimpleInteval’ being set in a ManagedEntity section.
Using Environments Copied
If the same group of variables are used repeatedly in multiple places, then it may be worth considering using an environment. An environment is a collection of variables, and is configured using the environments top-level section.
Each managed entity or type can reference a single environment, which then makes the variables contained within the environment accessible by any samplers defined on that entity or type. When a type is added to a managed entity using an addTypes setting, an environment can also be specified for use by the samplers defined within the type.
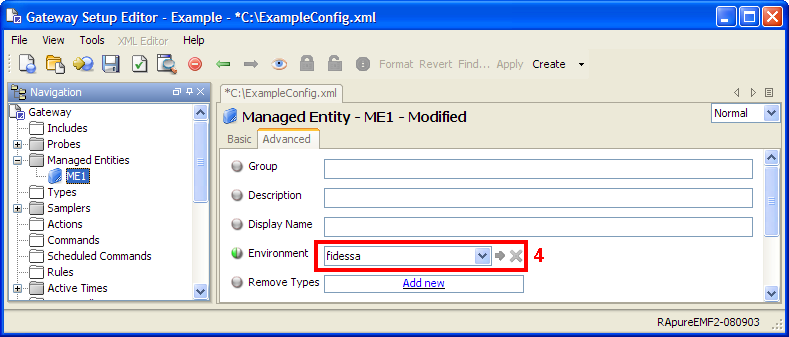
- Here the managed entity references an environment named ‘fidessa`.
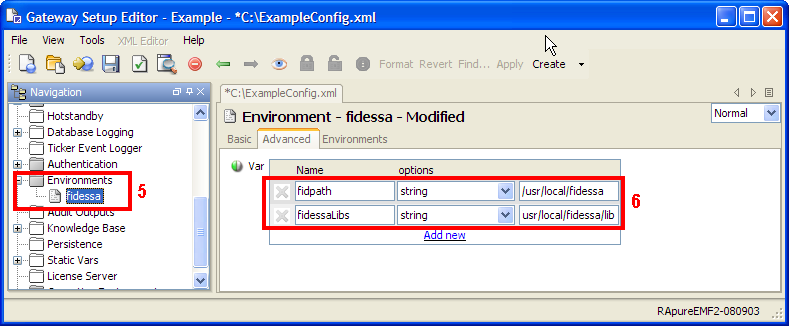
- The named environment ‘fidessa’ is defined here.
- Two variables are specified within this environment.
It is also possible to nest environments to allow specialisations. In the following example, emma and omar environments will both contain their own version of fidpath but will inherit the fidessaLibs from the fidessa environment.
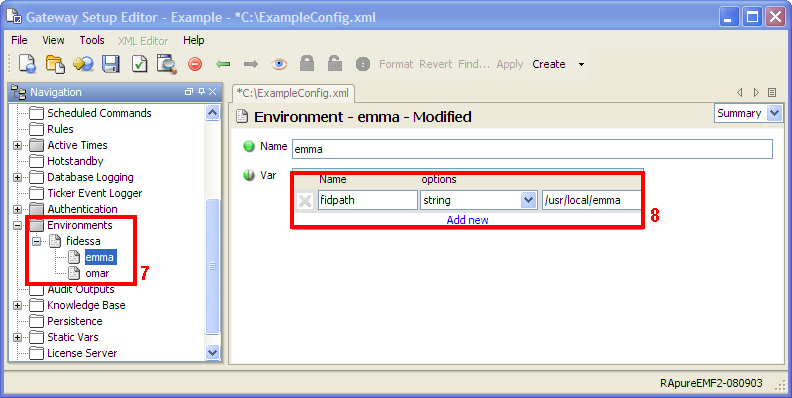
- Here two specialisations of ‘fidessa’, ’emma’ and ‘omar’ are configured.
- The variable ‘fidpath’ is explicitly defined for environment ’emma’.
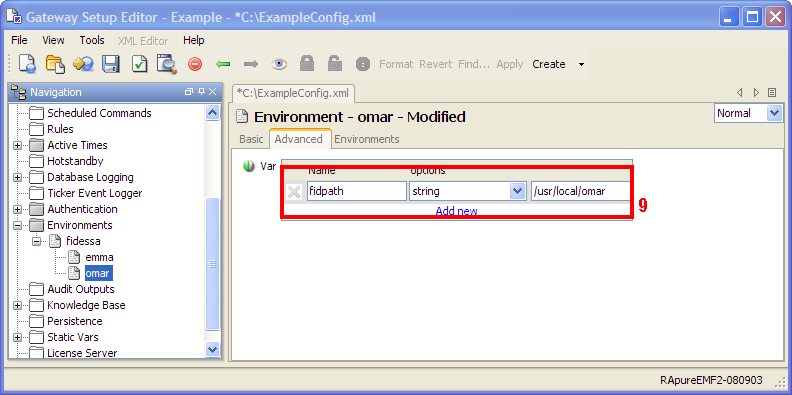
- Similarly the variable ‘fidpath’ is explicitly defined for environment ‘omar’.
Environment Configuration Copied
environments > environmentGroup Copied
Environment groups are used to group sets of environments, to improve ease of setup management.
Mandatory: No
environments > environmentGroup > name Copied
Specifies the name of the environment group. Although the name is not used internally by gateway, it is recommended to give the group a descriptive name so that users editing the setup file can easily determine the purpose of the group.
Mandatory: Yes
environments > environment Copied
Each configuration in this section is a named environment that can be accessed from other parts of the configuration. An environment defines a set of variables that can be referred to by users of the environment.
Mandatory: Yes
environments > environment > name Copied
Specifies the name of the environment. Although the name is not used internally by gateway, it is recommended to give the environment a descriptive name so that users editing the setup file can easily determine the class of variables in this environment.
Mandatory: Yes
environments > environment > var Copied
Each var element represents a named variable which can be accessed from its environment. There are several variable types available.
Mandatory: Yes
environments > environment > var > name Copied
The name that is used to identify the variable. The name must be unique within each variable scope.
Mandatory: Yes
environments > environment > var > activeTime Copied
Specifies a variable of type activeTime reference which refers to an active time in the system.
Mandatory: No
environments > environment > var > boolean Copied
Specifies a variable of type Boolean which can take a value of true or false.
Mandatory: No
environments > environment > var > double Copied
Specifies a variable of type double which can take a double precision floating point numerical value.
Mandatory: No
environments > environment > var > externalConfigFile Copied
Specifies a variable which can take the name of an external configuration file.
Mandatory: No
environments > environment > var > integer Copied
Specifies a variable which can take a numerical integer value.
Mandatory: No
environments > environment > var > nameValueList Copied
Specifies a variable which can take a list of name value pairs.
Mandatory: No
environments > environment > var > nameValueList > item Copied
Specifies a single name/value pair in the list.
Mandatory: No
environments > environment > var > nameValueList > item > name Copied
Specifies the name in a single name/value pair in the list.
Mandatory: No
environments > environment > var > nameValueList > item > value Copied
Specifies the value in a single name/value pair in the list.
Mandatory: No
environments > environment > var > regex Copied
Specifies a variable which can take a regular expression.
Mandatory: No
environments > environment > var > string Copied
Specifies a variable which can take a string.
Mandatory: No
environments > environment > var > stringList Copied
Specifies a variable which can take a list of strings. This can be used in various plugins to define lists of values. It can also be used it the inList() function in rules. (There is no where else in rules that stringLists should be used).
Mandatory: No
environments > environment > var > stringList > string Copied
Specifies a single string in the string list.
Mandatory: No
environments > environment > var > macro Copied
Specifies a variable that takes the value from the gateway itself. The following macros are supported:
| gatewayName | The name of the gateway |
|---|---|
| gatewayPort | [deprecated] The port number on which the gateway is listening (secure port if gateway is listening on two ports) |
| secureGatewayPort | The port number on which the gateway is listening for secure connections |
| insecureGatewayPort | The port number on which the gateway is listening for insecure connections |
| managedEntityName | The name of the managed entity |
| netprobeHost | The host name of the netprobe |
| netprobeName | The name of the netprobe |
| netprobePort | The port number on which the netprobe is listening |
| samplerName | The name of the sampler |
The values of macros that cannot be resolved because they are not applicable (e.g. the value of samplerName on a Managed entity) will return the name of the macro.
Mandatory: No
Inherited Variables Copied
Managed entities and environments will inherit any
variables defined in its ancestor sections in the
gateway setup. For instance, in the screenshot below
managed entity linux1 will inherit the three
variables shown, as they are defined in the managed
entity group linuxhosts which contains
the linux1 definition.
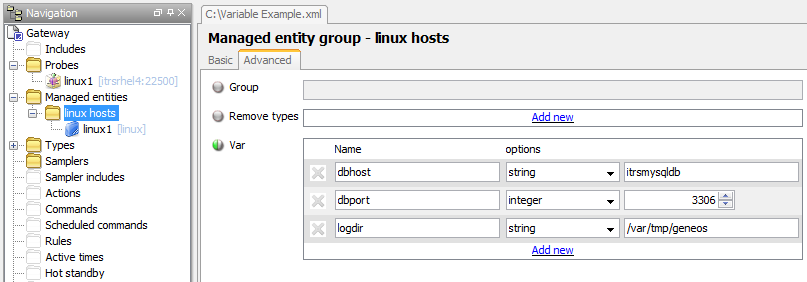
Inherited variables can also be overridden (a new value given to the variable, replacing the inherited value) by re-defining the variable again with the new value. Additional variables can also be defined as normal.
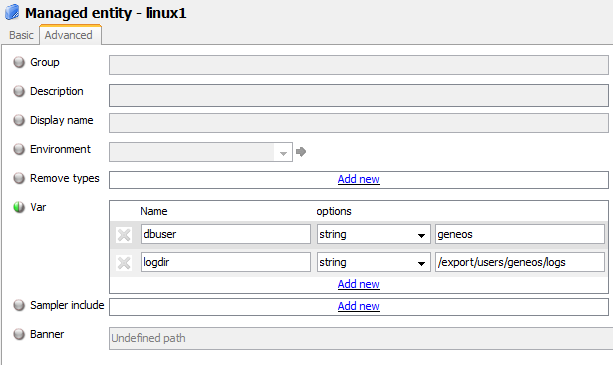
The above screenshot shows the variables defined in
the linux1 managed entity. As this
entity is part of the linuxhosts group, it
inherits the 3 variables dbhost, dbport and logdir. (See previous screenshot
for definitions).
The additional var entries define a new variable
dbuser, and override the inherited
logdir variable with a new value.
This brings the total number of variables for this
managed entity to 4 (3 inherited variables with 1
overridden, and 1 new variable).
Variable Scoping and Resolution Copied
When a variable reference is used in a sampler or sampler include, it is resolved by looking through the following locations in order until the variable can be found. If it is not found then an empty value will be substituted (a gateway validation warning is also produced for this occurrence).
If the sampler or sampler include is referenced by a type:
- The environment specified when the type was added to that managed entity or managed entity group.
- Variables defined directly in the type
- The environment referenced by the type
If the sampler or sampler include is referenced in the managed entity or managed entity group, or was not found in the above:
- Variables defined in (or inherited by) the managed entity
- The environment referenced by the managed entity
- The operating environment
For a sampler include, if the variable still cannot be resolved:
- This process is repeated, using the locations that would be searched when resolving variables for the host sampler configuration.
Static Vars Copied
The “static vars” section of the gateway setup defines a number of static variables. These variables can be referenced as part of a sampler configuration.
The main use of static variables is to allow a common set of configuration options to be referenced by samplers. These settings are then available in a single place and can be easily updated, rather than having to alter the configuration of a number of samplers manually.
This section is divided into a number of sub-sections, which can only be referenced by plug-ins of a certain type. For example FKM tables can only be referenced by samplers using the FKM plug-in.
FKM Tables Copied
staticVars > fkmTables Copied
The FKM tables section allows users to configure tables separately to an FKM plug-in instance. These tables can then be referenced by individual FKM files across multiple samplers / managed entities. For more information about tables, see the FKM plug-in reference guide. Defines all the FKM tables in the static variables section.
Mandatory: No
staticVars > fkmTables > fkmTable Copied
Defines an FKM table which can be referenced in FKM samplers.
Mandatory: No
Refer to the FKM Plug-In User Guide for further information on FKM tables.
staticVars > fkmTables > fkmTable > name Copied
The name of the static FKM table. This name should be unique among all other FKM tables defined in the static variables section.
Mandatory: Yes
staticVars > fkmTables > fkmTableGroup Copied
A grouping mechanism to allow FKM tables to be logically grouped together.
Mandatory: No
staticVars > fkmTables > fkmTableGroup > name Copied
The name of the FKM table group.
Mandatory: Yes
GL-names Copied
staticVars > gl-names Copied
The GL names section contains name lists which can be referenced by the GL‑Router or GL‑Permissions plug-ins.
Mandatory: No
Refer to the GL_Router Plug-in User Guide for further information on GL names.
staticVars > gl-names > gl-names Copied
A GL names list contains a mapping of identifiers to strings. These lists allow users to configure meaningful names for their GL users, processes and connections, which are then displayed as part of the monitoring data produced by the GL plug-ins.
Mandatory: No
staticVars > gl-names > gl-names > name Copied
The name of this GL name list. This name should be unique among all other name lists defined in the static variables section.
Mandatory: Yes
staticVars > gl-names > gl-namesGroup Copied
A grouping mechanism to allow GL names lists to be logically grouped together.
Mandatory: No
staticVars > gl-names > gl-namesGroup > name Copied
The name of the GL names list group.
Mandatory: Yes
Process Descriptors Copied
staticVars > processDescriptors Copied
The process descriptors section contains a set of process descriptors. Each descriptor describes a particular process, and can be referenced by a Processes plug-in to start monitoring this process.
Mandatory: No
staticVars > processDescriptors > processDescriptor Copied
A process descriptor describes a process running on a machine, in such a way that the Processes plug-in can monitor it. This typically involves selecting unique elements of the executable name or command-line.
Mandatory: No
Refer to the Processes Plug-in User Guide for further information on process descriptors.
staticVars > processDescriptors > processDescriptor > name Copied
Each process descriptor in the static variables section must be uniquely named, so that the descriptor can be referenced uniquely from a Processes plug-in.
Mandatory: Yes
staticVars > processDescriptors > processDescriptorGroup Copied
A grouping mechanism to allow process descriptors to be logically grouped together.
Mandatory: No
staticVars > processDescriptors > processDescriptorGroup > name Copied
The name of the process descriptor group.
Mandatory: Yes
RMC Templates Copied
staticVars > rmcTemplates Copied
This section contains a set of RMC templates, which can be referenced by RMC‑Interface plug-ins. Each template describes a set of Reuters managed variables, which will be displayed by the plug-in.
Mandatory: No
staticVars > rmcTemplates > rmcTemplate Copied
An RMC template is used by the RMC‑Interface plug-in to describe what the plug-in should monitor. The template picks out a set of Reuters RMC managed variables as published by the data-source, which then form a view in the order specified in the template.
Mandatory: No
See the RMC Plug-in User Guide for further information on RMC templates.
staticVars > rmcTemplates > rmcTemplate > name Copied
Each RMC template in the static variables section must be uniquely named among all other templates. This allows the template to be unambiguously referenced from within an RMC‑Interface plug-in setup.
Mandatory: Yes
staticVars > rmcTemplates > rmcTemplateGroup Copied
A grouping mechanism to allow RMC templates to be logically grouped together.
Mandatory: No
staticVars > rmcTemplates > rmcTemplateGroup > name Copied
The name of the RMC template group.
Mandatory: Yes
Message Tracker Format Types Copied
staticVars > messageTrackerFormatTypes Copied
This section contains a set of Message Tracker Format Type templates, which can be referenced by the Message Tracker plug-in. Each message tracker format type template specifies a type of message to read.
Mandatory: No
staticVars > messageTrackerFormatTypes > messageTrackerFormatType Copied
A message tracker format type template. This specifies a type of message to read.
Mandatory: No
staticVars > messageTrackerFormatTypes > messageTrackerFormatType > name Copied
The name by which the message tracker format type template is referenced.
Mandatory: Yes
staticVars > messageTrackerFormatTypes > messageTrackerFormatTypeGroup Copied
A grouping mechanism to allow message tracker format type templates to be logically grouped together.
Mandatory: No
staticVars > messageTrackerFormatTypes > messageTrackerFormatTypeGroup > name Copied
The name of the message tracker format type template group.
Mandatory: Yes
staticVars > messageTrackerFormatTypes > messageTrackerFormatType > timestamp Copied
This specifies the location and format of the message timestamp.
Mandatory: Yes
staticVars > messageTrackerFormatTypes > messageTrackerFormatType > timestamp > regexPattern Copied
This specifies the location of the timestamp with the message. Data extracted by the applying the regular expression to the message and extracting the first group (the data the matches the regular expression within the first bracket) from the message. The system uses Perl regular expressions.
More information can be found at http://www.perl.com/doc/manual/html/pod/perlre.html
Mandatory: Yes
staticVars > messageTrackerFormatTypes > messageTrackerFormatType > timestamp > format Copied
This specifies the format of the timestamp. A full list of the available Time Formatting Parsing Codes is available in the Time Formats documentation.
Mandatory: Yes
Message Tracker Tag Mappings Copied
staticVars > messageTrackerTagMappings Copied
This section contains a set of Message Tracker Tag Mapping templates, which can be referenced by the Message Tracker plug-in. Each message tracker tag mapping template specifies a set of mappings from the tags provided by the formatType to a normalised message.
Mandatory: No
staticVars > messageTrackerTagMappings > messageTrackerTagMapping Copied
A message tracker tag mapping template. This specifies a set of mappings from the tags provided by the formatType to a normalised message.
Mandatory: No
staticVars > messageTrackerTagMappings > messageTrackerTagMapping > name Copied
The name by which the message tracker tag mapping template is referenced.
Mandatory: Yes
staticVars > messageTrackerTagMappings > messageTrackerTagMappingGroup Copied
A grouping mechanism to allow message tracker tag mapping templates to be logically grouped together.
Mandatory: No
staticVars > messageTrackerTagMappings > messageTrackerTagMappingGroup > name Copied
The name of the message tracker format type template group.
Mandatory: Yes
staticVars > messageTrackerTagMappings > messageTrackerTagMapping > IDs > item Copied
This creates a named ID from a set of tags. These tags will be user defined if the format type selected was Regex. The tags will be defined by the format type reader for other format types. For example, when using Fix the tags will be the numeric FIX tags. Please see the ITRS provided documentation for the format type being used (see the information on Data Normalization in the Message Tracker Plug-in User Guide). An ID should be unique for the message. Two messages are considered to be the same message if they share an ID with the same name and the same value.
Mandatory: No
staticVars > messageTrackerTagMappings > messageTrackerTagMapping > IDs > item > format Copied
This allows the tags to be combined together in a user specified way. If the format is not specified then the tag values are placed together space separated (see the information on User defined Tag combining in the Message Tracker Plug-in User Guide).
Mandatory: No
staticVars > messageTrackerTagMappings > messageTrackerTagMapping > attributes > item Copied
This creates a named attribute from a set of tags. These tags will be user defined if the format type selected was Regex. The tags will be defined by the format type reader for other format types. For example, when using Fix the tags will be the numeric FIX tags. Please see the ITRS provided documentation for the format type being used (see the information on Data Normalization in the Message Tracker Plug-in User Guide).
Mandatory: No
staticVars > messageTrackerTagMappings > messageTrackerTagMapping > attributes > item > format Copied
This allows the tags to be combined together in user specified way. If the format is not specified then the tag values are placed together space separated (see the information on User defined Tag combining in the Message Tracker Plug-in User Guide).
Mandatory: No
Fix-analyzer Templates Copied
staticVars > fix-analyzerTemplates Copied
This section contains a set of templates for use with the Fix-analyzer plugin.
Mandatory: No
staticVars > fix-analyzerTemplates > fix-analyzerTemplateGroup Copied
A grouping mechanism to allow Fix-analyzer templates to be logically grouped together.
Mandatory: No
staticVars > fix-analyzerTemplates > fix-analyzerTemplateGroup > name Copied
The name by which the Fix-analyzer template group is referenced.
Mandatory: Yes
User View Templates Copied
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate Copied
A template for a Fix-analyzer User View. User views are a customised view configured by the user. These views contain configuration settings for the rows and columns to be displayed. The column values can be computed statistics or values from either individual messages, or orders as detected by the plug-in.
Mandatory: No
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > name Copied
The name by which the Fix-analyzer User View template is referenced.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > viewName Copied
The viewName setting specifies the name of the view. View names must be unique across all views for a sampler, so that each view can be uniquely referenced.
Mandatory: Yes
Row configuration
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > rowIdentifier Copied
The row identifier setting specifies which part of a FIX message forms the row name which is displayed in a view.
For each message processed, the value for the
configured FIX field is extracted, and each unique
value creates a new row to be added to the view.
Messages then go on to update the statistics
(column values) for only the row whose field value
it matches. If a message does not have the
specified FIX field (or if the field has an empty
value) the text “
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > rowIdentifier > custom Copied
The custom row identifier allows the user to specify the FIX field tags, which will be extracted and used as the row name. Fixanalyzer allows for 2 levels of identifier tags, primary and secondary. Secondary tags can only be specified once a primary tag has been configured.
If both a primary and secondary row identifier
is configured, then the result is a view with 2
levels of row name. Row names of the form
“primaryValue#secondaryValue” are value rows,
and the statistics (column values) on this row
display values for those messages with matching
identifier fields. Row names of the form
“primaryValue” are summary rows,
and summarise the data of the sub-rows with the
same starting prefix.
Figure 24-1 A user view configured with a primary/secondary row identifier.
Figure 24-2 A user view configured with a primary only row identifier.
Mandatory: Yes - one of custom or senderTarget must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > rowIdentifier > senderTarget Copied
The senderTarget setting specifies that the view should use the FIX fields SenderCompId (49) and TargetCompId (56) for the row identifier.
If using these fields you may also optionally enable the session status columns, which allows you to create a customised session analysis view.
Mandatory: Yes - one of custom or senderTarget must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > rowIdentifier > senderTarget > showSessionStatus Copied
If enabled, this setting adds the columns status, logon and logoff to the user view. These columns are normally displayed in a session analysis view, so enabling these allows the user to configure a customised session analysis view using the user view.
Mandatory: No
Default: false - session status columns are not displayed.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > rowIdentifier > senderTarget > showSessionStatus > sessionTimeout Copied
The session timeout specifies a maximum period of inactivity for a session in seconds. If no messages are sent or received for this amount of time, then a session is considered to be timed out. This is displayed in the logoff column.
Timeouts are calculated by comparing the last message timestamp for that session against the local time on the Netprobe host.
Mandatory: No
Default: 0 - no timeout
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > rowIdentifier > senderTarget > showExpectedStatus Copied
This setting controls whether the expectedStatus column is displayed in the view. This column is normally present in a session analysis view if conversations have been configured. It can optionally be added to a user view to allow users to configure a customised session analysis view.
The expectedStatus column displays whether a session (senderTarget row) is expected to be up or down based on the time information configured in the conversation settings for the sampler. Values in this column will be empty unless conversations have been configured.
Mandatory: No
Default: false - expectedStatus column is not displayed.
Columns
The column configuration defines what data is displayed for each row in the dataview. Users can extract message or order values and compute selected statistics of these for display using the configuration described below.
User views currently support two types of column; message columns and order columns.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > displayName Copied
Specifies the name of the column as it will appear in the dataview. The name must be unique among all other columns configured for the view.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > rollingPeriod Copied
This setting allows a rolling period to be configured for the column. This allows you to - for example - configure a column that shows a count of messages received in the last 5 minutes.
Values are specified as an integer in 3 different units: seconds, minutes and hours. To configure a period of 1.5 hours for example, configure this as 90 minutes instead.
Mandatory: No
Default: No rolling period.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > filter Copied
References a filter from the filters section by name. Filters are applied to the data before the column processes the update. See the message column and order column sections for more details.
Mandatory: No
Default: No filter - column will process all updates.
Message columns
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > message Copied
Message columns process FIX messages individually when computing their statistics. There are 3 types of message column which can be configured; sum, count and value columns.
If a message column is configured with a filter, then only messages which pass the filter are processed by the column. Therefore, a count column configured in this way would count the number of messages which passed the filter.
Mandatory: Yes - a valid column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > message > type > sum Copied
The sum message column sums the values of the specified FIX fieldId, for all messages processed by this column (i.e. messages that passed the filter, if configured).
Summary rows for sum columns will display a sum of all values displayed for the sub-rows.
A sum message column could be used to obtain the total size (in bytes) of FIX messages processed for a particular party, by summing FIX field 9 (BodyLength).
Mandatory: Yes - one of sum, count or value must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > message > type > sum > fieldId Copied
This setting specifies the FIX field code for a sum column. Values for this field will be extracted and summed; therefore only numerical fields should be configured.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > message > type > count Copied
The count message column is an integer value which starts at zero, and increments by one for each message which is processed by the column (i.e. messages that passed the filter, if configured).
Summary rows for count columns will display a sum of all counts displayed for the sub-rows.
A count column could be used to could all rejected messages for a particular client, by configuring a filter to match on FIX field 35=9 (OrderCancelReject).
Mandatory: Yes - one of sum, count or value must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > message > type > value Copied
The value message column stores the extracted FIX fieldId or named value of the last message which was processed by the column (i.e. messages that passed the filter, if configured).
Summary rows for value columns will display the latest value (using the message timestamp) of the values displayed by the sub-rows.
A message value column could be used to show the latest error for a particular session, by extracting FIX field 58 (Text). This field is typically used to describe the error for a Don’t Know Trade (35=Q) or an order reject execution (35=8 and 150=8).
Mandatory: Yes - one of sum, count or value must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > message > type > value > fieldId Copied
This setting specifies the FIX field code for a value column. Values for this field will be extracted, and the latest value will be displayed.
Mandatory: Yes - one of fieldId or named must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > message > type > value > named Copied
This setting specifies an additional message property value to be used for a value column. Properties which can be configured are as follows:
| Property | Description |
|---|---|
| TimeStamp | The timestamp of the message in a human readable format.e.g. Thu Aug 23 14:55:02.148 2010. |
| SecondsSince | The number of seconds since the timestamp value, using the current local time of the Netprobe host. |
| MinutesSince | The number of minutes since the timestamp value, using the current local time of the Netprobe host. |
Mandatory: Yes - one of fieldId or named must be configured.
Order columns
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order Copied
Order columns display statistics for all orders which are applicable to the given dataview row. For example if the row configuration specifies that rows equate to exchanges, then order columns for a specific row will display statistics for orders to that exchange.
Order statistics can be filtered by current order status, as specified by the match states setting. This means that (unlike message columns) order columns can change value when a message is received but not processed for that particular row (since the message may change the order state). See the Order Tracking Appendix in the FIX-analyzer Plug-in User Guide for more details.
Filters for order columns are applied to the first message of the order seen for each dataview row, so that the order is only filtered once for that column.
Mandatory: Yes - a valid column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > count Copied
The count column shows the number of orders which pass the configured filter and order match states. An example usage of this column could be to display the number of open orders (i.e. states “new” or “partiallyFilled”) for that row.
Mandatory: Yes - a valid order-column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > value Copied
The value column shows the latest updated value for the specified FIX fieldId or named property, from orders which pass the configured filter and order match states.
Mandatory: Yes - a valid order-column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > value > fieldId Copied
The fieldId setting specifies a FIX field id, which will be used to extract values from FIX messages for use by an order column.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > value > named Copied
The named setting specifies a property which will be extracted from an order for use by an order column. Available properties are as follows:
| State | Description |
|---|---|
| ackLatency | The acknowledgementlatency in milliseconds. The time taken foran order to go from the “unacknowledged"state to the “new” state.e.g. The time between a 35=D FIX (single order) message and the first 35=8 (execution) reply message. |
| fillLatency | The fill latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to a finished state. |
| Status | The current order status, which will be checked against the match states configured for each order column. |
| Tracking | The current tracking status, used internally by Fix-analyzer. One of “New”, “Acknowledged” or “Finished”. |
For more detail on the order status, see the Order Tracking Appendix of the FIX-analyzer Plug-in User Guide.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > sum Copied
The sum column sums up the specified FIX fieldId or named properties extracted for all applicable orders, subject to the filters and order match states selected. Non-numeric values processed by this column may be converted to a number if they begin with a numeric prefix, but will otherwise be treated as zero.
An example usage for this column could be to sum FIX field 151 (LeavesQty) for all orders in states “new” or “partiallyFilled”. This would then show the total quantity for all orders, which are the shares remaining to be executed (per dataview row).
Mandatory: Yes - a valid order-column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > sum > fieldId Copied
The fieldId setting specifies a FIX field id, which will be used to extract values from FIX messages for use by an order column.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > sum > named Copied
The named setting specifies a property which will be extracted from an order for use by an order column. Available properties are as follows:
| State | Description |
|---|---|
| ackLatency | The acknowledgement latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to the “new” state.e.g. The time between a 35=D FIX (single order) message and the first 35=8 (execution) reply message. |
| fillLatency | The fill latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to a finished state. |
| Status | The current order status, which will be checked against the match states configured for each order column. |
| Tracking | The current tracking status, used internally by Fix-analyzer. One of “New”, “Acknowledged” or “Finished”. |
For more detail on the order status, see the Order Tracking Appendix of the FIX-analyzer Plug-in User Guide.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > max Copied
The max column displays the maximum FIX fieldId or named property value extracted for all applicable orders, subject to the filters and order match states selected.
A column of this type could be configured to display the maximum acknowledgement-latency for all orders of a dataview row.
Mandatory: Yes - a valid order-column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > max > fieldId Copied
The fieldId setting specifies a FIX field id, which will be used to extract values from FIX messages for use by an order column.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > max > named Copied
The named setting specifies a property which will be extracted from an order for use by an order column. Available properties are as follows:
| State | Description |
|---|---|
| ackLatency | The acknowledgement latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to the “new” state.e.g. The time between a 35=D FIX (single order) message and the first 35=8 (execution) reply message. |
| fillLatency | The fill latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to a finished state. |
| Status | The current order status, which will be checked against the match states configured for each order column. |
| Tracking | The current tracking status, used internally by Fix-analyzer. One of “New”, “Acknowledged” or “Finished”. |
For more detail on the order status, see the Order Tracking Appendix of the FIX-analyzer Plug-in User Guide.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > min Copied
The min column displays the minimum FIX fieldId or named property value extracted for all applicable orders, subject to the filters and order match states selected.
A column of this type could be configured to display the minimum acknowledgement-latency for all orders of a dataview row.
Mandatory: Yes - a valid order-column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > min > fieldId Copied
The fieldId setting specifies a FIX field id, which will be used to extract values from FIX messages for use by an order column.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > min > named Copied
The named setting specifies a property which will be extracted from an order for use by an order column. Available properties are as follows:
| State | Description |
|---|---|
| ackLatency | The acknowledgement latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to the “new” state.e.g. The time between a 35=D FIX (single order) message and the first 35=8 (execution) reply message. |
| fillLatency | The fill latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to a finished state. |
| Status | The current order status, which will be checked against the match states configured for each order column. |
| Tracking | The current tracking status, used internally by Fix-analyzer. One of “New”, “Acknowledged” or “Finished”. |
For more detail on the order status, see the Order Tracking Appendix of the FIX-analyzer Plug-in User Guide.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > average Copied
The min column displays the average of the FIX fieldId or named property values extracted for all applicable orders, subject to the filters and order match states selected.
A column of this type could be configured to display the average acknowledgement-latency for all orders of a dataview row.
Mandatory: Yes - a valid order-column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > average > fieldId Copied
The fieldId setting specifies a FIX field id, which will be used to extract values from FIX messages for use by an order column.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > average > named Copied
The named setting specifies a property which will be extracted from an order for use by an order column. Available properties are as follows:
| State | Description |
|---|---|
| ackLatency | The acknowledgement latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to the “new” state.e.g. The time between a 35=D FIX (single order) message and the first 35=8 (execution) reply message. |
| fillLatency | The fill latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to a finished state. |
| Status | The current order status, which will be checked against the match states configured for each order column. |
| Tracking | The current tracking status, used internally by Fix-analyzer. One of “New”, “Acknowledged” or “Finished”. |
For more detail on the order status, see the Order Tracking Appendix of the FIX-analyzer Plug-in User Guide.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > stdDev Copied
The min column displays the standard deviation of the FIX fieldId or named property values extracted for all applicable orders, subject to the filters and order match states selected.
A column of this type could be configured to display the standard deviation of acknowledgement-latency for all orders of a dataview row.
Mandatory: Yes - a valid order-column type must be configured.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > stdDev > fieldId Copied
The fieldId setting specifies a FIX field id, which will be used to extract values from FIX messages for use by order column.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > type > stdDev > named Copied
The named setting specifies a property which will be extracted from an order for use by an order column. Available properties are as follows:
| State | Description |
|---|---|
| ackLatency | The acknowledgement latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to the “new” state.e.g. The time between a 35=D FIX (single order) message and the first 35=8 (execution) reply message. |
| fillLatency | The fill latency in milliseconds. The time taken for an order to go from the “unacknowledged” state to a finished state. |
| Status | The current order status, which will be checked against the match states configured for each order column. |
| Tracking | The current tracking status, used internally by Fix-analyzer. One of “New”, “Acknowledged” or “Finished”. |
For more detail on the order status, see the Order Tracking Appendix of the FIX-analyzer Plug-in User Guide.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-user-viewTemplate > columns > column > columnType > order > matchStates Copied
This setting specifies the states of orders which will contribute towards the column value. Orders with a state that has not been configured here will not be considered by the column.
Possible states include:
| State | Description |
|---|---|
| unacknowledged | An order which has not been acknowledged by the other party. E.g. A Single Order message (35=D) for which no corresponding Execution message (35=8) has been seen. |
| new | An acknowledged order. |
| partiallyFilled | An order which has been partially filled. |
| filled | An order which has been completely filled. This state will also apply to an Order Cancel Request (35=F) which has succeeded. |
| replaced | An order which was replaced by a successful Order Cancel / Replace Request (35=G). |
| cancelled | An order which was cancelled by a successful Order Cancel Request (35=F). |
| rejected | An order which was rejected, or an Order Cancel Request (35=F) which was rejected by an Order Cancel Reject message (35=9). |
| finished | Provided for convenience of configuration |
- this state will match all filled, replaced, cancelled or rejected orders. |
For example, a count order column configured for the “unacknowledged” state would show a count of all unacknowledged orders. Orders which were subsequently acknowledged would then be removed from the count. By adding a filter to this count, we could (for example) count all unacknowledged orders to a particular exchange.
Mandatory: Yes
Message Detector View Templates Copied
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate Copied
A template for a Fix-analyzer Message Detector View. Message detector views extract and display the contents of “interesting” messages. They do this by dynamically adding new rows to the dataview when a message is detected which matches a configured filter. Each row in the dataview represents a message which passed the filter. The values displayed for the rows are determined by the user column configuration as detailed below.
Mandatory: No
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > name Copied
The name by which the Fix-analyzer Message Detector template is referenced.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > viewName Copied
The viewName setting specifies the name of the view. View names must be unique across all views for a sampler, so that each view can be uniquely referenced.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > filter Copied
The filter setting specifies the filter which will be used to determine “interesting” messages. Messages which pass the filter will be added to the message detector view as a new row.
The filter is referenced by name from the filters available to the plug-in. To filter on multiple “interesting” message types, combine multiple filters using the Boolean filter types (see the FIX-analyzer Plug-in User Guide for more information on filters).
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > messageTimeout Copied
The message timeout setting specifies how old a message can be (in seconds) before it is removed from the message detector view.
If the difference between the current time (obtained from the Netprobe host local time) and the message timestamp is larger than this threshold, then the row representing this message is removed from the view.
Mandatory: No
Default: 0 seconds - no timeout
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > messageCount Copied
The message count setting controls the maximum number of messages which will be displayed in a message group. A message group is a set of messages which share the same unique id. If the maximum limit is reached, a new incoming message will replace the oldest message in the group.
If the message count is set to zero, then the message group feature will be disabled and all messages displayed individually. If using this option, then it is recommended to ensure the row names are guaranteed to be unique by using the autoGenerated id type.
Mandatory: No
Default: 10 messages per group maximum
Row configuration
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > uniqueId Copied
The uniqueId setting specifies how to construct a unique row id (rowname) from a message for display in the message detector view.
The uniqueId is made up of one or more id elements, each of which can extract a FIX field or named property from the message. If using more than one id, the field values will be compounded together separated by dashes (the - character) to form the uniqueId.
If several messages are found with the same id, then the message detector will display these as sub-rows under a group row. This set of messages is then called a message group. The maximum number of messages per group can be configured using the messageCount setting.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > uniqueId > id > fieldId Copied
The fieldId setting specifies which FIX field to extract from a message. This value will then be used to form the uniqueId (the row name) in the message detector view.
Mandatory: Yes - one of fieldId, named or autoGenerated must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > uniqueId > id > named Copied
The named setting specifies a named FIX message property to extract. This value will then be used to form the uniqueId (the row name) in the message detector view.
Available properties are as follows:
| Property | Description |
|---|---|
| TimeStamp | The timestamp of themessage, in the format: Mon Sep 06 11:42:37.084 2010 |
| SecondsSince | The number of seconds elapsed since the message timestamp.
|
Mandatory: Yes - one of fieldId, named or autoGenerated must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > uniqueId > id > autoGenerated Copied
The autoGenerated setting generates a series of incrementing numbers starting from 1. These values will then be used to form the uniqueId (the row name) in the message detector view.
Users can use this setting if they are unsure whether the FIX fields they have specified as ids will be unique. If using only autoGenerated to create a unique id, it is recommended to disable the message group feature via the messageCount setting.
Mandatory: Yes - one of fieldId, named or autoGenerated must be specified.
Column configuration
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > columns Copied
The columns setting specifies the columns which will be displayed in this message analyzer view. For each message which passes the filter, fields from the message are extracted as per the column configuration and displayed as a new dataview row.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > columns > column > displayName Copied
Specifies the name of this column as it will appear in the dataview. Column names must be unique amongst all other columns configured for this message detector view.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > columns > column > value Copied
This setting specifies single column which will extract a value from the FIX message for display in a row. Values can be specified either as a FIX fieldId, or a named message property.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > columns > column > value > fieldId Copied
The fieldId setting specifies which FIX field to extract from a message. The resulting value will then be displayed as a column value in a new message detector row.
Mandatory: Yes - one of fieldId or named must be specified.
staticVars > fix-analyzerTemplates > fix-analyzer-message-detector-viewTemplate > columns > column > value > named Copied
The named setting specifies which named message property to extract from a message. The resulting value will then be displayed as a column value in a new message detector row.
Available properties are as follows:
| Property | Description |
|---|---|
| TimeStamp | The timestamp of the message, in the format: Mon Sep 06 11:42:37.084 2010 |
| SecondsSince | The number of seconds elapsed since the message timestamp, using the Netprobe host local time. |
| MinutesSince | The number of minutes elapsed since the message timestamp, using the Netprobe host local time. |
Mandatory: Yes - one of fieldId or named must be specified.
Session Analysis View Templates Copied
staticVars > fix-analyzerTemplates > fix-analyzer-session-analysis-viewTemplate Copied
A template for a Fix-analyzer Session Analysis View. The session analysis view displays the current status for the conversations on a monitored FIX engine. This view is useful for ensuring that specific connections remain up throughout the trading day. For more information, please refer to the Appendix on Session State Tracking in the FIX-analyzer Plug-in User Guide.
Each Fix-analyzer plug-in can have a single session analysis view, which is created when this setting is enabled.
Expected FIX conversations can be configured using the conversations sampler setting. This also allows other properties such as an alias to be specified. A start and end time can be specified for a conversation. Please see the FIX-analyzer Plug-in User Guide for more information about conversations.
Mandatory: No
staticVars > fix-analyzerTemplates > fix-analyzer-session-analysis-viewTemplate > name Copied
The name by which the Fix-analyzer Session Analysis template is referenced.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-session-analysis-viewTemplate > viewName Copied
The viewName setting specifies the name of the view. View names must be unique across all views for a sampler, so that each view can be uniquely referenced.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-session-analysis-viewTemplate > showSessionStatus Copied
Session settings
Mandatory: No
staticVars > fix-analyzerTemplates > fix-analyzer-session-analysis-viewTemplate > showSessionStatus > sessionTimeout Copied
The session timeout specifies a maximum period of inactivity for a session in seconds. If no messages are sent or received for this amount of time, then a session is considered to be timed out. This is displayed in the logoff column.
Timeouts are calculated by comparing the last message timestamp for that session against the local time on the Netprobe host.
Mandatory: No
Default: 0 - no timeout
Filter List Templates Copied
staticVars > fix-analyzerTemplates > fix-analyzer-filter-listTemplate Copied
A template for a Fix-analyzer Filter List. Filter lists allow filter definitions to be shared between samplers. This can help reduce the configuration burden (less filters need to be configured) and also increase maintainability by providing a single place to update when filters need to be changed.
Filters lists are configured in the top-level “Static variables” section of the gateway setup, inside the “Fix-analyzer templates” sub-section.
To use a filter list in a Fix-analyzer plug-in the list must be referenced by name. Filters defined in this list are then available for use by other parts of the plug-in setup, and are referenced by name in the same was as for normal filters.
Filter names inside a single sampler definition must be unique. If a filter in a filter list has the same name as another filter (defined in the same filter list, another referenced filter list, or directly in the plug-in configuration) then this is an error. The Netprobe log will contain diagnostic errors in this case
Mandatory: No
staticVars > fix-analyzerTemplates > fix-analyzer-filter-listTemplate > name Copied
The name by which the Fix-analyzer Filter List template is referenced.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-filter-listTemplate > filters Copied
List of filters held in a static variable. See the FIX-analyzer Plug-in User Guide for more information on filters.
Mandatory: Yes
staticVars > fix-analyzerTemplates > fix-analyzer-filter-listTemplate > filters > filter Copied
A filter within the list. See the FIX-analyzer Plug-in User Guide for more information on filters.
Mandatory: Yes
Signal Handling Copied
SIGUSR1 Copied
SIGUSR1 is a user defined POSIX reliable signal which is used by the Gateway to reload the Gateway Setup Files. When the gateway receives this signal it will reload its setup. This reload will occur if the files are unchanged and if the reloading time is in an inactive period. This is useful when a user wants to update the gateway setup file while updating the gateway setup file is restricted through GSE includes > reloading > activeTime option.
To deliver this signal, one can issue the following command from the command prompt:
kill -USR1 <gateway_PID>
SIGUSR2 Copied
SIGUSR2 is a user defined POSIX reliable signal which was historically used by the Gateway to run memory leak checks using purify. This has been discontinued and this signal is not intercepted anymore.
Required libraries Copied
The Linux version of the gateway currently requires the following libraries to run. These are listed along with the packages they can be found in for the following 64-bit operating systems.
CentOS / Redhat(64-bit) Copied
| Library Name | Package Name |
|---|---|
| libutil.so.1 | glibc-2.5-34.i686 |
| libnsl.so.1 | glibc-2.5-34.i686 |
| libpthread.so.0 | glibc-2.5-34.i686 |
| libdl.so.2 | libdl.so.2 |
| libcrypt.so.1 | glibc-2.5-34.i686 |
| libz.so.1 | zlib-1.2.3-3.i386 |
| libresolv.so.2 | glibc-2.5-34.i686 |
| libstdc++.so.5 | compat-libstdc++-33-3.2.3-61.i386 |
| libm.so.6 | glibc-2.5-34.i686 |
| libgcc_s.so.1 | libgcc-4.1.2-44.el5.i386 |
| libc.so.6 | glibc-2.5-34.i686 |
| ld-linux.so.2 | glibc-2.5-34.i686 |
Suse (64-bit) Copied
| Library Name | Package Name |
|---|---|
| libutil.so.1 | glibc-32bit-2.4-31.2 |
| libnsl.so.1 | glibc-32bit-2.4-31.2 |
| libpthread.so.0 | glibc-32bit-2.4-31.2 |
| libdl.so.2 | glibc-32bit-2.4-31.2 |
| libcrypt.so.1 | glibc-32bit-2.4-31.2 |
| libz.so.1 | zlib-32bit-1.2.3-15.2 |
| libresolv.so.2 | glibc-32bit-2.4-31.2 |
| libstdc++.so.5 | compat-libstdc++-5.0.7-22.2 |
| libm.so.6 | glibc-32bit-2.4-31.2 |
| libgcc_s.so.1 | libgcc-4.1.0-28.4 |
| libc.so.6 | glibc-32bit-2.4-31.2 |
| ld-linux.so.2 | glibc-32bit-2.4-31.2 |
Setup Merging Rules Copied
- Rule 1: All setup sections are merged recursively if they do not have the attribute name or ref e.g.
Main Setup file priority 1 (highest priority)
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<includes>
<priority>1</priority>
<include>
<priority>2</priority>
<required>true</required>
<location>probes.setup.xml</location>
</include>
</includes>
<probes>
<probe name="windows">
<hostname>aWindowsMachine</hostname>
<port>9001</port>
</probe>
</probes>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
Included Setup file priority 2 (lowest priority)
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<probes>
<probe name="solaris">
<hostname>aSolarisMachine</hostname>
<port>9000</port>
</probe>
</probes>
</gateway>
Merged Setup file
<?xml version="1.0" encoding="iso-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<probes>
<probe name="windows">
<hostname>aWindowsMachine</hostname>
<port>9001</port>
</probe>
<probe name="solaris">
<hostname>aSolarisMachine</hostname>
<port>9000</port>
</probe>
</probes>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
The merged setup shows that the sections gateway and probe have been merged. The probe section now contains “windows” and “Solaris”.
- Exception 1: Unless the setup section has to be overridden i.e. tickerEventLogger e.g.
Main Setup file priority 1 (highest priority)
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<includes>
<priority>1</priority>
<include>
<priority>2</priority>
<required>true</required>
<location>ticker.setup.xml</location>
</include>
</includes>
<tickerEventLogger>
<maxEvents>25</maxEvents>
<cacheFileSize>55</cacheFileSize>
<cachePaths>
<cachePath>./resources/tickereventloggerA.cache</cachePath>
<cachePath>./resources/tickereventloggerB.cache</cachePath>
</cachePaths>
</tickerEventLogger>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
Included Setup file priority 2 (lowest priority)
<?xml version="1.0" encoding="iso-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<tickerEventLogger>
<maxEvents>30</maxEvents>
<cacheFileSize>55</cacheFileSize>
<cachePaths>
<cachePath>./resources/tickereventlogger1.cache</cachePath>
<cachePath>./resources/tickereventlogger2.cache</cachePath>
</cachePaths>
</tickerEventLogger>
</gateway>
Merged Setup file
<?xml version="1.0" encoding="iso-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<tickerEventLogger>
<maxEvents>25</maxEvents>
<cacheFileSize>55</cacheFileSize>
<cachePaths>
<cachePath>./resources/tickereventloggerA.cache</cachePath>
<cachePath>./resources/tickereventloggerB.cache</cachePath>
</cachePaths>
</tickerEventLogger>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
The merged setup shows that only one tickerEventLogger section is present, this is because the main setup file has the highest priority.
- Rule 2: All setup sections are overridden if they do have an attribute name or ref e.g.
Main Setup file priority 1 (highest priority)
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<includes>
<priority>1</priority>
<include>
<priority>2</priority>
<required>true</required>
<location>probes.setup.xml</location>
</include>
</includes>
<probes>
<probe name="windows">
<hostname>aWindowsMachine</hostname>
<port>9001</port>
</probe>
</probes>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
Included Setup file priority 2 (lowest priority)
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<probes>
<probe name="solaris">
<hostname>aSolarisMachine</hostname>
<port>9000</port>
</probe>
<probe name="windows">
<hostname>anotherWindowsMachine</hostname>
<port>9500</port>
</probe>
</probes>
</gateway>
Merged Setup file
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<probes>
<probe name="windows">
<hostname>aWindowsMachine</hostname>
<port>9001</port>
</probe>
<probe name="solaris">
<hostname>aSolarisMachine</hostname>
<port>9000</port>
</probe>
</probes>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
The merged setup shows that there is only one probe section named “windows”. The probe section “windows” in the included setup file has been overridden; this is because the main setup has the highest priority.
- Exception 2: Unless they are a special case i.e. a section that is a group type (managedEntityGroup, probeGroup, samplerGroup and ruleGroup)
Main Setup file priority 1 (highest priority)
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<includes>
<priority>1</priority>
<include>
<priority>2</priority>
<required>true</required>
<location>groups.setup.xml</location>
</include>
</includes>
<probes>
<probe name="windows">
<hostname>aWindowsMachine</hostname>
<port>9002</port>
</probe>
<probe name="solaris">
<hostname>aSolarisMachine</hostname>
<port>9003</port>
</probe>
</probes>
<managedEntities>
<managedEntityGroup name="Department 1">
<managedEntity name="ME1">
<probe ref="windows"/>
</managedEntity>
<managedEntityGroup name="Sub Department 1">
<managedEntity name="ME2">
<probe ref="windows"/>
</managedEntity>
</managedEntityGroup>
</managedEntityGroup>
<managedEntityGroup name="Department 2">
<managedEntity name="ME3">
<probe ref="solaris"/>
</managedEntity>
</managedEntityGroup>
</managedEntities>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
Included Setup file priority 2 (lowest priority)
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<probes>
<probe name="aix">
<hostname>anAixMachine</hostname>
<port>9001</port>
</probe>
<probe name="linux">
<hostname>aLinuxMachine</hostname>
<port>9000</port>
</probe>
</probes>
<managedEntities>
<managedEntityGroup name="Department 1">
<managedEntity name="ME5">
<probe ref="aix"/>
</managedEntity>
<managedEntityGroup name="Sub Department 1">
<managedEntity name="ME2">
<probe ref="linux"/>
</managedEntity>
</managedEntityGroup>
<managedEntityGroup name="Sub Department 2">
<managedEntity name="ME7">
<probe ref="aix"/>
</managedEntity>
</managedEntityGroup>
</managedEntityGroup>
<managedEntityGroup name="Department 2">
<managedEntity name="ME8">
<probe ref="linux"/>
</managedEntity>
</managedEntityGroup>
</managedEntities>
</gateway>
Merged Setup file
<?xml version="1.0" encoding="iso-8859-1"?>
<gateway xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation=".\resources\schema\gateway.xsd">
<includes>
<priority>1</priority>
<include>
<priority>2</priority>
<required>true</required>
<location>groups.setup.xml</location>
</include>
</includes>
<probes>
<probe name="windows">
<hostname>aWindowsMachine</hostname>
<port>9002</port>
</probe>
<probe name="solaris">
<hostname>aSolarisMachine</hostname>
<port>9003</port>
</probe>
<probe name="linux">
<hostname>aLinuxMachine</hostname>
<port>9000</port>
</probe>
<probe name="aix">
<hostname>anAixMachine</hostname>
<port>9001</port>
</probe>
</probes>
<managedEntities>
<managedEntityGroup name="Department 1">
<managedEntity name="ME1">
<probe ref="windows"/>
</managedEntity>
<managedEntityGroup name="Sub Department 1">
<managedEntity name="ME2">
<probe ref="windows"/>
</managedEntity>
</managedEntityGroup>
<managedEntityGroup name="Sub Department 2">
<managedEntity name="ME7">
<probe ref="aix"/>
</managedEntity>
</managedEntityGroup>
<managedEntity name="ME5">
<probe ref="aix"/>
</managedEntity>
</managedEntityGroup>
<managedEntityGroup name="Department 2">
<managedEntity name="ME3">
<probe ref="solaris"/>
</managedEntity>
<managedEntity name="ME8">
<probe ref="linux"/>
</managedEntity>
</managedEntityGroup>
</managedEntities>
<operatingEnvironment>
<gatewayId>100</gatewayId>
<gatewayName>A Gateway</gatewayName>
<listenPort>8500</listenPort>
</operatingEnvironment>
</gateway>
The merged setup shows that “Department 1” and “Department 2” have been merged. “ME5” has been added to “Department 1”. “Sub Department 2” contains “ME2” from the main setup file as it has overridden “ME2” in the included setup file and lastly “ME8” has been added to “Sub Department 2”.
Time Zone Data Copied
The Gateway binary is accompanied by a time zone
resources file, date\_time\_zonespec.csv, derived from
the time zone database
maintained by IANA. This file, which is best viewed using
spreadsheet software, lists the names and abbreviations
for the timezones known to the Gateway.
The time zone names can be used when configuring ActiveTime periods, scheduled events, and in Time arguments in Internal Commands. The time zone abbreviations can be used when defining rules to parse and format strings containing timestamps.
Important:
-
Time zone abbreviations, such as “EST” are inherently ambiguous. By default, when the Gateway has to map an abbreviation to a time zone, it will take the first match. That is, it will use the time zone whose full name comes first in alphabetical order. This can be overridden by setting up time zone abbreviations in the Operating Environment setup of the Gateway.
-
The time zone resources file includes columns “DST Start Date rule” and “DST End Date rule”. These encode the rules used to find the dates when Daylight Savings Time starts and ends. Each rule is represented by three numbers separated with semicolons, for example “-1;5;9”.
The first number indicates the “nth” weekday of the month. The possible values are: 1 (first), 2 (second), 3 (third), 4 (fourth), 5 (fifth), and -1 (last). The second number indicates the day-of-week from 0-6 (Sun=0). The third field indicates the month from 1-12 (Jan=1).
For example, “-1;5;9” means “Last Friday of September” and “2;1;3” means “Second Monday of March”.
-
Because some countries use DST rules that cannot be encoded this way and because the file format cannot represent historic changes in the rules or changes announced more than a year in advance, the file is regenerated from time to time. The latest version is included with each release of the Gateway.
Using Secure Passwords on the Gateway Copied
Types of password offered by the Gateway and how to generate them Copied
There are a number of places where it is possible to specify passwords in your setup to access external resources or to access secure commands for example. The Gateway supports four methods of specifying passwords.
- One way
-
Encoded passwordsThese are one way hashes used to specify the netprobe passwords. This is essentially the Unix crypt format.
The Gateway Setup Editor can configure and transmit this password to the netprobe for you. Alternatively the start netprobe script can supply a password by setting the ENCODED_PASSWORD environment variable. This is well documented in the template. To encrypt the password using the gateway, use:
-
gateway -pw <password>
-
Two wayWhen interfacing with external systems It is necessary to securely encrypt the password within the setup but decrypt them when necessary so that we can supply the password to an external API such as an interface to a database. The Gateway currently supplies three ways of supplying these passwords.
- AES 256 bit Encryption (stdAES)This is the most secure method currently offered by the Gateway. As the name suggests this uses 256 key to produce a hash of the password.
The Gateway Setup Editor will handle the encrypting for you but if you’re generating your setup dynamically or manually editing the XML for some reason you can use the Gateway to generate your passwords using:
gateway -aes256-encrypt <password>
- Geneos Standard Encoding (std)This encodes (rather than encrypts) the password so that it is not immediately apparent what the password is. However this does not offer the level of protection that encrypting the password would.
The Gateway Setup Editor will handle this encoding for you however you can use the Gateway to generate these from the command line using:
gateway -en <password>
- Plain text (plain-text)This allows you to enter passwords without any encryption. This is not advised and is only provided for testing purposes.
Securing your Gateway with a supplied key Copied
It is recommended that you use the most secure method of storing your passwords possible within your configuration. Currently this is an AES 256 implementation.
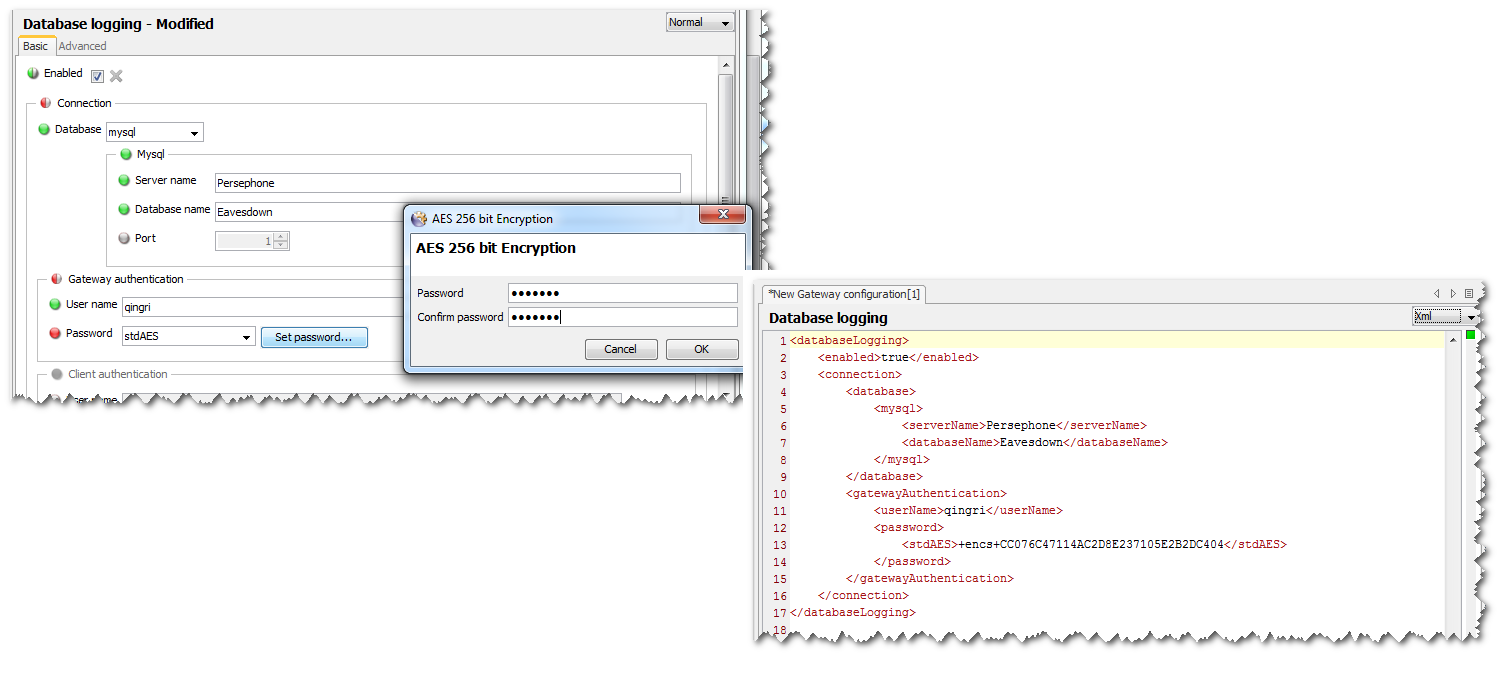
By default the gateway uses a default key. You may wish to supply your own key to increase the security of your passwords.
Warning: When you do this any existing AES 256 encrypted passwords will no-longer be valid.
To do this you start the Gateway with a -key-file
An AES 256 key actually has two parts a key and an initialisation vector. You can generate this using the openssl tool on the command line.
For example.
>openssl enc -aes-256-cbc -k "Now is the winter of our discontent" -P -md sha1
salt=359D12769B1F9446
key=92358925C00DE524B4F325A7F488DF1F29646313F6D258090818E8C9B69CF4D8
iv =B8B606E4700FE4D05E24E1A682F5963D
You should see a different result each time you run this command. The Gateway -key-file parameter specifies a file that has “key=…” and “iv =…” lines. You can either copy these lines into a file or redirect the output of this command into a file. However if the output of this command changes you will need to reformat into a valid key file.
To protect you from unintentionally starting the Gateway with a different key file from one used previously, the Gateway stores an MD5 hash of the key file in its cache. The Gateway will refuse to start if this hash does not match the MD5 hash of the file specified on the Gateway command line.
If no key file is specified the default hash is used and this is noted in the cache.
Note
The gateway will refuse to start if there is already a hash and this is not the default.
If you wish to start the Gateway with a key file that is not the same as the previous (remember if no previous then the default is assumed) you will need to start the gateway with the -skip-cache parameter to avoid this check. The new MD5 hash will be written to the cache for next time. This allows you to change your key with the proviso that all exiting passwords will have been invalidated.
Given that you can start a Gateway with a different key you also need a way to generate passwords on the command line using this key. The -aes256-encrypt option has been extended to use a key file.
gateway -aes256-encrypt <password> [-key-file <key-file>]
Note
Do not edit the key file while the Gateway is running. The Gateway will detect the change and generate an error at whatever reload interval is set. Remember that all passwords in the setup will need to be re-entered if this file is changed.
Assuming a linux gateway a real example command line could look like:
gateway2.linux -aes256-encrypt PassW0rd -key-file shh.aes
This command does what exactly what we say the Gateway Setup Editor do in Figure 44-1 - Gateway Setup Editor Generating Encrypted Password. It generates a password that can be added to a Gateway’s XML setup. The -key-file option ensures that the users specified key is used and not the Gateway’s default.
Merged Setup Copied
Assume the gateway main file has contents:
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway compatibility="1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://schema.itrsgroup.com/RAmaster-140930/gateway.xsd">
<includes>
<priority>1</priority>
<include>
<priority>2</priority>
<required>true</required>
<location>inc1.example.setup.xml</location>
</include>
<include>
<priority>3</priority>
<required>true</required>
<location>inc2.example.setup.xml</location>
</include>
</includes>
<probes>
<virtualProbe name="vp1"/>
</probes>
<managedEntities>
<managedEntityGroup name="meG">
<managedEntity name="me1">
<probe ref="p1"/>
<sampler ref="cpu"/>
</managedEntity>
</managedEntityGroup>
</managedEntities>
<samplers>
<samplerGroup name="SamplerGroup">
<sampler name="FKM2">
<plugin>
<fkm>
<isPCREMode>
<data>true</data>
</isPCREMode>
</fkm>
</plugin>
</sampler>
</samplerGroup>
</samplers>
<tickerEventLogger>
<maxEvents>8</maxEvents>
<cacheFileSize>8</cacheFileSize>
</tickerEventLogger>
<operatingEnvironment>
<gatewayName>testGateway</gatewayName>
<listenPort>7039</listenPort>
</operatingEnvironment>
</gateway>
And include file inc1.example.setup.xml has contents:
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway compatibility="1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://schema.itrsgroup.com/RAmaster-140930/gateway.xsd">
<probes>
<probe name="p1">
<hostname>127.0.0.21</hostname>
</probe>
<probe name="p2">
<hostname>127.0.0.22</hostname>
</probe>
</probes>
<managedEntities>
<managedEntity name="me1">
<probe ref="p1"/>
<sampler ref="FKM"/>
</managedEntity>
<managedEntity name="me2">
<probe ref="p2"/>
<sampler ref="cpu"/>
</managedEntity>
</managedEntities>
<samplers>
<sampler name="FKM">
<plugin>
<fkm/>
</plugin>
</sampler>
<sampler name="cpu">
<plugin>
<cpu/>
</plugin>
</sampler>
</samplers>
<tickerEventLogger>
<maxEvents>1</maxEvents>
<cacheFileSize>1</cacheFileSize>
</tickerEventLogger>
</gateway>
And include file inc2.example.setup.xml has contents:
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway compatibility="1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://schema.itrsgroup.com/RAmaster-140930/gateway.xsd">
<probes>
<probe name="p1">
<hostname>127.0.0.23</hostname>
</probe>
</probes>
<managedEntities>
<managedEntityGroup name="meG">
<managedEntity name="me1">
<probe ref="p1"/>
<sampler ref="processes"/>
</managedEntity>
</managedEntityGroup>
</managedEntities>
<samplers>
<samplerGroup name="SamplerGroup">
<sampler name="processes">
<plugin>
<processes/>
</plugin>
</sampler>
</samplerGroup>
</samplers>
<operatingEnvironment>
<gatewayName/>
<httpConnectionRequirements>
<internalData>
<acceptHosts>
<all/>
</acceptHosts>
</internalData>
</httpConnectionRequirements>
</operatingEnvironment>
</gateway>
Then the merged setup will look like:
<?xml version="1.0" encoding="ISO-8859-1"?>
<gateway compatibility="1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="http://schema.itrsgroup.com/RAmaster-140930/gateway.xsd" main="true">
<includes main="true">
<priority>1</priority>
<include>
<priority>2</priority>
<required>true</required>
<location>inc1.example.setup.xml</location>
</include>
<include>
<priority>3</priority>
<required>true</required>
<location>inc2.example.setup.xml</location>
</include>
</includes>
<probes main="true">
<virtualProbe name="vp1" main="true"/>
<probe name="p2" include="inc1.example.setup.xml">
<hostname>127.0.0.22</hostname>
</probe>
<probe name="p1" include="inc1.example.setup.xml">
<hostname>127.0.0.21</hostname>
</probe>
</probes>
<managedEntities main="true">
<managedEntityGroup name="meG" main="true">
<managedEntity name="me1" main="true">
<probe ref="p1"/>
<sampler ref="cpu"/>
</managedEntity>
</managedEntityGroup>
<managedEntity name="me2" include="inc1.example.setup.xml">
<probe ref="p2"/>
<sampler ref="cpu"/>
</managedEntity>
<managedEntity name="me1" include="inc1.example.setup.xml">
<probe ref="p1"/>
<sampler ref="FKM"/>
</managedEntity>
</managedEntities>
<samplers main="true">
<samplerGroup name="SamplerGroup" main="true">
<sampler name="FKM2" main="true">
<plugin>
<fkm>
<isPCREMode>
<data>true</data>
</isPCREMode>
</fkm>
</plugin>
</sampler>
<sampler name="processes" include="inc2.example.setup.xml">
<plugin>
<processes/>
</plugin>
</sampler>
</samplerGroup>
<sampler name="cpu" include="inc1.example.setup.xml">
<plugin>
<cpu/>
</plugin>
</sampler>
<sampler name="FKM" include="inc1.example.setup.xml">
<plugin>
<fkm/>
</plugin>
</sampler>
</samplers>
<tickerEventLogger main="true">
<maxEvents>8</maxEvents>
<cacheFileSize>8</cacheFileSize>
</tickerEventLogger>
<operatingEnvironment main="true">
<gatewayName main="true">testGateway</gatewayName>
<listenPort main="true">7039</listenPort>
<httpConnectionRequirements include="inc2.example.setup.xml">
<internalData>
<acceptHosts>
<all/>
</acceptHosts>
</internalData>
</httpConnectionRequirements>
</operatingEnvironment>
</gateway>
Decoding Encrypted Environment Variables Copied
The Gateway can be given a key file which is used to encrypt secure password fields. If you are intending to send your own encrypted environment variables to a toolkit you will have to supply your own key file. The Gateway can use it’s own key but for obvious reasons we do not supply a means for a third party to decrypt these.
To recap you can generate and use a key file as follows.
openssl enc -aes-256-cbc -k "Now is thewinter of our discontent" -P -md sha1 >key-file
./active/gateway2.linux -aes256-encrypt 12345 -key-file key-file -skip-cache
The “-skip-cache” is needed only the first time you wish to change the key file.
Step one produces a key file that is required for follow on steps, and is required for the gateway to run with AES passwords, so don’t misplace it. The password 12345 is then encrypted and the gateway will produce the following output in hexadecimal.
Encoded text:
+encs+69B1E12815FA83702F0016B0E7FBD33B
You will need to convert the hexadecimal back to base64, for use with openssl, as well as provide the contents of the aforementioned key-file, in order to decrypt your string.
The following is a bash example of how to do this. Usage:
./decode.sh +encs+69B1E12815FA83702F0016B0E7FBD33B
decode.sh
#!/bin/bash
hex=${1#*+encs+}
salt=$(grep salt key-file)
key=$(grep key key-file)
iv=$(grep iv key-file)
echo ${hex}| xxd -r -p | base64 | openssl enc -d -aes-256-cbc -S ${salt#*=} -K ${key#*=} -iv ${iv#*=} -a
To convert an environment variable replace the ‘1’ in the second line with the name of the environment variable. All encrypted variables start with “+encs+ so this removes the prefix prior to decoding.
Note
xxd is part of the vim-common package which you may have to install separately.