File Keyword Monitor configuration
Plugin configuration Copied
The File Keyword Monitor or FKM plugin can be configured to run on any Netprobe host. Configuration should consist of at least one file to be monitored, which will provide basic statistics about the file. Key tables can optionally be configured for additional scanning of file lines for keys. To share key tables between multiple files, configure key tables in a static variables section and reference these for each file.
View Copied
This plug-in produces a single view that consists of all information which can be displayed by FKM. A customized list of columns can be specified via the Plugin Configuration setting.
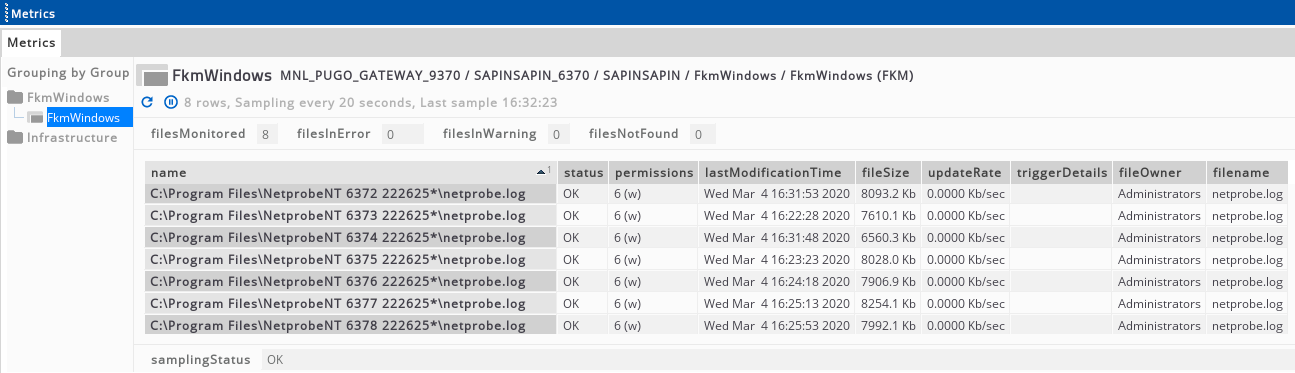
Headline legend Copied
| Name | Description |
|---|---|
| filesMonitored | Number of files currently being monitored by FKM |
| filesInError | Number of files which are in an error (fail) state |
| filesInWarning | Number of files which are in a warning state |
| filesNotFound | Number of files which could not be opened (typically because they do not exist and could not be found) |
Table legend Copied
| Name | Description |
|---|---|
| name | The name of the file being monitored by FKM. This may be post-fixed by the tag “#fail” or “#warning” followed by a number. In this case, the row indicates a trigger that was found by a keyword match in the file. |
| status | The overall status of the file. For files, this will show OK, WARNING, FAIL or NOT_FOUND to indicate the current state. When a trigger is detected for the file, the overall file status is set to the highest alert of all triggers. The text from the latest trigger can optionally be shown in this column. The status column is blank for trigger rows. |
| permissions | A display of file permissions. These are shown in octal with a human-readable version to the right. This column appears blank for NT event logs, streams, and triggers.
444 (-r--r--r-). Otherwise, you may encounter an error message. In addition, the directories leading up to the file need at least 555 (r-xr-xr-x) permissions to traverse to the file. For guidance, see Monitor a source a file in FKM.
|
| lastModificationTime | For files this column shows the last time the file was modified. For triggers the time the trigger was detected is shown. For streams the time shown is the last time a message was received. For NT event logs this column appears blank. |
| fileSize | The current size of the file. The column appears blank for stream, NT event logs and triggers. |
| updateRate | This shows the update rate of the file, averaged over the sample interval. This gives an indication of how fast the file is growing or shrinking. |
| triggerDetails | This column is only populated for trigger rows. It shows a keyword message (if configured) and the line of the file which contains the detected keyword. |
| secondsSinceLastTrigger | The number of seconds since a trigger was last detected for this file. This value is updated every sample interval. |
| triggerCount | The trigger count displays the number of triggers detected for a file.
|
| filename | The current filename of the monitored file. For files with wildcards in the name, this will show the file currently being monitored otherwise it appears the same as the name column described above. |
| absolutePath | Shows the absolute path to the file (includes the directory and the filename). |
| secondsSinceLastModified | The number of seconds (at the time of sampling) since the file was last modified. For trigger rows, this column shows the number of seconds since the trigger was detected. |
| < additional user-defined > | Additional user-defined columns may also appear when using extractors. |
File configuration Copied
This section describes the FKM settings related to file configuration.
Caution
The FKM plug-in always opens and scans a file for reading, and scans each incoming line. The FKM plug-in performs these tasks even if you choose not to define search keys. Therefore, you should not use the FKM plug-in to detect core files, as it reads core files as if they were text files. Core file detection is better served by a toolkit.
files Copied
This section defines the files that will be monitored by the FKM plug-in. Files can either be defined directly in the sampler configuration, referenced as a static variable, or included from a sampler include.
Mandatory: No
files > file Copied
Specifies a single file to be monitored. The filename or alias should be unique so that this file can be uniquely identified in the published view, and to enable unique identification in gateway rules (for example).
files > file > path Copied
The full path to the file.
Example:
/usr/data/FileX.dat
If <today> (including the < > brackets) is specified as part of the file name, then it will result in the automatic substitution of the date in yyyymmdd format.
Additionally, you can include one or more formatting codes to format the date, such as <today%d%m%Y>.
Also, in place of the <today> keyword, you can use these keywords when specifying the filename:
| Date keyword | Description |
|---|---|
<today...> |
Current date. |
<today+x...> |
Current date + x days This keyword does not take monitored days into account, and counts the actual number of days from the current date. |
<today-x...> |
Current date − x days This keyword does not take monitored days into account, and counts the actual number of days leading up to the current date. |
<yesterday...> |
Actual date yesterday. If monitored days are configured, then this keyword counts the previous monitored day with respect to monitored days, similar to the previous_monitored_day keyword. |
<tomorrow...> |
Actual date tomorrow. If monitored days are configured, then this keyword counts the next monitored day with respect to monitored days, similar to the next_monitored_day keyword. |
<previous_monitored_day...> |
Previous monitored day with respect to monitored days. If monitored days are not configured, then weekends will not be considered as holidays. |
<previous_monitored_day-x...> |
Previous monitored day minus the previous x number of monitored days. This includes the holidays and monitored days. |
<next_monitored_day...> |
Next monitored day with respect to monitored days. If monitored days are not configured, then weekends will not be considered as holidays. |
<next_monitored_day+x...> |
Next monitored day plus the next x number of monitored days. This includes the holidays and monitored days. |
Date keyword expansions
When using the +x or -x values into the date keywords to offset the date on the filename, note the following behaviours when introducing spaces (depicted as the ␣ character) in formatting:
| Date keyword expansion format | Behaviour and outcome |
|---|---|
<today␣> |
Ignores the space and uses the default %Y%m%d format. If the date today is 30 June 2018, then the outcome is: 20180630.dat |
<today␣%Y␣%m␣%d␣> |
Ignores the spaces around the date format, but includes the spaces in-between. If the date today is 30 June 2018, then the outcome is: 2018 06 30.dat |
<today␣+␣10␣> |
Ignores the spaces and uses the default %Y%m%d format. This format also offsets by the value of the number indicated. If the date today is 30 June 2018, then the outcome is: 20180710.dat |
<today␣+␣1␣0␣> |
Offsets by the value of the first digit, and interprets the subsequent digit as the format string. As a consequence, this format renders the offset invisible, even though the offset is in effect due to the first digit. Regardless of the date, the outcome is: 0.dat |
<today␣+␣1␣0␣%Y-%m-%d␣> |
Offsets by the value of the first digit, and interprets the subsequent digit as part of the %Y-%m-%d format. If the date today is 30 June 2018, then the outcome is: 0 2018-07-01.dat |
The limitations for offset to today, previous_monitored_day-x, and next_monitored_day+x path keywords are set to:
- Lower bound: -3650
- Upper bound: 3650
The invalid offsets get an expanded value equivalent to the base tag. If you have <previous_monitored_day-3651>, then the date becomes <previous_monitored_day>.
| Formatting code | Description |
|---|---|
| %a | Abbreviated weekday name. |
| %A | Full weekday name. |
| %b | Abbreviated month name. |
| %^b | Abbreviated month name (but capitalised). |
| %B | Full month name. |
| %d | Day of month as decimal number (01 - 31). |
| %j | Day of year as decimal number (001 - 366). |
| %m | Month as decimal number (01 - 12). |
| %U | Week of year as decimal number, with Sunday as first day of week (00 - 53). |
| %w | Weekday as decimal number (0 - 6; Sunday is 0). |
| %W | Week of year as decimal number, with Monday as first day of week (00 - 53). |
| %x | Date representation for current locale. |
| %y | Year without century, as decimal number (00 - 99). |
| %Y | Year with century, as decimal number. |
| %Z | Time-zone name or abbreviation; no characters if time zone is unknown. |
Examples:
| Configured | Equivalent (if date is 24 September 2003) |
|---|---|
| filename<today%d%m%Y>.txt | filename24092003.txt |
| filename<today%d%b%Y>.txt | filename24Sep2003.txt |
| filename<today%d%^b%Y>.txt | filename24SEP2003.txt |
| filename<today%d-%b-%Y>.txt | filename24-Sep-2003.txt |
Mandatory: Yes
files > file > source Copied
The source setting specifies where the monitored file data comes from.
Mandatory: Yes
files > file > source > filename Copied
Selecting this setting specifies that the file monitored is a file on disk. The value of this setting specifies the location of the file. Relative paths will be evaluated from the Netprobe working directory.
If a filename contains wildcard characters, then FKM will automatically check for creation of newer files matching the wildcard pattern. When a new file is detected (provided the current file has been scanned to the end) FKM will then switch to monitor the newer file.
There are two types of wildcard specifications which can be used:
- Globbing using
\*and?characters, as typically used in a UNIX shell session. e.g.apache\*.log - Filename date generation using the current date / time. e.g.
app<today%Y%m%d>.log
If in case the monitored file is rolled-over, i.e. current monitored file has been renamed and a new file is created with the original filename, FKM will continue to read the renamed file to the end as long as a new file with the original filename exists. After reading the renamed file to the end, it will start reading the new file.
Note
File roll-over monitoring on Windows only works if netprobe is run with admin privileges and if the file is in an NTFS file system. Otherwise, FKM will not be able to follow the renamed file up to the end and may result to missing lines after the file has been rolled over.
Caution
When you use the*and?wildcard expressions, the files > file > alias configuration does not work and the dataview displays the source name, instead.
files > file > multiline Copied
Specifies if a message should be matched across multiple lines. Messages that are on a single line will also be matched.
Mandatory: No
files > file > multiLine > startPattern Copied
A regular expression that matches the start of a multi line message. Specify the regex pattern in the Regex field.
files > file > multiLine > startPattern > data > flags Copied
Optionally configure the regex with flags that change the pattern-matching behavior.
The available flag is i, which indicates that the regex matching is done in a case-insensitive manner. For example, the letter “A” in the regex pattern will match both “A” and “a” (in both upper and lower case).
files > file > multiLine > messageEnd > endPattern Copied
A regular expression that matches the end of a multi line message. Specify the regex pattern in the Regex field.
The start and end pattern will scan single lines as well as multi line messages. If a start and end pattern match on the same line, the start pattern must appear before the end pattern.
files > file > multiLine > messageEnd > endPattern > data > flags Copied
Optionally configure the regex with flags that change the pattern-matching behavior.
The available flag is i, which indicates that the regex matching is done in a case-insensitive manner. For example, the letter “A” in the regex pattern will match both “A” and “a” (in both upper and lower case).
files > file > multiLine > messageEnd > maxNumberOfSamplesToWait Copied
A multi line message is considered to be complete if another start pattern is found e.g. the start pattern in this case is “Start” and 2 complete multi line messages have been found.
Start Message 1 Message 2
Start Message 3 Message 4
Or if the maximum number of samples to wait has been exceeded. This setting has been included to capture the last message in a file as there is no start pattern to end the last message.
files > file > source > stream Copied
Selecting this setting specifies that the file to be monitored is a stream. The stream can be from a Netprobe or a Collection Agent plugin.
The stream name should be in the following format:
| Source | Format | Example |
|---|---|---|
| Collection Agent | If the FKM sampler is created under Dynamic Entity, the format is Otherwise, for FKM samplers not under Dynamic Entity, the format is
|
For FKM under Dynamic Entity: For FKM not under Dynamic Entity: |
| Other sources | managedEntityName.samplerName.streamName |
ME.rest-api.stream1 |
If the sampler of the Netprobe or Collection Agent plugin is under the same Managed Entity as the FKM plugin sampler, then the managedEntity can be omitted in the stream name.
Wildcard expressions Copied
This configuration supports wildcard expressions for streams coming from any source such as REST API plugin and Collection Agent. Supported wildcard characters are * and ?. These wildcard characters can be used both on the sampler name and stream name.
If the special characters * and ? exist in a stream name, then the wildcard expression cannot detect those streams.
When you use wildcard expressions for stream names, then the stream rows are added to the FKM dataview as these are detected.
Caution
When you use the*and?wildcard expressions, the files > file > alias configuration does not work and the dataview displays the source name, instead.
files > file > source > ntEventLog Copied
Selecting this setting specifies that the file monitored is an NT event log. Event logs are only available in Netprobes running on a Microsoft Windows system.
There are usually three default event logs present on a Windows system, named Application, Security and System. Other applications may install their own custom event logs, with a custom log name.
The drop down menu will only contain the three default event logs. To specify a custom event log, type in the full name of the event log into the drop down menu field. The name specified should match the full name of the event log found in the Properties window of the event log in the Windows event viewer.
files > file > source > processDescriptor Copied
Selecting this setting specifies that the file monitored is the log file for a process monitored by a PROCESSES plug-in. The value specified should be the name of a processDescriptor definition in the static variables section of the gateway setup. FKM will then monitor the file specified in the logFile setting of this process descriptor.
files > file > source > dynamicFiles Copied
The dynamicFiles file source type configures FKM to match groups of files based on the configured path, pattern, and optionally the alias.
When a new group is identified, an additional file row is created which behaves as a normal filename source. Settings for this new row are copied from the settings of the parent dynamicFiles row. The row will be removed when no files remain to create that grouping.
This feature is similar to using a normal filename source with the wildcardMonitorAllMatches setting, but the two features cannot be used in conjunction. FKM will report an error if you attempt to do this.
Groups are specified using the path setting, which should be a file path containing wildcard globbing characters (\* and ?). This path will be evaluated, and all files discovered will then be matched against the configured regex pattern.
The name of a row in the view is determined by evaluating the file alias. Any numbered inserts in the alias (identified by a % followed by a number, e.g. %4) will be replaced with the content of that capture group in the regex pattern, as matched against the filename. Capture groups that do not exist or have no content will be replaced with an empty string. A literal percent character can be produced escaping it as %%. When using a case-insensitive regular expression, insertions will be lowercased to ensure consistent row names.
For example, the value of capture group 1 for regex “app\_(.\*)\_\d+\.log$” matched against file “app_Apache_001.log” would be “Apache” (the contents of the .* portion of the regex).
Given the following configuration:
Path: /var/logs/app_*.log
Regex pattern: app_(.*)_\d+\.log$
Alias: App-%1
And the files:
/var/logs/app_Apache_001.log
/var/logs/app_Apache_002.log
/var/logs/app_Samba_1_01.log
/var/logs/app_Router.log
FKM creates two rows in the view:
"App-Apache" monitoring "app_Apache_002.log"
"App-Samba_1" monitoring "app_Samba_1_01.log".
The file app_Apache_002.log is selected over app_Apache_001.log because it has a more recent modification-time (it is assumed that Apache is rolling files by creating higher-numbered logs). The time used for this check can be controlled using the wildcardMatchTime setting. File “app_Router.log” is ignored as it does not pass the regex.
To use the Date generation function when the dynamicFiles option is selected, see Use date generation function when using dynamic files option in File Keyword Monitor (FKM) Plug-in User Guide.
files > file > outboundStream > streamName Copied
Specifies the Publisher plugin where the FKM will publish the outbound stream. The outbound stream name must be a fully qualified stream name following the managedEntity-name.publisher-sampler(type) format, such as ME.publisher-instance.
By default, all log lines are published to the outbound stream whether or not there are matching keywords. Each outbound stream follows a source filename, stream, or NT event log.
Note
The name of the Managed Entity can be omitted if the sampler falls under the same managed entity as the FKM sampler.
The following source types can be published to the outbound stream: filename, stream, and ntEventLog. Other source types such as dynamic files and process descriptors are not supported and will be ignored.
FKM sends the stream messages to the Publisher plugin in JSON format. For example:
{
"content":"Warning 3",
"hostname":"MNLP074",
"managedEntity":"ME_Windows",
"managedEntityAttributes":{"gateway_name":"Gateway","gateway_port":"7085"},
"matchKey":"WARNING",
"netprobe":"MNLP074:7036",
"sampler":"FKM",
"samplerType":"Type",
"sourceAlias":"test.txt",
"sourceName":".\\test.txt",
"sourceType":"file",
"status":"warning",
"timestamp":"2021-06-17 06:00:04"
}
| JSON field | Description |
|---|---|
| content | Entire message from the source file or stream. |
| hostname | Name of the host machine where the Netprobe is running. |
| gatewayName | Name of the Gateway.
|
| ignoreKey | Ignore key found in the message, if there are any. |
| managedEntity | Name of the managed entity to which the FKM sampler belongs. |
| managedEntityAttributes | List of managed entity attribute names and their values, if there are any. For more information on Managed Entity attributes, see managedEntities > managedEntity > attribute.
|
| matchKey | Match key found in the message, if there are any. |
| netprobe | Hostname and port of the Netprobe. |
| sampler | Name of the configured FKM sampler. |
| samplerType | Name of the type that the FKM sampler falls under. |
| sourceAlias | Alias configured for the file, stream, or ntEventLog. |
| sourceName | Name of the source file, stream, or ntEventLog. |
| sourceType | Indicates whether the source is a filename, stream, or ntEventLog. |
| status | Severity of the detected match key in the message, if there are any. This can either be failed or warning. |
| timestamp | Timestamp of when the message was read from the source file or stream. |
Elasticsearch Mapping Copied
If the outbound stream is published to an Elasticsearch server through the Publisher plug-in, then the stream messages follow an Elasticsearch explicit mapping to handle and index the JSON fields. For example:
{ "<index name>": {
"mappings": {
"properties": {
"content": {
"type": "text"
},
"hostname": {
"type": "text"
},
"ignoreKey": {
"type": "text"
},
"managedEntity": {
"type": "text"
},
"managedEntityAttributes": {
"type": "object",
"dynamic": "true"
},
"matchKey": {
"type": "text"
},
"netprobe": {
"type": "text"
},
"sampler": {
"type": "text"
},
"samplerType": {
"type": "text"
},
"sourceAlias": {
"type": "text"
},
"sourceName": {
"type": "text"
},
"sourceType": {
"type": "text"
},
"status": {
"type": "text"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
}
Note
If files > file > multiline is disabled, then the sampler publishes metadata for the match lines as separate objects.
Mandatory: No
Default: None
files > file > outboundStream > filterOptions Copied
Enables the following filter options: streamLinesMatchedByTriggerKey and streamLinesMatchedByIgnoreKey.
If the filterOptions section is enabled but the filter options are unticked, then the FKM plugin filters out all log lines, and therefore nothing is published to the outbound stream. A WARNING message will be displayed in the Netprobe log.
Mandatory: No
Default: Disabled
files > file > outboundStream > filterOptions > streamLinesMatchedByTriggerKey Copied
By default, the FKM plugin publishes all log lines to the outbound stream. When the filterOptions section is enabled and this filter option is ticked, then the FKM plugin is set to filter and publish the stream lines that match the configured fkmTable > keys > key > setKey.
Mandatory: No
Default: true
Note
This setting will only be active if the filterOptions section is enabled.
files > file > outboundStream > filterOptions > streamLinesMatchedByIgnoreKey Copied
By default, the FKM plugin publishes all log lines to the outbound stream. When the filterOptions section is enabled and this filter option is ticked, then the FKM plugin is set to filter and publish the stream lines that match the configured fkmTable > keys > ignoreKey.
Mandatory: No
Default: true
Note
This setting will only be active if the filterOptions section is enabled.
files > file > contentType Copied
The content type specifies how FKM will read the file. This setting only applies to files on disk, including process log files. This setting allows a file to be marked as BINARY or Unicode, which alters the way the file is read. See the Technical Reference section on binary files and Unicode files for more information.
Possible values are as follows:
| Value | Description |
|---|---|
| TEXT | The file is read as normal. |
| BINARY | NUL characters are replaced with spaces. |
| UNICODE-AUTODETECT | Detects the Unicode file format (from the choices below) by examining the file Byte-Order-Marker. |
| UTF-8 | Reads the file as a UTF-8 encoded file. |
| UTF-16 | Reads the file as a UTF-16 encoded file. |
Mandatory: No
Default: TEXT
files > file > clearTime Copied
The clear time setting specifies an optional time of day at which all triggers of a file will be cleared. It has the same effect as using the Accept this File dataview menu option on the file.
This setting may be used to ensure that all active triggers are cleared at the end of the business day.
The clear time should be specified using a 24-hour format, such as 18:30. However, this setting considers 00:00 as an invalid clear time.
Mandatory: No
Note
This setting follows the Netprobe server time and time zone.
files > file > defaultKeyClearTime Copied
Specifies a default value for the key clear time for trigger rows for this file. This will only apply to keys that do not specify a clearTime value, any keys that specify a clearTime value will override this setting.
Mandatory: No
files > file > rewind Copied
By default when FKM starts monitoring files all existing data in the file is ignored - i.e. monitoring starts from the current end of the file. Enabling this setting will instruct FKM to start monitoring from the start of the file, and process the existing file data.
Note
This setting only applies to files on disk. The FKM plug-in reads from the beginning of a file whenever it detects the file is new, specifically if the file’s inode (File ID in Windows) changes, regardless of the rewind option.
Mandatory: No
Default: false
files > file > alias Copied
By default, the name column in the FKM dataview displays the file source for each file. This can be overridden by specifying a file alias using this setting. This can be used to provide a description of the contents of the file, such as GL log, or to give files a unique name when monitoring the same file multiple times.
If using a dynamicFiles source, the alias may optionally contain numbered capture groups from a regular expression for insertion, denoted by the %, such as %4 for the 4th capture group. A literal percent character can be produced using the character sequence %%. Empty or non-existent capture groups will be replaced with an empty string. Percent characters not followed by a number will be repeated verbatim.
Mandatory: No
Default: %0or the full filename when using a dynamicFiles source
Caution
When you use the*and?wildcard expressions in files > file > source > filename or in wildcardMonitorAllMatches, the files > file > alias configuration does not work and the dataview displays the source name, instead.
files > file > activeTime Copied
The activeTime setting references an activeTime definition from elsewhere in the gateway setup. This time controls whether any keyword tables are checked for the file, as opposed to the keyTable activeTime setting which controls whether one particular keyword table is checked or the key activeTime setting which controls whether one particular keyword in a table is checked.
If the activeTime is inactive then file lines are not scanned for keywords (which includes set-keys, clear-keys and ignore-keys). File statistics such as the modification time or file size are updated however. The file status column will also be updated to display “INACTIVE” provided there are no outstanding conditions for the file.
This setting can be used in conjunction with activeTimes configured for individual keyword tables and keywords. This allows monitoring for a file to be restricted to the file active time, while allowing keyword tables to be enabled or disabled for active times within this period, and further it allows individual keywords to be enabled and disabled within the table’s active time period.
Mandatory: No
Default: No active time is set (keyword tables are always scanned).
files > file > ignoreFilePath Copied
This setting specifies the directory of where the plug-in should look to find ignore files for this monitored file. If this is not set, then the value of the ‘defaultIgnoreFilePath’ parameter is used instead. This functionality is only available for Gateway2. See ignore files feature for more details.
Mandatory: No
files > file > ignoreFileName Copied
This setting specifies the name of the ignore file for this monitored file. If this is not set, then the value of the ‘defaultIgnoreFileName’ parameter is used instead. This functionality is only available for Gateway2. See ignore files feature for more details.
Mandatory: No
files > file > readPartialLines Copied
This settings controls if partial lines are read and matched against. If it is on (which it is by default) the partial line will be read and matched against the keys.
If the setting is configured to be off then then only complete lines will be considered.
A complete line is one that is terminated a new line.
Mandatory: No
Default: true
Table and key configuration Copied
Each FKM file can be configured with a number of key tables, each of which contains a set of keys to search for in the file. Key tables can be configured specifically for a file in the file definition, or placed as a variable and shared between multiple files.
Key tables can have different associated severities. The severity controls what FKM displays when a match is found for a key in that table. Fail tables are typically checked before warning tables, although this can be controlled using the reorderKeywordTables setting.
files > file > tables Copied
The tables setting specifies the keyword tables to use for this file. Lines from the file are scanned for the first matching keyword in the keyword tables, which will trigger a new row in the dataview. The file status will also change to the table severity.
Mandatory: No
files > file > tables > table Copied
Specifies a single keyword table to use for the file.
Mandatory: No
files > file > tables > table > severity Copied
Specifies the severity of this table for the file. The severity controls the resulting file status when a keyword in this table is detected. It may also control which order the tables are checked in, depending upon the value of the reorderKeywordTables setting.
Possible values are as follows:
| Severity | Description |
|---|---|
| fail | A fail state is produced for any matching keys. This corresponds with a severity of critical (and appears red), if using the suggested rules. Fail tables are checked before warning tables by default. |
| warning | A warning state is produced for any matching keys in a warning table. |
Mandatory: Yes
files > file > tables > table > keyTable Copied
The key table setting contains the actual table definition (the keywords). This setting can either reference an FKM table defined in the “static variables” section of the gateway setup, or a table can be defined here directly.
See the fkmTable setting for a full description of keyword configuration options.
Mandatory: Yes
files > file > tables > table > activeTime Copied
The activeTime setting references an activeTime definition from elsewhere in the gateway setup. When FKM checks a file for keywords, the activeTime for the keyword table is also checked. If the time is inactive, then the keyword table referencing this time is skipped (no keys defined within the table are checked for in the file).
This setting can be used to configure a file with different sets of keywords, allowing different conditions to be monitored during different periods of the day.
This setting can be used in conjunction with the keyword-level activeTime. If the time is active, then the keyword’s activeTime is further checked for scanning.
Inactive keyword tables can optionally be scanned for any clear-keys in the table using the checkInactiveClearKeys plug-in setting.
Mandatory: No
Default: No active time is set (the keyword table is always active).
files > file > failTable Copied
The fail table setting specifies an optional fail table of keys for the file. Any file lines which contain a key defined in this table will cause the file status to change to FAIL.
This setting has been deprecated in favour of the more general table setting. Please configure a table with a severity of “fail” rather than use this setting.
Mandatory: No
files > file > warningTable Copied
The warning table setting specifies an optional table of warning keys for the file. Any file lines which contain a key defined in this table will cause the file status to change to WARNING.
This setting has been deprecated in favour of the more general table setting. Please configure a table with a severity of “warning” rather than use this setting.
Mandatory: No
fkmTable > keys Copied
This setting defines a set of keys to make up an FKM key table. This table will only be accessible for the specific file it is being configured for. To share a table definition between files, configure a table as a static variable and reference it using the fkmTable setting.
Mandatory: No
fkmTable > keys > key Copied
Defines a single key in a set of keys.
Mandatory: No
fkmTable > keys > key > setKey Copied
A set key defines a key to search for. If this key matches, a trigger will be created.
Mandatory: No
fkmTable > keys > key > setKey > match Copied
A match set key specifies some text which must appear in the file line to cause a match.
Mandatory: No
fkmTable > keySearchString > key > setKey > match > searchString Copied
Specifies the string literal or regular expression to search for in the file line.
The search string may also contain a date expansion, which will be replaced with the formatted date on the first sample of each day. If the search string is a regex, then the expansion will be performed before the string is interpreted as a regex. Date expansions can be controlled using the expandDatesInKeywords plug-in setting.
Mandatory: Yes
fkmTable > keys > key > setKey > match > rules Copied
Specifies the match mode to be used when matching.
| Mode | Description |
|---|---|
| BASIC | Basic matching searches the file line for the search string using case insensitive comparison. |
| REGEXP | Regular expression matching searches the file line for text matching the regular expression.
|
| REGEXP_IGNORE_CASE | This option selects regular expression matching (as above) but performs case-insensitive matching (i.e. the case is ignored). |
Mandatory: No
Default: BASIC
fkmTable > keys > key > setKey > updated Copied
If an updated key is added to a key set, then this will trigger when the file is updated or changed in any way (including the creation of a new file with the same name). This can be used for example, to ensure that a system configuration file does not change.
If an updated key has been specified in a key table, then any notUpdatedIn keys will be ignored.
Mandatory: No
Note
This key is only applicable to actual files on the host system and does not support streams.
fkmTable > keys > key > setKey > notUpdatedIn Copied
The notUpdatedIn key type is the inverse of the updated key above. This key can be used to alert users if the associated file has not been updated for a period of time. The value of this setting specifies this period as a number of seconds.
Mandatory: No
Note
This key is only applicable to actual files on the host system and does not support streams.
fkmTable > keys > key > clearKey Copied
A clear key specifies an additional match for this key. If a file line matches the match key (creating a trigger) and a file line later match this clear key, the created trigger will be automatically removed.
Mandatory: No
fkmTable > keys > key > clearKey > match Copied
A match clear key specifies some text which must appear in the file line to cause a match.
Mandatory: No
fkmTable > keys > key > clearKey > match > searchString Copied
Specifies the string literal or regular expression to search for in the file line.
Search strings can refer to specific parts of the matching text to clear specific conditions. See Using dollar references and capture groups.
Mandatory: Yes
fkmTable > keys > key > clearKey > match > rules Copied
Specifies whether the searchString will be matched using case-insensitive matching (BASIC) or regular expressions (REGEXP). See the match key rules setting for more information.
Mandatory: No
Default: BASIC
fkmTable > keys > key > clearKey > mode Copied
The mode setting controls what rows are cleared when a clear key match is found. This setting overrides the plug-in default value (as specified by the defaultClearMode setting) for a particular key.
| Mode | Description |
|---|---|
| latest | The latest matching trigger row is cleared by the clear key. |
| all | All trigger rows created by this key are cleared by the clear key. |
Mandatory: No
Default: latest
fkmTable > keys > key > clearTime Copied
This setting controls the length of time a trigger row will remain in the dataview after it is first detected. The setting value specifies the number of seconds the row will remain. If this setting is not specified the trigger row will remain in the view until manually accepted by the user, or is removed as part of accepting (or clearing) a file.
Mandatory: No
Default: 0 seconds (trigger row is never removed)
fkmTable > keys > key > message Copied
Specifies an optional message which is displayed in the triggerDetails column of the created trigger row (in addition to the normal trigger details).
The message can refer to specific parts of the matching text to provide additional information. See Using dollar references and capture groups.
Mandatory: No
fkmTable > keys > key > tags Copied
This setting specifies start and end tags which can be used to parse the triggerDetails output for a line matching this key. This can be helpful for extracting useful information from a long file line.
Tags specified at key level override those specified in the plug-in tags setting. The parseTriggerDetails setting must be enabled for this to take effect.
Mandatory: No
fkmTable > keys > key > extractors Copied
This section allows you to specify a list of extractors for your keyword. An extractor is a regex pattern which is applied to the file line after the line is found to match the keyword.
The extractor regex is then matched against the file line and used to extract a piece of text, which is displayed in a dataview column against the trigger row created for the key. These columns can give hints to users of AC as to important parts of a message, and are also passed to action scripts if an action fires for that row.
Mandatory: No
fkmTable > keys > key > extractors > extractor > name Copied
This setting sets the name of the extractor - this name is also used as the column name in FKM and so must not be the same as any existing FKM columns. The name should also be different to any other extractors defined in the key, but the same name can be used across multiple keys.
Mandatory: Yes
fkmTable > keys > key > extractors > extractor > regex Copied
Specifies the regex pattern used to extract part of the file line. This regex pattern must contain a grouping (parentheses), which will then be used as the extracted value.
e.g. For the extractor “Connectionerror#([0-9]\*)” the extracted part of the message is the part which matches the parenthesised part of the pattern “[0-9]\*”. Given the file line “Connection error #2058 - check queue manager name”, the extracted string is then “2058”.
Mandatory: Yes
fkmTable > keys > key > severity Copied
This severity setting allows the user to override the severity of a table for a particular key definition. For example using this setting you could configure a “warning” key inside a table which is defined with a “fail” severity (i.e. a fail table). If this setting is not specified then the key inherits the table severity.
Possible values are described below:
| Severity | Description |
|---|---|
| fail | Text found to match this key is triggered with a “fail” severity.. |
| warning | Text found to match this key is triggered with a “warning” severity. |
Mandatory: No
Default: Key inherits the table severity if setting is not specified.
fkmTable > keys > key > activeTime Copied
The activeTime setting references an activeTime definition from elsewhere in the gateway setup. This time controls whether a keyword defined in the keyword table for a file is enabled or disabled.
If the activeTime for the file-level and keyword table-level is active or not configured, then the time for the keyword is scanned. If the time is inactive then file lines are not scanned for the keyword (which includes set-key and ignore-key).
Mandatory: No
Default: No active time is set (keyword is always active).
fkmTable > keys > ignoreKey Copied
An ignore key works in the same was as a match key. However rather than creating a trigger row when the key is detected, an ignore key silently ignores the line.
Ignore keys are typically used to filter out file lines which would otherwise match a key and create a trigger. For example, a server log may contain several lines starting “Failed to …” where some of these messages are innocuous. An ignore key could be used to ignore the known messages, and a match key configured to catch all other failures.
As keys in a key table are checked against a file line in order of definition, an ignore key must be specified earlier in the table than the key(s) which it is protecting.
Note
Ignore keys will have no effect if continue trigger scan is set.
Mandatory: No
The maximum number of characters per line that the FKM can process is 32,768. If a line exceeds this length, the remaining characters will be processed on the next iteration as another set of lines. For example, the ignore key is on the 20th character and the match key is on the 35,000th character, the FKM will split and process the file as follows.
First line:
<some characters to 20th character> <IGNORE KEY> <some characters up to 32,768th line>
Second line:
<32,769th up to 35,000th characters> <MATCH KEY>
The second line will be matched by the FKM because the ignore key is missing.
fkmTable > keys > ignoreKey > searchString Copied
Specifies the string literal or regular expression to search for in the file line.
Mandatory: Yes
fkmTable > keys > ignoreKey > rules Copied
Specifies whether the searchString will be matched using case-insensitive matching (BASIC) or regular expressions (REGEXP). See the match key rules setting for more information.
Mandatory: No
Default: BASIC
fkmTable > keys > ignoreKey > activeTime Copied
The activeTime setting references an activeTime definition from elsewhere in the gateway setup. This time controls whether a keyword defined in the keyword table for a file is enabled or disabled.
If the activeTime for the file-level and keyword table-level is active or not configured, then the time for the keyword is scanned. If the time is inactive then file lines are not scanned for the keyword (which includes set-key and ignore-key).
Mandatory: No
Default: No active time is set (keyword is always active).
Display configuration Copied
The settings described in this section affect how data is displayed by FKM in the published dataview. Values in the dataview are transmitted to gateway in this form, and so changes to display settings will also alter the data that gateway receives (and so possibly the result of rule evaluations).
display Copied
This section is used to configure display-related settings. These settings change how data is displayed by FKM in the published dataview, and so affects the whole plug-in rather than a particular file.
Mandatory: No
display > columns Copied
The columns setting allows users to configure the list of columns displayed by FKM in the dataview. The contents of these columns are described in more detail in the example view table legend above.
Possible values are as follows:
| Column | Description |
|---|---|
| status | File status (OK, WARNING, FAIL, NOT_FOUND, or HEARTBEAT_NOT_FOUND). |
| permissions | File permissions (read write execute). |
| lastModificationTime | Time the file was last modified. |
| fileSize | Current file size. |
| updateRate | Current update rate (rate of growth or shrinkage). |
| triggerDetails | Details of detected trigger. |
| secondsSinceLastTrigger | Number of seconds since a trigger was last detected. |
| triggerCount | Number of triggers detected. |
| filename | Full name of the file (for files with wildcard names). |
| absolutePath | Full path to the file (including the filename). |
| secondsSinceLastModified | Number of seconds since the file was last modified. |
Note
The name column is always displayed as the first column in the dataview.
Mandatory: No
Default: status, permissions, lastModificationTime, fileSize, updateRate, triggerDetails, filename.
display > triggerMode Copied
The trigger mode describes how multiple triggers are displayed by FKM. Trigger rows in a dataview always appear with the name indented, underneath the file row.
| Mode | Description |
|---|---|
| SINGLE | In single trigger mode, FKM will only show one trigger row per key, per file. This means that if the same key appears twice (or more) in a file then only the details for the latest-detected line matching that key will be shown. |
| SINGLE_GROUPED_MESSAGE | Single trigger mode, where the triggers are grouped by the message. In this mode the names of trigger rows are displayed as When using this option, it is recommended to keep the message brief to aid display in Active Console. |
| MULTIPLE | In multiple trigger mode, FKM will show a new trigger row for each detected key. Detected keys for each file are then indexed by increasing number starting at 0. Later numbers indicate later detected keys. |
| MULTIPLE_GROUPED_TRIGGER | Multiple trigger mode, where the triggers are grouped by the match key. In this mode the names of trigger rows are displayed in the format This causes the trigger to be sorted on the key which generated the line, and so show up in groups. |
Mandatory: No
Default: SINGLE
display > lastTriggerInStatus Copied
When FKM detects a new trigger, the file status is to include the file line of the latest-detected trigger. This setting enables users to disable this behaviour (by setting the value to false), so that the file status is displayed only as FAIL or WARNING.
Mandatory: No
Default: true
display > notFoundMessage Copied
When a file could not be opened, FKM changes the status to NOT\_FOUND and also displays an additional information message on why the file could not be opened. Typically this is because the file does not exist, but can sometimes be due to other errors such as insufficient permissions. These additional messages can be disabled by changing this setting to false.
Mandatory: No
Default: true
display > triggerMessages Copied
If a message has been configured for a key, the triggerDetails column of the trigger row for this key will display the text <message>(<line>) where line is the line of the file in which the key was detected. Setting the value of this setting to false will omit the message text from this column.
Mandatory: No
Default: true
display > showLastModificationTimeInSeconds Copied
The last modification time as displayed in the lastModificationTime column is shown in a human-readable format. Setting this setting to true will show this time as the number of seconds since Jan 1 1970 (aka Unix time) which allows for numerical comparisons in rules.
Mandatory: No
Default: false
display > showSecondsSinceLastTrigger Copied
Adds the secondsSinceLastTrigger column to the list of columns displayed by default. This column can also be displayed by setting it explicitly using the display columns setting.
The behaviour of this column can be affected by the Trigger Count Mode setting.
Mandatory: No
Default: false
display > showControlCharsAsSpaces Copied
When monitoring binary file, the contents of a file line can sometimes contain non-printing binary (control) characters. If a key is detected on this line the triggerDetails column will display the line but any control characters will not be displayed, leading to a compacted line which can be hard to read. This is particularly relevant for files containing FIX messages.
Enabling this setting will cause FKM to replace all control characters with spaces when data is published in a dataview. This is done after the file line has been scanned for trigger keys. Control characters are also replaced when using the “View File” and “View File near Trigger” right-click menu commands so that the output appears as expected.
Whitespace characters such as spaces, tabs or newline characters are not counted as control characters for the purposes of replacement.
Mandatory: No
Default: false
display > showControlCharsAsChar Copied
This setting is similar to the showControlCharsAsSpaces above, however it allows the user to configure the character which will be used to replace non-printing control characters. Characters are replaced prior to the file line being displayed in the FKM dataview, and also in the results of any “view file” right-click menu command options.
Characters can be specified by entering a single replacement character. Alternatively, it can also be specified using the hexadecimal character code in the form 0xHH where HH is a hexadecimal number. E.g. 0x20 specifies the space character. A list of characters and their codes can be found on the ASCII table website.
Whitespace characters such as spaces, tabs or newline characters are not counted as control characters for the purposes of replacement.
Mandatory: No
Default: no characters are replaced
display > triggerCountMode Copied
The trigger count mode setting controls the contents displayed in the triggerCount and secondsSinceLastTrigger columns. This setting only takes effect if the triggerMode setting is set to MULTIPLE\_GROUPED\_TRIGGER or MULTIPLE.
The following values can be specified for this setting:
| Mode | Description |
|---|---|
| SUM | The triggerCount column shows the sum of the active trigger rows (i.e. displayed in the dataview) for that file. The secondsSinceLastTrigger column will show the seconds since the last trigger row was generated (i.e. displayed in the dataview) for that file. |
| CUMULATIVE_TOTAL | The triggerCount column shows the cumulative total of all conditions detected for the file, regardless of whether the trigger was ever displayed in the dataview. (i.e. This count also includes trigger rows which were not displayed because the max. condition count was reached). The count is reset when the Netprobe or plug-in is restarted, if the The secondsSinceLastTrigger column will show the seconds since the last trigger - regardless of whether that trigger is displayed or not. |
Mandatory: No
Default: SUM
display > useFullPathInRowNames Copied
If set, causes the full path of the file to be used in the rowName. This prevents duplicate rows when monitoring files of the same name in different directories using wildcard filenames, with the wildcardMonitorAllMatches setting enabled. By default, only filenames are used as row names when displaying wildcard matches with wildcardMonitorAllMatches enabled.
Mandatory: No
Default: false
display > fileSizeDisplayMode Copied
This setting controls how the fileSize column in the Dataview is formatted. If left un-specified the fileSize column is formatted in kilobytes, otherwise the chosen unit is used.
The following values can be specified for this setting:
| Mode | Description |
|---|---|
| BYTES | The fileSize column is formatted in bytes, e.g., “50 b”. |
| KILOBYTES | The fileSize column is formatted in kilobytes, e.g., “2.0 Kb”. |
Mandatory: No
Default: KILOBYTES
File scan settings Copied
The settings described in this section control various options which affect how FKM will scan the monitored log files.
isPCREMode Copied
If enabled, allows the FKM sampler to use Perl Compatible Regular Expressions (PCRE).
If disabled, then the FKM uses the Portable Operating System Interface (POSIX) extended regular expressions, instead.
Beginning Geneos 5.4.x, the FKM plugin uses Perl Compatible Regular Expressions (PCRE) by default. Be aware that this may introduce breaking changes in your implementation.
For more information on using regular expressions on the FKM, see the following:
Mandatory: No
Default: true
maxSamplesLagging Copied
This setting determines how many samples a file can lag for before the file is ignored as updating too fast. A file is counted as lagging if the last line processed for the file in a sample is not (currently) the last line in the file. This will typically occur because the limit of lines to process has been reached (see maxLinesProcessed below).
If a file is lagging for more than the maximum number of samples, it will then be ignored until a user manually accepts the file. An alert to this effect is displayed in the status column for the file.
Mandatory: No
Default: 20
maxLinesProcessed Copied
This setting controls how many lines (per file) will be processed in a single sample. This works in conjunction with the maxSamplesLagging setting (above) to determine if a file is updating too fast.
Mandatory: No
Default: 20000
excessiveUpdatesTimeout Copied
If a file is updating at a very fast rate, this indicates that a process is malfunctioning. FKM reads a maximum of 20,000 lines per sample. If more than this limit is written to the file for 20 consecutive samples, then
the processing of this file stops. The FKM file displays the WARNING: FKM stopped on this file - excessive update rate detected. error message in the status column.
It is possible by enabling this setting to automatically accept an excessive update rate error. When this option is enabled and FKM detects a file that grows rapidly, it skips to the end of a file, and generates a condition (as if a keyword was detected) to display a warning error message. After the specified period of time, the system removes this condition. If you do not wish to manually remove the condition, set the timeout to 0.
The WARNING: FKM stopped on this file - excessive update rate detected. error is not a message contained in the files you are monitoring with FKM. Therefore, you cannot use the ignore key to ignore this error.
To clear the warning status, do any of the following:
- Manually accept the file.
- Configure a timeout for the sampler to automatically accept it. The timeout setting is in the FKM sampler > Advanced tab > excessiveUpdatesTimeout (in seconds). This makes the sampler accept the warning, and start reading the file from the end automatically.
- Modify other FKM settings such as
maxLinesProcessedto allow it to read more than 20,000 lines. - Increase the
maxSamplesLaggingto determine the number of samples a file can lag for before the file is ignored, as it updates too fast. Adjusting these settings and lowering the FKM sample interval enable the Netprobe to perform frequent sampling, and read more lines each time.
Mandatory: No
Default: None
Units: seconds
maxConditionsPerSample Copied
This setting controls how many trigger rows (conditions) are recorded in a single sample. This is used primarily in multiple trigger mode (see triggerMode above) to limit the number of triggers which will be created. Triggers created after this limit is reached are displayed in the next sample.
Mandatory: No
Default: 1000
maxConditionsPerFile Copied
This setting controls how many trigger rows (conditions) are recorded per file. This is used primarily in multiple trigger mode (see triggerMode above) to limit the number of triggers which will be created. Triggers created after this limit is reached are lost.
Mandatory: No
Default: 1000
maxConditionsPerKey Copied
This setting controls how many trigger rows (conditions) are recorded per file, for a particular key which generated them. This is used primarily in multiple trigger mode and single grouped message mode (see triggerMode above) to limit the number of triggers which will be created.
This setting gives finer-grained control than the maxConditionsPerFile setting, since it ensures that a lot of one type of detected key cannot prevent a different key from being displayed.
If a new trigger arrives after this limit has been reached, the oldest trigger for the key will be removed, and replaced with the new trigger.
Mandatory: No
Default: 1000
maxConditionID Copied
This setting controls the numbering of trigger rows (conditions) when using multiple trigger mode (see triggerMode above). Successive triggers are numbered in increasing order, until this limit is reached at which point numbering starts again from 0. Numbering is also reset when accepting a file.
Mandatory: No
Default: 10000
checkIgnoreFiles Copied
Setting this setting to true instructs FKM plug-in to check monitored files for the presence of an ignore file, which is required when using the ignore file feature. This feature is disabled by default, since it increases CPU usage by a small (but unnecessary for most users) amount.
Mandatory: No
Default: false
defaultIgnoreFilePath Copied
By default the netprobe looks in the current working directory for ignore files. This option allows the user to configure an alternate location. This functionality is only available for Gateway2.
Mandatory: No
Default: .
defaultIgnoreFileName Copied
Specifies the default ignore file to reference for all files monitored by the sampler. This functionality is only available for Gateway2.
Mandatory: No
continueTriggerScan Copied
By default FKM will stop scanning a file line for matching keys as soon as the first match is found, at which point a trigger is created. By enabling this option, FKM will match a file line against every configured key and display a trigger for each one that matched. This also therefore means that ignore keys will have no effect.
This option should only be used when absolutely required, as it will increase the processing requirements of the FKM plug-in (and hence increase CPU usage).
Mandatory: No
Default: false
singleTriggerCleartimes Copied
In single trigger mode, enabling this option will cause the triggerCount column to display a total count of triggers currently detected, for the key associated with that trigger row.
This count will also be affected by a clearTime configured for that key, so that as a keys are cleared this count decreases, which is not the case if this setting is disabled.
Mandatory: No
Default: false
wildcardMonitorAllMatches Copied
This setting controls how FKM treats files containing wildcard characters, such as * and ?. By default, only the latest file is monitored. For more information, see wildcardMatchTime setting below.
If this option is enabled, then all the files matching the pattern are monitored, and new file rows are created in the dataview for each of these files. The settings for these files are copied from their wild-carded file settings. These rows are removed when the file is no longer found or does not match the pattern. For example, if the file is deleted, or if the filename contains a <today> expansion and the date changed.
Mandatory: No
Default: false
Caution
When you use the*and?wildcard expressions in files > file > source > filename or in wildcardMonitorAllMatches, the files > file > alias configuration does not work and the dataview displays the source name, instead.
wildcardMatchTime Copied
This setting controls which file timestamp is used to determine the file to monitor, when a filename is configured that contains wildcard characters (\* and ?). Possible values are as follows:
| Time | Effect |
|---|---|
| changed | In Unix, the changed time is updated when a file inode is updated, which occurs when a file is created, moved, copied, or the file permissions are changed. This is the default FKM setting since most processes monitored by FKM tend to roll-over log files by creating a new file and using this for logging. In addition some backup utilities alter the modification time during backup, which can interfere with monitoring if this time is checked.
|
| modified | The modified time is updated when the content of a file is changed. This time may be preferred over the changed time if monitored log files will be renamed or their permissions changed. |
Mandatory: No
Default: changed
tags Copied
This setting defines trigger parsing tags used in conjunction with the parseTriggerDetails setting. If trigger parsing is enabled, then the text displayed in the triggerDetails column is parsed according to the startTag and endTag settings. This feature can be used to reduce the file line displayed, allowing the user to quickly focus on the important information.
If a startTag has been configured and is contained within the line, the result will be the text following the first instance of the startTag (if found) - the text from the start to the first startTag (inclusive) will be removed.
An endTag works similarly, except that the text from the last instance of an endTag (if found) until the end of the line is removed.
For example:
| startTag | endTag | File line | Result |
|---|---|---|---|
| [ | ] | Error opening file [no permissions] | No permissions. |
| occurred: | A fatal problem occurred: out of memory | Out of memory. | |
| occurred: | A fatal problem caused the program to exit. | A fatal problem caused the program to exit. | |
| " | " | Event filter failed with query
|
SELECT * from _InstanceModified WHERE Instance "Win32_Process" AND Load > 50 |
Either or both of these tags can be overridden by tags in a key definition for more specific parsing.
Mandatory: No
parseTriggerDetails Copied
This setting controls whether the values that appear in the triggerDetails column will be parsed using start and end tags. These tags can be defined either globally for the FKM plug-in instance (see tags above), or selectively for specific keys via the key tags setting.
Mandatory: No
Default: false
wrapViewFileNearTriggerLines Copied
This option controls the wrapping of lines in the output of a View file near trigger command.
When enabled, line wrapping will be performed when a line reaches approximately 130 characters in length. If disabled, lines will be displayed in the Active Console at their full length.
Mandatory: No
Default: True (to maintain expected behaviour)
reorderKeywordTables Copied
By default, file lines are checked for external ignore keys, then keywords from any fail tables, and finally keywords from warning tables. This is done by reordering the keyword tables for a file to be in this order.
The reorderKeywordTables setting controls whether this reordering is performed. If disabled (set to false) the keyword tables will be checked in the order they are defined in the file configuration.
Mandatory: No
Default: true
checkInactiveClearKeys Copied
This setting controls whether clear keys inside an inactive keyword table are checked against a file.
A keyword table is made up of several keywords types; keys, ignore keys, and clear keys. An activeTime can be configured on a file, keyword table or on a keyword itself.
- For a keyword: When this time is inactive, the keyword will not be scanned.
- For a keyword table: When this time is inactive, then the whole table is not used for scanning.
- For a file: When this time is inactive, no file content will be scanned.
If this option is enabled, then only the active clear keys in an inactive keyword table will still be checked. Inactive keywords will not be checked.
Mandatory: No
Default: false
defaultClearMode Copied
The default clear mode specifies how clear keys operate on a plug-in global basis. All clear keys will use this behaviour, unless specifically overridden for the key by the clearKey mode setting.
| Mode | Description |
|---|---|
| latest | The latest matching trigger row is cleared by the clear key. |
| all | All trigger rows created by this key are cleared by the clear key. |
Mandatory: No
Default: latest
expandDatesInKeywords Copied
FKM keywords may be configured with a date expansion string, e.g. < today >. This string updated each day with the current date. This feature can be controlled by means of this setting.
Mandatory: No
Default: true (dates are expanded)
monitoredDays Copied
This setting allows the FKM to resolve date expansion codes used in file names based only on certain days of the week. For example, this can be set to resolve date codes based only on weekdays, i.e. yesterday resolves to last Friday if the current day is a Monday or a weekend, and tomorrow resolves to next Monday if the current day is a Friday or a weekend. Check the appropriate day boxes to mark them as monitored. The today code always resolves to the current day, even if the current day is not marked as monitored.
Note
This setting is only used for resolving file names with date codes. It does not affect the monitoring of the plug-in on a certain day. See Date generation for more details on using date expansion codes in file names.
Mandatory: No
Default: Every day
internalTextEncoding Copied
The internal text encoding is used by FKM when reading Unicode files. The value of this setting is passed to the iconv library (used for Unicode conversion) as the target encoding for text conversion. It is not recommended to change the value of this setting unless advised to do so by ITRS Support.
Mandatory: No
Default: “//TRANSLIT”
ignoreIfNotInActiveTime Copied
Allows a user to suppress updates to the STATUS column for a file if the file is outside the configured activetime if this option has been enabled.
Mandatory: No
Default: false
defaultFileActiveTime Copied
Specifies a default for the file active time setting. Files with no individual file active time specified will use this setting, files that do specify an active time override this setting.
Mandatory: No
extendedNTEventLogOutput Copied
If set, FKM will output the event text using an extended format containing additional fields for each event, rather than just the defaults. The fields output are prefixed with the field name in extended mode, but not in default mode.
The mapping of the fields Geneos logs to the Event Viewer Windows application is as follows:
| Geneos | Extended? | Prior to OS Vista maps to | OS Vista and above maps to |
|---|---|---|---|
| Date | No | Date | Logged |
| Type | No | Type | Level |
| Source | No | Source | Source |
| EventID | Yes | EventID | EventID |
| User | Yes | User | User |
| Category | Yes | Category | Task Category |
| Computer | Yes | Computer | Computer |
| Description | No | Description | Text field in the General tab |
Example:
Date:07/11/2011 13:02:32 Type:Information event Source
Source:MSSQL$EXPRESS_2008_X86 EventID:26059 User:N/A Category:Server
Computer:ITRSPC139.ldn.itrs Description:The SQL Server Network Interface
library successfully registered the Service Principal Name (SPN) [
MSSQLSvc/ITRSPC139.ldn.itrs:EXPRESS_2008_X86 ] for the SQL Server
service.
These additional fields will also be present in the triggerDetails column.
If this option is not enabled the output would be in this format:
Mon Nov 07 13:02:32 INFO MSSQL$EXPRESS_2008_X86 The SQL Server Network Interface
library successfully registered the Service Principal Name (SPN)
[ MSSQLSvc/ITRSPC139.ldn.itrs:EXPRESS_2008_X86 ] for the SQL Server service.
Mandatory: No
Default: False
lockFilePath Copied
By default the netprobe looks in the current working directory for sampler and netprobe lock files. This option allows the user to configure an alternate location shared by both types of lock files. This option though does not apply to single lock files (see Suspending File Sampling).
Mandatory: No
Default: .
Additional details Copied
Date generation Copied
File Keyword Monitor file definitions can be configured to generate a filename using the current date and time. The target filename is generated every sample, and if a file exists which matches this name the file will be monitored by FKM (once the current file has been processed to the end).
To use the Date generation function when the dynamicFiles option is selected, see Use date generation function when using dynamic files option in File Keyword Monitor (FKM) Plug-in User Guide.
Filenames can be generated using one of five date codes; yesterday, today, tomorrow, previous\_monitored\_day, andnext\_monitored\_day. These are replaced in the filename using the appropriate date.
For example, if the current date is 22 August, 2018, then the following will be produced:
| Filename | Generated name |
|---|---|
| app< yesterday >.log | app20180821.log |
| app< today >.log | app20180822.log |
| app< tomorrow >.log | app20180823.log |
| app<previous_monitored_day>.log | app20180821.log |
| app<next_monitored_day>.log | app20180823.log |
The output format for dates can be controlled by placing format codes in the date tag. Examples of this usage are shown below.
| Filename | Generated name |
|---|---|
| app<today %d-%m-%Y>.log | app22-08-2008.log |
| app<today %d%b%y>.log | app22Aug08.log |
| app<tomorrow %d_%m_%Y>.log | app23_08_2008.log |
The following formatting codes can be used with this feature.
| Code | Description |
|---|---|
| %a | Abbreviated weekday name (e.g. Wed). |
| %A | Full weekday name (e.g. Wednesday). |
| %b | Abbreviated month name (e.g. Mar). |
| %B | Full month name (e.g. March). |
| %c | Date and time representation appropriate for the current locale. |
| %d | Day of month as decimal number (01 - 31). |
| %H | Hour in 24-hour clock format (00 - 23). |
| %I | Hour in 12-hour clock format (01 - 12). |
| %j | Day of year as decimal number (001 - 366). |
| %m | Month as decimal number (01 - 12). |
| %M | Minutes as a decimal number (00 - 59). |
| %p | Current locale’s AM / PM indicator for 12-hour clock. |
| %S | Seconds as a decimal number (00 - 61). |
| %U | Week of year as decimal number, with Sunday as first day of week (00 - 53). |
| %w | Weekday as decimal number (0 - 6; Sunday is 0). |
| %W | Week of year as decimal number, with Monday as first day of week (00 - 53). |
| %x | Date representation for current locale. |
| %X | Time representation appropriate for current locale. |
| %y | Year without century, as decimal number (00 - 99). |
| %Y | Year with century, as decimal number (e.g. 2008). |
| %z, %Z | Timezone name or abbreviation (e.g. GMT or PST); no characters are shown if the timezone is unknown. |
Note
It is possible but not recommended to use a seconds (%S) or minutes (%M) time format code in a filename. This is because the generated filename will contain the time at which FKM performed a sample, which is not guaranteed to occur at an exact number of seconds apart.
Monitoring files containing binary data Copied
Some log files may contain a mixture of text and binary data. This may cause a problem monitoring the file if the binary data contains a NUL character (ASCII 0), as the file line is truncated at the first occurrence of this character.
FKM can read these lines correctly, provided it knows the file contains binary data. This is slightly more CPU intensive than ordinary reading of pure text-files, and so is not enabled by default. Files can be marked as binary using the file contentType setting.
Note
As of gateway 2 it is no longer possible to set the file contentType setting using the FKM table. This must now always be set on the file.
In addition, the showControlCharsAsSpaces display setting may also be useful when monitoring binary files. This setting replaces control characters (non-printing characters) with spaces which can help to spread out FKM output making it easier to read.
Unicode files Copied
FKM can monitor Unicode files, by using the iconv library (available on most Unix boxes by default) to convert the text from Unicode to the native system encoding. Because of this conversion, Unicode characters which cannot be represented by the native encoding will be skipped, and are therefore not available in FKM for keyword scanning or viewing.
To use this feature configure the file contentType setting to the encoding of the file. If you do not know the encoding FKM can attempt to detect this for you. Users can also specify the iconv encoding name directly, rather than using the drop-down menu to select an option.
Ignore files feature Copied
Ignore files provide a mechanism for configuring ignore keys for an FKM file externally to the gateway setup. This allows users to dynamically ignore known problems (perhaps on a single machine) without reconfiguring the plug-in.
FKM will check for an ignore file once per sample, for each file. If the ignore file has been created (or the last modification time altered) the ignore file will be read. This file should contain a number of ignore keys, one key per file line. Ignore keys can be written as string literals or regular expressions. To specify regular expressions in an ignore file and differentiate them from string literals, they must be prefixed by “$$$RE " for case-sensitive expressions, or “$$$NCRE " if the case should be ignored.
ex.
$$$RE KEY_\d\d$
This ignores strings with “KEY_
$$$NCRE KEY_\d\d$
Using $$$NCRE ignores the case of “KEY”, so “key_01” would also be ignored.
Ignore keys are processed before keys defined in a fail or warning table. If the ignore file is removed, all ignore keys from that file will also be removed.
The steps to configure this feature are below:
-
Enable the ignore files feature by enabling the checkIgnoreFiles setting.
-
Set the ignore file name to look up:
-
Using file alias - Configure an FKM file you wish to monitor with an alias that is different to the filename. This alias then forms the base of the filename for the ignore file., with .ignore as the file extension (E.g. If the alias is
myAliasthen the expected ignore filename becomesmyAlias.ignore). -
Set ignore file name directly using ignoreFileName to specify an ignore file for a monitored file, or defaultIgnoreFileName to specify a default ignore file for an entire ampler.
-
-
Create an ignore file with the appropriate name in the Netprobe working directory, and add any desired ignore keys to the file, one per line.
-
FKM will detect when this file is created, updated or deleted. All previously added ignore keywords will be removed and the file contents re-read on these events. A message indicating this will be shown in the Netprobe log file.
Note
It is possible to specify alternate locations for a plug-in to search in to locate ignore files. See defaultIgnoreFilePath and ignoreFilePath for more details.
Regular Expressions Copied
Perl Compatible Regular Expressions (PCRE) can be used if isPCREMode is selected, please see isPCREMode for how to enable it. Using PCRE allows for more powerful and succinct regexs to be written. Examples are presented below:
| PCRE | POSIX | Behaviour |
|---|---|---|
\d |
[[:digit:]] | Matches a digit. |
| [a-z] | [[:lower:]] | Matches a lowercase letter. |
| [A-Z] | [[:upper:]] | Matches an uppercase letter. |
A great source for common Regular Expressions is http://www.regular-expressions.info/.
Some online tools which may also be helpful are http://www.regexpal.com or https://regexr.com/.
If isPCREMode isn’t enabled Regular Expressions in FKM use the POSIX extended regular expression syntax, and is typically implemented by system libraries. More information about these expressions can be found at Wikipedia or from the command line by typing “man7 regex”.
A regular expression specifies a pattern of text to match, which can appear anywhere in the file line. This behaviour can be altered by using the special anchor characters ^ and $ (see below). Unless using these characters, it is not necessary to specify a pattern which matches the whole file line, since this will reduce matching speed.
Once a regular expression has been configured, it is highly recommended that the expression be tested by echoing the intended match text into a monitored file, to ensure that a match is detected.
Regular expressions match sequences of literal characters exactly. A character is a literal character if it is not a special character below.
| Special Characters | Behaviour |
|---|---|
| \ | Escape character. Use this to turn a special character into a literal. E.g. |
| . | The dot character matches any single character. This is typically used with the asterisk to match any sequence of text, by using .*. |
| [ ] | Brackets indicate a range of possible values which will match a single character. For example, the range Ranges can contain several characters in sequence, or several ranges. E.g. Ranges can also be negated, by placing the |
| * | The asterisk character indicates that the preceding character or pattern can occur in the pattern any number of times (including never). E.g. The pattern The asterisk pattern can be applied not just to a single character, but a range of characters or a bracketed expression. E.g. |
| + | The plus character is similar to the asterisk above, but specifies that the preceding character or pattern must occur at least once. |
| ? | The question character is similar to plus and asterisk above, and specifies that the preceding character or pattern does not occur, or occurs only once. |
| {x,y} | Braces indicate that the preceding character or pattern can occur at least x times to at most y times. If x and y are the same (i.e. the pattern must occur exactly x times) then the abbreviated syntax {x} can be used. |
| | | The pipe character indicates alternation. This allows regular expressions to express an OR relationship. E.g. A pattern a(b|c) will match the text ab or ac. |
| ( ) | Parentheses allow grouping of patterns in regular expressions. These groupings are typically so that the special characters above apply to a particular part of a pattern. |
| ^ | This anchor character allows a pattern to match a particular part of a file line, rather than appear anywhere in the line. The e.g. |
| $ | This anchor character is similar to the caret (^) above, but matches the end of a line rather than the start. |
Some example regular expressions are listed below.
Expression:end$
Matches: A file line which ends with the word “end”.
Expression:^starts
Matches: A file line starting with the word “starts”.
Expression:^[A-Z]\\*word[^A-Z]\\*i
Matches: A line starting with a (possibly empty) sequence of capital letters, then “word” followed by a (possibly empty) sequence of characters with no capital letters, followed by an “i”.
Expression:...[0-9]
Matches: A line containing any three characters and then a digit.
Expression:X.[.][0-9]+
Matches: A line containing an X followed by any single character, then a dot and at least one digit.
Warning
Beginning Geneos 5.4.x, the FKM plugin uses Perl Compatible Regular Expressions (PCRE) by default. Be aware that this may introduce breaking changes in your implementation.
Character classes Copied
Character classes in POSIX would require extra brackets in PCRE.
For example, if you use [:alpha:] on PCRE, this expression will be evaluated as single characters. To define the character class in PCRE, use [[:alpha:]].
The following table illustrates more character classes to contrast POSIX and PCRE:
| POSIX | PCRE |
|---|---|
[:alnum:] |
[[:alnum:]] |
[:alpha:] |
[[:alpha:]] |
[:ascii:] |
[[:ascii:]] |
[:blank:] |
[[:blank:]] |
[:cntrl:] |
[[:cntrl:]] |
[:digit:] |
[[:digit:]] |
[:graph:] |
[[:graph:]] |
[:lower:] |
[[:lower:]] |
[:print:] |
[[:print:]] |
[:punct:] |
[[:punct:]] |
[:space:] |
[[:space:]] |
[:upper:] |
[[:upper:]] |
[:word:] |
[[:word:]] |
[:xdigit:] |
[[:xdigit:]] |
Backslash Copied
The backslash is not a metacharacter in a POSIX bracket expression.
For example, the expressions [\d] or \d would not match anything in POSIX, even if numbers are present in the string.
Non-capturing group expression Copied
The non-capturing group expression (?..) is not allowed in POSIX or any other grouping prefix.
For example, consider the string hello@yahoo.com, with the following regex with PCRE enabled:
`^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9](:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$`
This regex would have a match for hello@yahoo.com in PCRE, but not in POSIX.
In POSIX, this expression would result in an error:
WARN: FKM2[fkm posix test] Failed to compile regex '^[a-zA-Z0-9.!#$%&'*+/=?^_`\\{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]\{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]\{0,61}[a-zA-Z0-9])?)*$' for keyword. Error #13 - Invalid preceding regular expression. This key will not be added.
Multi Line Variables In Actions Copied
Outputting multi line messages stored in environment variables are not supported by any of the built-in echo commands for Windowsand Linux. To work around this issue you could use the following examples to output multi line messages from an environment variable.
Windows Copied
VBScript has been used for this example as it is present in Windows 2000 and later.
Option Explicit
Dim objWindowsShell
Dim objEnvironment
Set objWindowsShell = WScript.CreateObject("WScript.Shell")
For Each objEnvironment In objWindowsShell.Environment("PROCESS") WScript.Echo objEnvironment
Next
Set objWindowsShell = Nothing
Solaris
Linux Copied
#!/bin/sh
/bin/echo _ACTION = "${_ACTION}"
/bin/echo _SEVERITY = "${_SEVERITY}"
/bin/echo _VARIABLEPATH = "${_VARIABLEPATH}"
/bin/echo _GATEWAY = "${_GATEWAY}"
/bin/echo _PROBE = "${_PROBE}"
/bin/echo _NETPROBE_HOST = "${_NETPROBE_HOST}"
/bin/echo _MANAGED_ENTITY = "${_MANAGED_ENTITY}"
/bin/echo _SAMPLER = "${_SAMPLER}"
/bin/echo _DATAVIEW = "${_DATAVIEW}"
/bin/echo _VARIABLE = "${_VARIABLE}"
/bin/echo _REPEATCOUNT = "${_REPEATCOUNT}"
/bin/echo _VALUE = "${_VALUE}"
Using dollar references and capture groups Copied
The set key search string can be a regular expression. In a regular expression, you can use parentheses to denote a numbered sub-expression, called a capturing group or capture group. Capture group zero denotes the entire matching text, capture group one is the first parenthesised expression, and so on.
The clear key search string and message settings can refer to capture groups in the set key regular expression to include text from the set key result. This is achieved using dollar references, in the form of $
- $1
- $2
- ${3}
An example for clear keys follows.
Suppose that your monitored file contained messages that looked something like:
Error machine A: Some details about the error
...
Error machine B: Some details about the error
Your set key search string could look like:
Errormachine(\w+)
And your clear key search string could look like:
Fixed machine ${1}
This allows you to clear errors specific to results from a particular match. If you have errors reported on machines A, B, and C when the matching message for machine A is received, your error condition for machine A will be cleared.
Be sure when writing your clear key search strings or messages that the dollar reference number actually matches a capture group in the set key search string regular expression. Otherwise, your clear key or message may not match.
Suspending File Sampling Copied
FKM file access and sampling can be temporarily suspended to allow users to perform cleanup or housekeeping of monitored files without encountering possible file access conflicts with the plugin. This is done through the use of “lock files”, which may correspond to suspending the sampling of a single file, an entire FKM sampler, or all FKM samplers configured in a netprobe at once. FKM checks for the existence of lock files on every sample. When the plugin detects a lock file, it suspends its operation based on the scope of the lock. File operations remain suspended until the lock file is removed. The plugin then resumes sampling based on where it left off before the lock was applied. This behavior is similar to when active times are used to deactivate and reactivate a plugin.
Lock File Name Format and Usage Copied
Lock files follow specific naming formats depending on their intended scope. They all use the “.geneos-lock” extension to differentiate themselves from other files. The user is responsible for creating and destroying the lock files accordingly.
To suspend the sampling of individual files, a lock file must be created using the name of the target file as the base name, followed by the extension.
Ex. For a file named example.log, the corresponding lock file should be named example.log.geneos-lock
The user must create the lock file in the same directory as the target file to ensure that FKM matches the lock file to the correct target file. When a file is locked, the status field for that file is updated. The lock file can contain the name of the lock creator/owner, which would be displayed in the status message.
If the lock file is empty, the status would read SUSPENDED: Sampling locked by unknown user instead.
To suspend the sampling of a FKM sampler, a lock file must be created with the format
Ex. For a FKM sampler named “Log Sampler”, the corresponding lock file should be named “LogSampler\_fkm.geneos-lock”
By default the user must create the sampler lock file in the current working directory of the netprobe. The user though has an option to set a different path where the plugin should look for the lock file. The Fkm lock file path setting is located in the Advanced tab of the probe settings section in the gateway setup. When this setting is used, All FKM samplers defined in the probe will look for sampler and netprobe lock files in the specified path.
When a sampler is locked, the sampling status headline is updated. Other fields in the view remain as they are from the last sample. The sampler lock file can contain the name of the lock creator/owner, which would be displayed in the status message. If the file is empty, “unknown user” would be displayed by default, as described earlier.
To suspend the sampling of all FKM samplers configured in a netprobe, a lock file must be created with the format netprobe_
Ex. For a netprobe using port number 7036, the corresponding lock file should be named netprobe\_7036\_fkm.geneos-lock
As with sampler lock files, the user must create the netprobe lock file in the current working directory of the netprobe by default, but has an option to set a different path through the Fkm lock filepath setting. When a netprobe is locked, the views for all FKM samplers in the netprobe are updated the same way as when a single FKM sampler is locked.
Extended Audit Details Copied
FKM provides extended audit details if this feature is enabled in the Gateway.
Commands Copied
The following commands executed on the FKM sampler dataview will result in extended audit details being provided:
- All Snooze related commands.
- All User-assignment related commands.
- All FKM specific commands (accept, clear, etc.)
Contents Copied
The audit details will consist of information about the triggers that pertain to a particular command execution.
For each trigger, the trigger message and the original file line will be provided as values. With reference to the audit details format, each trigger will be a separate item, with each item having two field-value pairs for the message and file line respectively. E.g.:
| Item | Field | Value |
|---|---|---|
| myfile.log#warning12 | message | Overflow |
| myfile.log#warning12 | line | 10:30:20 Warning: possible overflow…. |
| myfile.log#warning14 | message | Overflow |
| myfile.log#warning14 | line | 10:30:25 Warning: overflow…. |
Targets Copied
The set of triggers that information is provided on will depend on the execution target:
| Target | Information will be provided on… |
|---|---|
| Trigger row (a row that represents a single trigger under a given file) | The particular trigger represented by the row. |
| File row (a row that represents a particular file) | All current triggers pertaining to that file. (This means that if there are currently no triggers for a given file, then no extended audit details will be reported against that file.) |
Special Case: ‘Accept file’ and ‘Accept this file’ commands Copied
In this case information will be provided about all the triggers under the particular files, regardless of whether the command was executed on a file or trigger row.
Special Case: Single Grouped Message trigger mode Copied
Under this mode, for each trigger row, information about each actual trigger that pertains to the visible row will be provided as audit details. The set of triggers in this case will be the same as shown in the output of the Trigger Details command executed against that trigger row. See Trigger Details Command for more information.
Note
Similar to the Trigger Details command, the number of trigger lines provided as audit details will be limited by the maxConditionsPerKey setting. In situations where large numbers of triggers can be active at any given time, it may be practical to reduce the amount of extended audit detail recorded against auditable events by lowering the value of this setting, especially considering the fact that, under single grouped message trigger mode, the amount of audit details collected by running a command against any given trigger row is not immediately obvious.