If you are currently using version 5.x.x, we advise you to upgrade to the latest version before the EOL date. You can find the latest documentation here.
Publisher
Overview
The Publisher plug-in enables you to publish data from an FKM outbound stream to an index on any of the following:
-
Elasticsearch host
-
Splunk server
The Publisher plug-in supports the following versions:
| Destination | Version/s |
|---|---|
| Elasticsearch | 6.2.4 to 7.4.1 |
| Splunk server | 7.3.1 |
Intended audience
This guide is directed towards Geneos users who want to publish data from a configured FKM outbound stream to any of the following:
-
Elasticsearch server
-
Splunk server
As a user, you should be familiar with the use and capability of the FKM plug-in, the Elasticsearch API, and Splunk.
Prerequisites
Java requirements
- You must have Java installed on the machine running the Netprobe. For information on supported Java versions, see Java support in 5.x Compatibility Matrix.
- Once you have Java installed, configure the environment variables required by the Netprobe so that it can locate the required resource files. For guidance, see Configure the Java environment.
Caution: The Java installation and environment configuration is a common source of errors for users setting up Java-based components and plug-ins. It is recommended to read Configure the Java environment to help you understand your Java installation.
Elasticsearch credentials
If you are looking to publish data to Elasticsearch, then you need the following:
- Elasticsearch server host name or IP address
- Elasticsearch server port
- Elasticsearch server credentials, if applicable
You must also be familiar with Elasticsearch API, as well as how it is implemented in your organisation.
Setup and configuration
Setup involves the following tasks:
- Create the Publisher sampler.
- Associate the Publisher sampler with a managed entity.
- Publish an outbound stream from the FKM sampler.
Note: If you are using this plugin with Gateway Hub, you must create a user defined data schema. For instructions, see Create a data schema.
Create the Publisher sampler
- In the Gateway Setup Editor, create a new sampler by right-clicking the Samplers folder and selecting New Sampler.
- Enter a name for this sampler in the Name field.
- In the Plugin field, click the drop-down list and select publisher.
- In the Destination field, click the drop-down list and select
- collectionAgent if you want to publish to Collection Agent. To configure, follow the steps in Publisher
- elasticsearch if you want to publish to Elasticsearch server. To configure, follow the steps in Configure the Elasticsearch destination.
- Click Save current document
 to apply your changes.
to apply your changes.
Success: The sampler can now be associated with a managed entity.
Configure the Elasticsearch destination
If you are publishing to Elasticsearch, configure the plugin as follows:
- In the Host field, enter the Elasticsearch server host name or IP address.
- In the Port field, enter the port number.
- In the Index field, enter the Elasticsearch index where you want to add the JSON document.
- If you want to change the
_typeendpoint, specify the endpoint in the Endpoint field. - If you want to use an HTTPS connection between the Publisher sampler and the Elasticsearch host, select
Httpsunder Protocols. - If authentication is needed to access the Elasticsearch host, click Authentication > Type and select
Basic.- In the Username field, enter the Elasticsearch host username.
- In the Password field, enter the Elasticsearch host password. You can toggle between setting and encrypting a password (
stdAES) or defining a variable (var).
Note: You can toggle between data and var for the Host and Port fields. This toggle option allows you to define either a text or numerical value (data) or variable (var) for these fields.
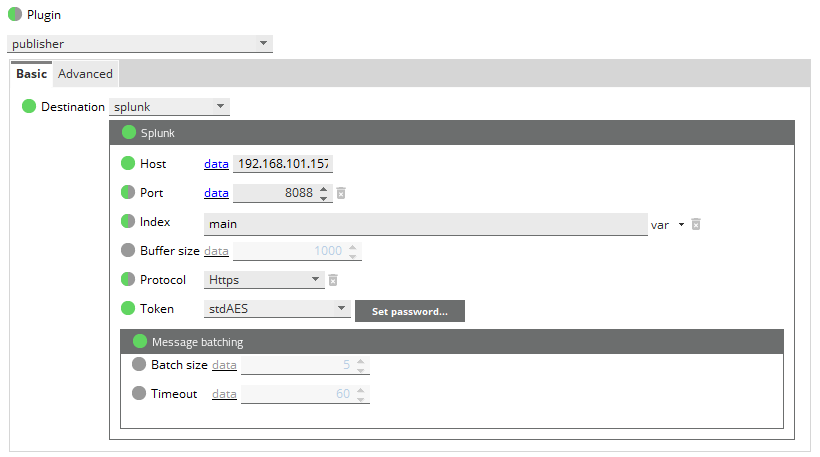
Configure the Splunk destination
'If you are publishing to Splunk, configure the plugin as follows:
- In the Host field, enter the Splunk server host name or IP address.
- In the Port field, enter the port number.
- If you want to change the index, specify the index where you want to add the JSON document in the Index field.
- If you want to change the batch size, specify the value in the Batch size field.
- In the Token field, input the HEC token or a variable.
Note: You can toggle between data and var for the Host and Port fields. This toggle option allows you to define either a text or numerical value (data) or variable (var) for these fields.
Associate the sampler with a managed entity
- In the Gateway Setup Editor, create a new managed entity by right-clicking the Managed entities folder and selecting New Managed entity.
- Enter a name for this managed entity. For example, enter "publisher-me" in the Name field.
- In the Options field, select the probe on which you want the sampler to run.
- Under the Sampler field, click Add new.
- In the text field under Ref, select the sampler you just created from the drop-down list.
- Click Save current document to apply your changes.
Success: The Publisher Admin dataview now appears under the managed entity in the Active Console state tree.
Publish an outbound stream from the FKM sampler
- In the Gateway Setup Editor, locate and select the FKM sampler you wish to publish an outbound stream from.
- In Files, click inside the Outbound stream name field for the source you want to publish from.
- In the Outbound stream name field, specify the Publisher sampler you have just created. The format must follow a fully qualified stream name:
- Click Save current document to apply your changes.
managedEntity-name.publisher-sampler(type)
For example:
ME.Publisher
Note: The managed entity part of the format can be omitted if the sampler falls under the same managed entity as the FKM sampler.
Success: The Publisher sampler now receives outbound stream messages coming from the configured FKM sampler.
Elasticsearch Admin View
The Publisher sampler automatically creates the Admin view to monitor the status of its streams, if there are any.
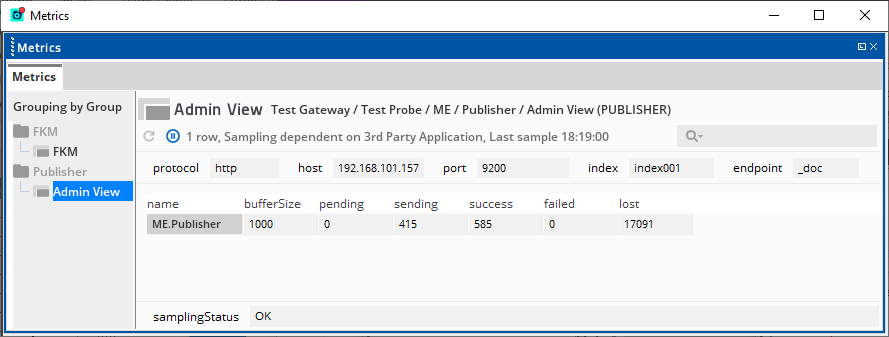
Headline legend
| Name | Description |
|---|---|
| protocol | Connection protocol used. For example, HTTP or HTTPS. |
| host | Elasticsearch server host name or IP address that the Publisher sampler is connected to. |
| port | Elasticsearch server port that the Publisher sampler is connected to. |
| index |
Elasticsearch index where the stream data is published. This field conforms to the Elasticsearch REST API. For more information, see the Index API page of theElasticsearch Reference. |
| endpoint |
Elasticsearch This field conforms to the Elasticsearch REST API. For more information, see the Index API page of the Elasticsearch Reference. |
Table legend
| Name | Description |
|---|---|
| name | Name of the FKM outbound stream tied to the Publisher sampler. |
| bufferSize |
Number of messages that the sampler holds in the stream. The sampler holds these messages until they are consumed by another sampler. |
| pending | Number of messages waiting to be consumed by the Publisher sampler from the native stream. |
| sending | Number of messages waiting to be received by Elasticsearch from the Publisher sampler. |
| success |
Number of messages successfully published to Elasticsearch. |
| failed | Number of messages that failed to be published to Elasticsearch. This can be due to an issue with the schema, or the connection dropping between the Publisher sampler and the Elasticsearch host. |
| lost |
Total number of messages that did not reach the Publisher sampler. This can be due to the buffer filling up too quickly. Lost messages indicate that you may need to increase the Buffer size or throttle the FKM sampler. |
Note: Stream messages are stored in the buffer until they are consumed by another component. However, If there are no samplers or clients consuming the stream, then the stream registry purges the messages immediately.
Basic configuration
A Publisher sampler receives its stream from a corresponding FKM sampler. If you wish to assign an outbound stream to a Publisher sampler, see File Keyword Monitor configuration in File Keyword Monitor configuration.
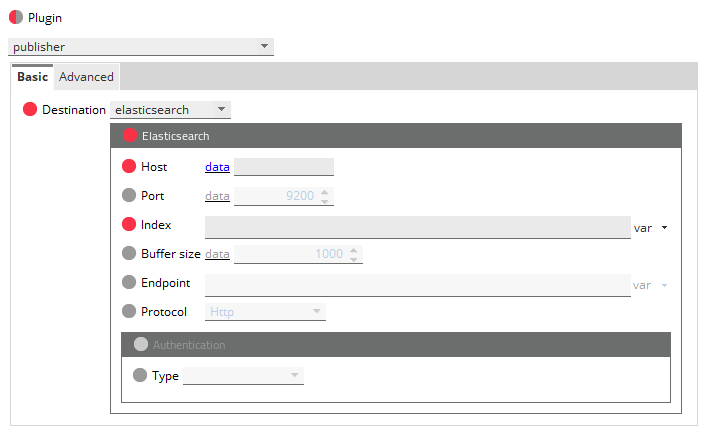
Note: You can safely update the configuration of this plug-in without causing the Netprobe to restart.
Note: If you are using this plugin with Gateway Hub, you must create a user defined data schema. For instructions, see Create a data schema.
| Configuration option | Description |
|---|---|
| Host |
Elasticsearch server host name or IP address. You can toggle between entering a text or numerical value ( Mandatory: Yes |
| Port |
Elasticsearch server port. You can toggle between entering a numerical value ( Mandatory: No Default: |
| Index |
Index where you want to add the JSON document. This field conforms to the Elasticsearch REST API. For more information, see the Index API page of the Elasticsearch Reference. Mandatory: Yes |
| Buffer size |
Sets the maximum number of messages that the Publisher sampler holds in memory at a time. Messages clear the buffer when the stream is received by the Elasticsearch server. Mandatory: No Default: |
| Endpoint |
Elasticsearch This option conforms to the Elasticsearch REST API. For more information, see the Index API page of the Elasticsearch Reference. Mandatory: No |
| Protocol |
Connection protocol to use. By default, this is HTTP. Use HTTPS if you want to set a secure connection. Mandatory: No |
| Authentication |
Authentication method to use. The Publisher plug-in supports the following authentication types:
Mandatory: No |
Advanced configuration
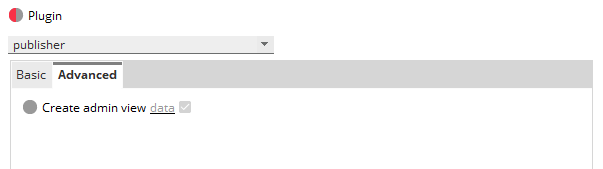
| Field | Description |
|---|---|
| Create admin view |
Enables or disables the Elasticsearch Admin View on the managed entity. The Admin view is enabled by default. You can toggle between a checkbox ( Default: Enabled |
Bearer authentication
The bearer authentication option enables you to connect to an Elasticsearch server via token API, without needing basic authentication.
The Publisher sampler supports the bearer authentication password grant type, as defined in the Elasticsearch API. For detailed information, see the Get token API page of the Elasticsearch Reference.
password
This grant type implements the OAuth 2.0 resource owner password credentials grant. A trusted user (the grantor) can either retrieve a token for their own use, or on behalf of an end-user (the grantee).

Splunk Admin View
The Publisher sampler automatically creates the Admin view to monitor the status of its streams, if there are any.
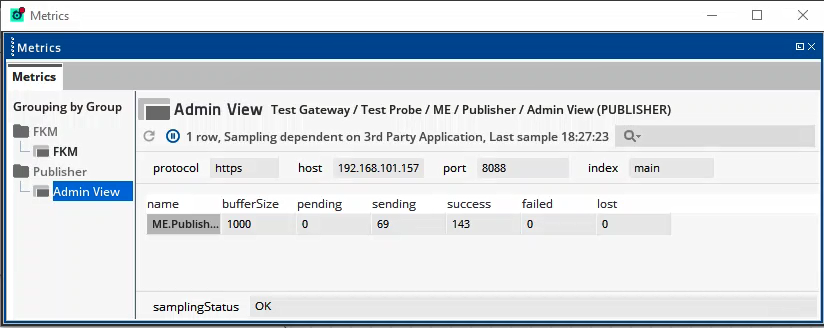
Headline legend
| Name | Description |
|---|---|
| protocol | Connection protocol used. For example, HTTP or HTTPS. |
| host | Splunk server host name or IP address that the Publisher sampler is connected to. |
| port | Splunk HEC port that the Publisher sampler is connected to. |
| index |
Splunk index where the stream data is published. |
Table legend
| Name | Description |
|---|---|
| name | Name of the FKM outbound stream tied to the Publisher sampler. |
| bufferSize |
Number of messages that the sampler holds in the stream. The sampler holds these messages until they are consumed by another sampler. |
| pending |
Number of messages waiting to be consumed by the Publisher sampler from the native stream. Note: Incoming messages are counted as pending until the Batch size is reached. |
| sending | Number of messages waiting to be received bySplunk from the Publisher sampler. |
| success |
Number of messages successfully published to Splunk. |
| failed | Number of messages that failed to be published to Splunk. This can be due to an issue with the schema, or the connection dropping between the Publisher sampler and the Collection Agent host. |
| lost |
Total number of messages that did not reach the Publisher sampler. This can be due to the buffer filling up too quickly. Lost messages indicate that you may need to increase the Buffer size or throttle the FKM sampler. |
Note: Stream messages are stored in the buffer until they are consumed by another component. However, If there are no samplers or clients consuming the stream, then the stream registry purges the messages immediately.
Basic configuration
A Publisher sampler receives its stream from a corresponding FKM sampler. If you wish to assign an outbound stream to a Publisher sampler, see File Keyword Monitor configuration in File Keyword Monitor configuration.
Note: You can safely update the configuration of this plug-in without causing the Netprobe to restart.
Note: If you are using this plugin with Gateway Hub, you must create a user defined data schema. For instructions, see Create a data schema.
Advanced configuration
| Field | Description |
|---|---|
| Create admin view |
Enables or disables the sampler Splunk Admin View on the managed entity. Default: Enabled |