Opsview 6.8.x End of Support
With the release of Opsview 6.11.0 on February 2025, versions 6.8.x have reached their End of Support (EOS) status, according to our Support policy. This means that versions 6.8.x will no longer receive code fixes or security updates.
The documentation for version 6.8.9 and earlier versions will remain accessible for the time being, but it will no longer be updated or receive backports. We strongly recommend upgrading to the latest version of Opsview to ensure continued support and access to the latest features and security enhancements.
Concept of IT Monitoring
The essence of IT monitoring can be summarized in a single goal – to ensure that all your IT equipment is up and performing to the level expected of it.
In the basic monitoring solutions available, this is achieved by simply sending a ‘ping’ to the host and awaiting a response. If a response is obtained, then you can be assured that the host (server/router/switch, etc.) is up and hasn’t been powered off, crashed etc. This function provides you with a simple view into your IT estate and ensures that the things that should be up, are running.
More advanced monitoring solutions allow more detailed views into the operational status of those hosts, for example, “I know that my server is up and running. What I want to do now is make sure that the hard drive doesn’t run out of space.”. In Opsview Monitor terminology this is called a Service Check; checking that the hard drive is working, that the CPU is not 100% busy, etc., and this approach ties nicely into the philosophy of active monitoring. This concept is extended still further to model and monitor significantly more complex environments, from user experience testing to application performance, synthetic transactions, virtualization and containerization.
Monitoring philosophy: A hierarchical approach Copied
Monitoring has an intrinsic hierarchy in that certain objects must exist in a certain order. For example, in order to monitor your server’s C: drive, we must first monitor your server. However, sometimes the syntax and naming are very confusing, given that it often differs from vendor to vendor. Some call the server a “host” or a “monitor”, and some call the C: drive style checks “monitors”, “service checks”, “counters”, etc. At Opsview we use “Host” to mean a physical or virtual server/device/network point and “Service Check” to mean an action seeking information on a specific aspect of a Host. This syntax should become clearer as we step through each of the “three layers” - Foundation layer, Interpretation layer and Monitoring layer.
The foundation layer Copied
The first of our three layers is the “Foundation Layer”. This layer of monitoring forms the basis of the advanced monitoring done later on. Here you monitor your physical or virtual devices, called Hosts – such as a Windows server, Linux server, Cisco router, Nokia firewall, VMware virtual machine, etc and these are often the lowest level of the ‘stack’. You ensure they are up by pinging them, and so on.

Once configured, this provides you with a view such as the image shown above, where the hosts you have added and their state is shown, such as which ones are UP or DOWN – allowing you to see if a device has crashed, been powered off erroneously, and so on.
The monitoring layer Copied
Once you know the physical/virtual Hosts are up, you’ll next want to monitor items on each of them. These items could include:
- Linux servers: Swap space, CPU Usage, file system usage, Service running, etc.
- Windows servers: Pagefile size, memory usage, CPU Usage, C: drive space, processes, etc.
- Network device: Throughput on interfaces, CPU load, memory, etc.
- VMware/Virtualization: Datastore free space, temperature checks, number of VMs, CPU utilization, etc.
We refer to these items as Service Checks and they run against the hosts that you configured and specified in the Foundation layer. A common scenario is:
“I’ve added my Windows Server, ‘windows001.domain.com’, as a Host and I can see that it is up (step 1). I want to monitor some items on it, so I’ll add a ‘C: Drive’ check, a ‘CPU Check’, and a ‘Memory Check’, along with a few others. Now I can not only see that my host is up, but I’m also monitoring performance items on that server, giving me a better view into its operational performance”.
This gives insight into server health and performance. However, the issue you may have now is that to manually add 100 Hosts (e.g. Windows servers) and then six Service Checks to each of those Hosts, could take a long time.
Therefore, to save time, Opsview Monitor groups these Service Checks together into a Host template (named for example “Windows Servers”), into which we can add lots of Service Checks. This template can then be applied en-masse to all the Windows servers, reducing the time-to-value significantly.

So now that we have templates to reduce our time-to-value, our only time-consuming task is adding these Hosts “hostname by hostname”. Again, innovation in monitoring has made this an unnecessary evil through the creation of auto discovery.
Auto discovery, in its most simplistic form, allows a monitoring system to “go out” and scan a predefined subnet or network and find devices on that network. In the Windows example, you can scan the subnet and discover all Hosts on that network and import them into the Opsview Monitor software, ready to be modified and associated with host templates.
In Opsview Monitor, we can even determine the Operating System and apply templates automatically based on the results, meaning the time-to-value is extremely low. We can go out onto a network, find all the Hosts, detect what that Host is, and then apply a number of Service Checks in the form of a Host template, automatically.
The interpretation layer Copied
Now that we are monitoring our Hosts and the services running on them, we can start to be intelligent with the interpretation of the data; i.e. “how do we present this so that we can clearly see that a problem is occurring?”.
Commonly in IT, servers and network devices are part of larger systems such as business applications, websites, services, etc and these are the items we are really concerned about, rather than the individual elements that they consist of.
For example, if I run a website selling product XYZ, I want to know when this website and what in this website, is impacted by an issue in any of the IT components that are used in the delivery of the website. We know that this website is made up of a few Apache web servers, running on two Linux servers, connected to the internet via a router and a switch, and also relying on a DNS server. In the “monitoring layer” outlined in the previous section, we are using Service Checks to monitor performance metrics for each of these areas individually:
- Apache: number of requests per second, number of worker processes, etc.
- Linux servers: CPU load, memory usage, hard disk drive space, temperature, etc.
- Switch/Router: CPU load, memory usage, interface throughput, packets per second, etc.
- DNS Server: DNS service running, performance counters, queues, etc.
This gives us a great view into how each of these Hosts is doing. What we want now is to look at it holistically; as a website rather than a series of objects. To do this, monitoring software vendors and application performance monitoring (APM) vendors have created “business service monitoring” (BSM).
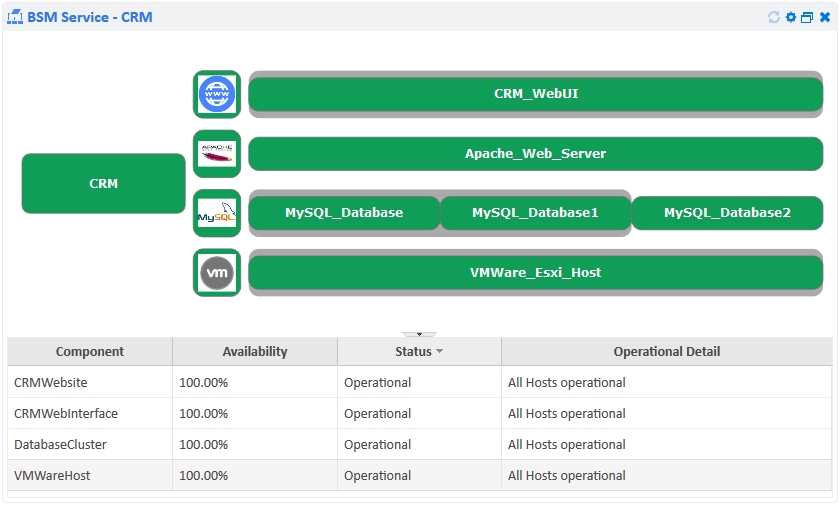
The purpose of these business services is to allow you a view into the performance of your business applications ‘as a whole’ rather than having to look at all the individual Hosts and work it out for yourself. This capability is what differentiates a basic monitoring tool from an enterprise-class one, such as Opsview Monitor. This ability to measure, interpret and manage services and “top-down views” delivers much greater value to the sysadmin. An example of a BSM view is shown below.
In Opsview Monitor, we have two features which help you with this; Business Service Monitoring (BSM) and Hashtags.
BSM allows you to monitor your true business service, i.e. the website, application, etc instead of looking at all the individual Hosts and Service Checks underneath. This allows you to set up notifications only on Business Services, so instead of getting emails every five minutes about ‘This individual server is using too much memory’, you will only get a notification when your Business Service is impacted (i.e. something critical within this Business Service has failed that may impact its performance), or if the Business Service is DOWN. This significantly reduces the ‘alert fatigue’ and ensures you only get notifications when you really need them.
A business service is an important part of your business, such as your public website. This will consist of multiple components, which are groups of Hosts with similar Service Checks. Opsview Monitor will calculate the state of components, taking into account redundancy and failover, so that you can get up to date information of each layer. This is then aggregated to the business service level to give overall health for business and technical owners, as shown in the image above.
The second feature provided in Opsview Monitor for aggregated analytics is Hashtags. Hashtags work the same as within popular social media websites such as Twitter® and Facebook®, in that you can add a Hashtag to various objects within Opsview Monitor and then notify/grant access/view information, based on the Hashtag.
For example, if you have a data center called ‘Texas01’, you could tag every Host and Service Check within that data center with the Hashtag ‘#texas01’. You can then view via the ‘Hashtags’ section within Opsview Monitor, the health of the Texas data center as below:
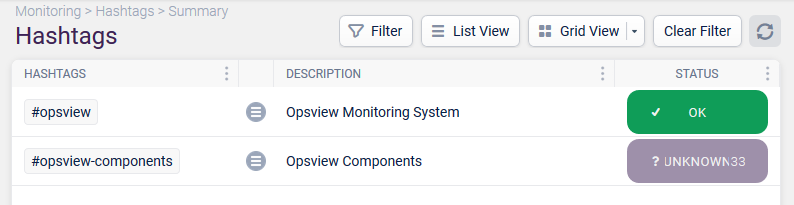
In the above example, we can see that there is a Service Check or Host within our Texas data center that is in a problem state (i.e. CRITICAL, DOWN, etc.).
Once you have configured your Hashtags and Business Services, not only can you monitor based upon them – i.e. using the above views to see the actual “health” of your Website / Data Center, but you can use these Hashtags/Business Services within other sections of Opsview Monitor. One example is filtering the ‘Events Viewer’ to show events that have happened only on objects tagged with a given Hashtag, as shown below:
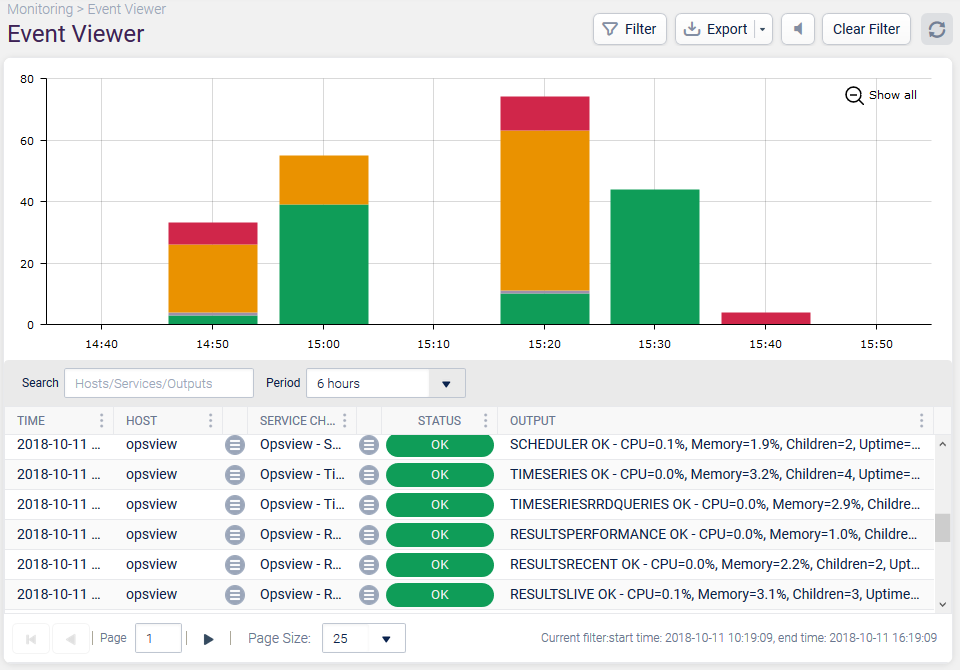
This allows you to see all the events that have happened on any piece of hardware/software (applications through to the switches), that are related to the performance of your data center, website, etc.
These Hashtags/Business Services can also be used within the ‘Graph Center’, to display graphically all the Service Checks tagged with a given Hashtag or all the Service Checks that are within a given component:
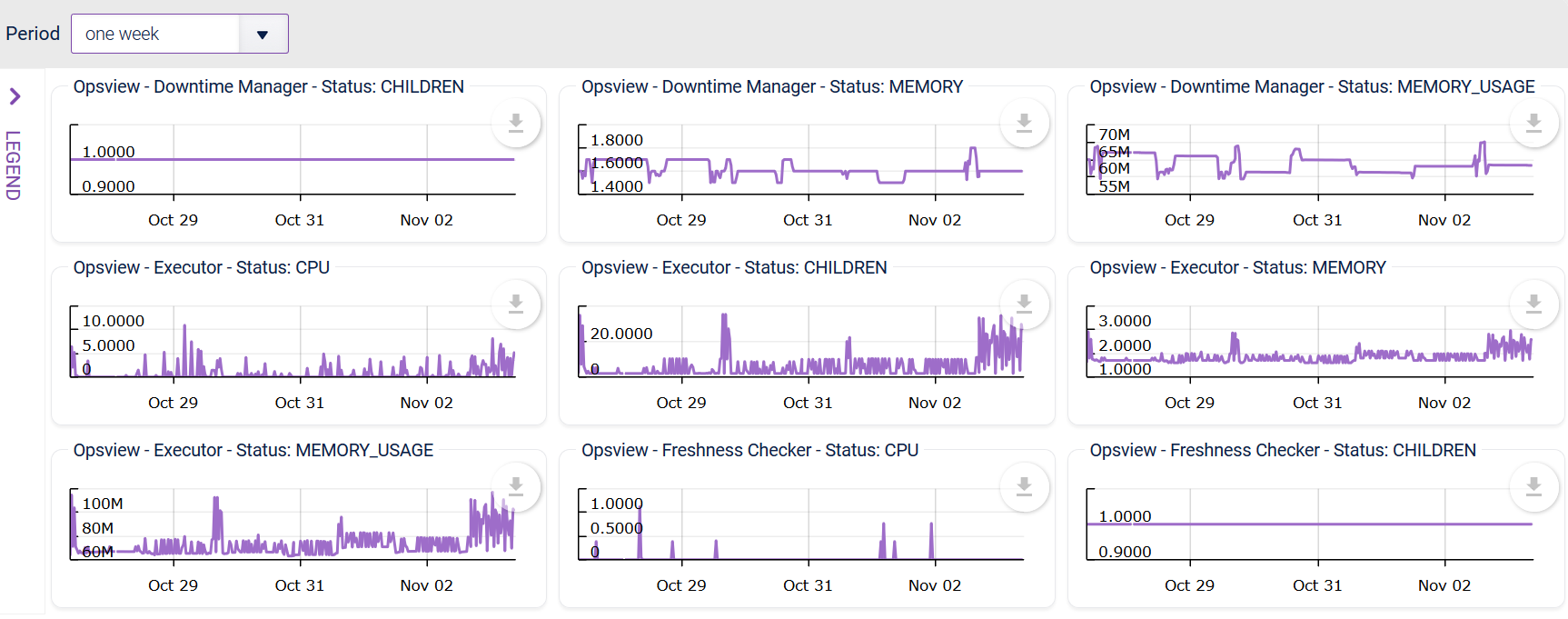
Finally, Hashtags / Business Services can also be used in the Reports section, to show the historical health of a Hashtag/Business Service in a number of standard business reports, such as SLA reports or cost of downtime reports, through to technical reports such as performance reports, availability reports, etc.
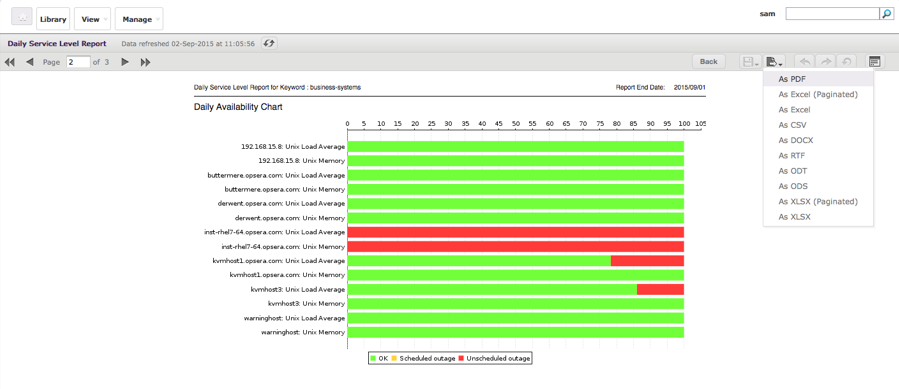
Reports can also be automated, so that you can see at configurable time intervals, such as the start of each month / every day, the performance/availability/cost of downtime for any pre-defined Hashtag, delivered in a .pdf format and carrying your brand – directly into your inbox or a manager’s inbox!
Closing thoughts Copied
This section has demonstrated how monitoring functions within a tiered approach, from simple monitoring of whether a device is responsive, through using business service monitoring (BSM) to view the health of services, to reporting the cost and availability impact of incidents.
- Pro-active problem resolution using Event Handlers.
- Maintenance periods using Scheduled Downtime.
- Network analysis using Network Analyzer.
- Access control using Hashtags / Business Services / more.
- Multi-tenancy.
- Notifications using one of 13 different notification methods, such as Slack or Email.
These topics are all explored in detail in User Interface.