Gateway Performance Tuning
Overview Copied
Introduction Copied
The Geneos Gateway Performance Tuning Guide is an aid for Geneos administrators who want to maximise the benefits provided by their Geneos installation. This guide describes methods for investigating and enhancing Gateway performance using the new Gateway Load Monitoring feature.
This guide assumes knowledge of how to configure Geneos items such as NetProbes (or Probes), Managed Entities and Samplers. It also assumes a basic knowledge of Gateway features such as Rules and Alerts.
The following terminology is used in this document Copied
| Terminology | Description |
|---|---|
| Active Console | The GUI front-end to Geneos allows the visualisation of monitored data and control of the monitoring system. |
| Gateway Setup Editor (GSE) | This program enables users to modify the gateway setup. |
| Data items | Items of monitored data - primarily cells or headlines within a dataview - which can be referred to by the rest of the system. |
| XPaths or target paths | An xpath or target path is an addressing mechanism allowing data items to be referenced in the setup. |
Conventions Copied
The following text conventions are used in this document:
| Conventions | Description |
|---|---|
| Bold font | Used when referring to a setting or an option name. |

|
Program output. |
Monospacefont
|
Used when referring to data from program output, items in a screenshot, or text input by a user. |
Collecting Statistics Copied
There are several methods for enabling performance statistics for Gateways. By default, Gateways do not gather statistics as this introduces additional load on the Gateway. Use it temporarily for performance tuning and disable it once diagnostics are complete to avoid unnecessary overhead.
Statistics can be enabled either on an ad hoc basis to pinpoint a specific performance problem or they can be enabled at Gateway start-up, and will then be continually updated throughout the lifetime of the gateway. This second option allows statistics to be available to the load monitoring Gateway plug-in where the metrics themselves can be monitored by Geneos.
To avoid impacting production monitoring functionality, we recommend that the production Gateway be configured to write statistics to a file which can then be examined separately. This is especially important when actively investigating performance issues because you are likely to make several Gateway setup changes to reformat statistical output.
Ad hoc statistics’ collection Copied
Ad hoc collection of statistics can be used when you notice a gateway that typically performs well, but then starts performing badly. When this happens, you can begin collecting statistics for a period of time, and analyze what was occurring during that period of time.
To gather ad hoc statistics for a current performance issue, right-click on the gateway icon in Active Console and select the Load Monitoring > Start Stats Collection > For Time Period… command.
This will display the following dialog, allowing you to configure various options for the capture of statistics. We recommend that, for ad hoc gathering, the statistics should be cleared and the data should be written to a file.
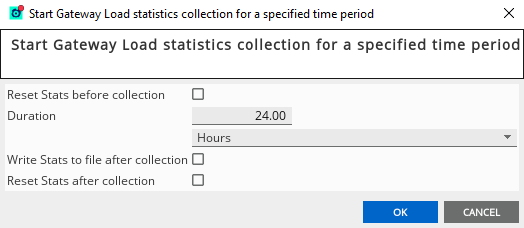
The Duration field specifies the time period over which the statistics should be gathered. Once this period of time has elapsed, the output will be written to the statistics file. Unless configured otherwise (see the gateway operating environment), this will be a file stats.xml in the Gateway working directory.
Resetting statistics will clear any previous statistics gathered up to the point that the command is executed. If this setting is not used, the statistics will be the cumulative figures gathered since the last reset (or Gateway restart, whichever is latest), and is less useful when attempting to locate the performance issue that occurred during the time the command was run.
Regular statistic collection Copied
To continually gather performance statistics on your gateway, it must be run with an additional option ‑stats which can appear anywhere in the argument list, for example:
gateway2.linux -setup sysmon\_prod.xml -stats -nolog
When started in this mode, the Gateway will output the following line early on in the log file.
<Wed Feb 15 14:30:31> ******************************************************
<Wed Feb 15 14:30:31> Geneos EMF2 Gateway GA3.0.0-120202 (c) 1995-2011 ITRS Group
<Wed Feb 15 14:30:31> ******************************************************
<Wed Feb 15 14:30:31> INFO: Running from: /opt/geneos/gateway
<Wed Feb 15 14:30:31> INFO: User/uid/gid: geneos/648/10
<Wed Feb 15 14:30:31> INFO: Current path: /bin:/usr/bin:/usr/local/bin
<Wed Feb 15 14:30:31> INFO: Gateway Gateway statistics collection is on.
<Wed Feb 15 14:30:31> INFO: LicenceManager Connecting to Licence Daemon (localhost:7041)
In this mode, performance statistics will be collected and made available in memory to any load monitoring Gateway plug-ins configured locally to that Gateway.
For production servers, we recommend that these statistics are also written to file so that they can be analyzed independently of the source gateway. To do this, open the Gateway Setup Editor (GSE) and look in the Operating environment > Advanced > Write stats to file section.
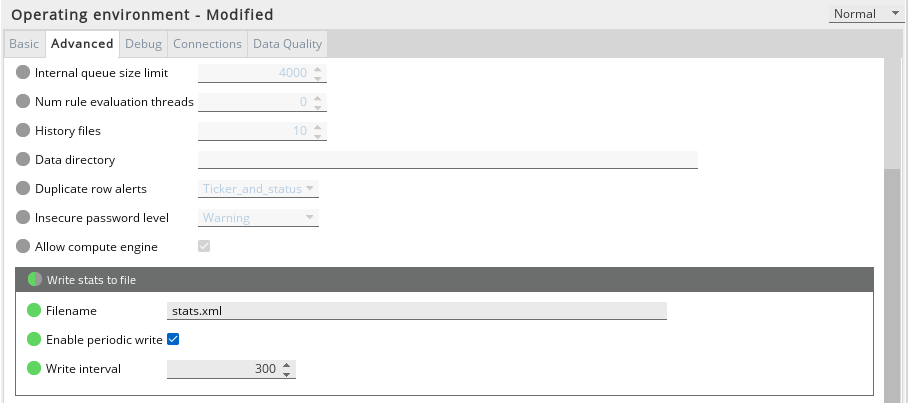
To periodically write the performance statistics, enable the Write stats to file section (as displayed above) and configure it to write periodically. The write interval is configured in seconds, so the value 300 above will output the data every 5 minutes.
With this configuration, as described so far, the statistics produced by the Gateway will be cumulative. Counts and time values, measured by the Gateway, will increase monotonically (i.e. not decrease) until the values are reset.
These statistics can be reset manually by issuing the Load Monitoring > Reset Stats command by right-clicking on the Gateway icon in Active Console.
If you would like the statistics file, produced by the Gateway, to only contain data from the last X hours of Gateway activity, you will need to configure a Scheduled Command to perform the reset operation automatically. Alternatively, the processed values from the statistics file can be logged to a database, allowing for historical reporting or comparison between arbitrary points in time.
To configure the automated reset, open the GSE > Scheduled commands and add a scheduled command as follows:
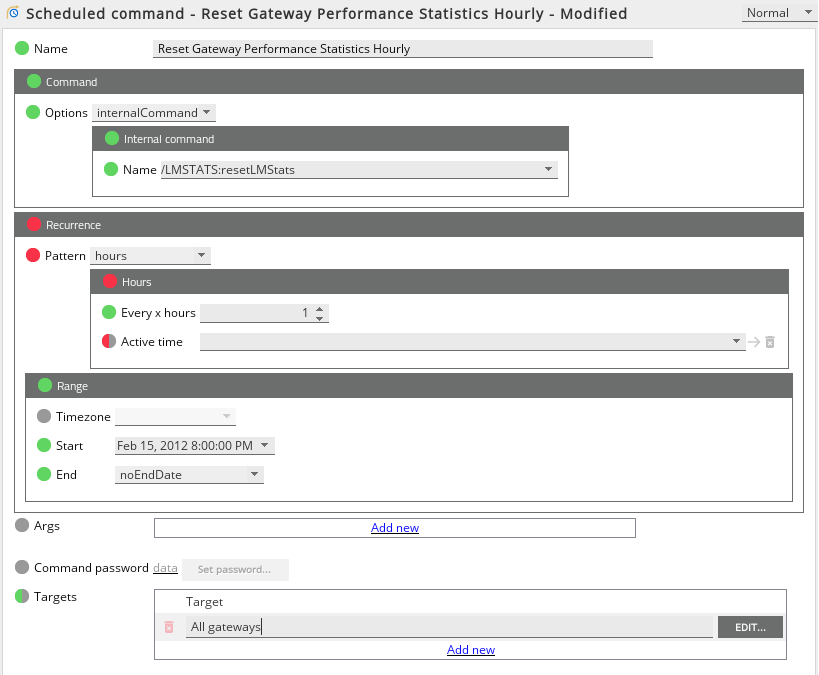
The target for this command should be entered as /geneos/gateway/directory in the Target field. This will then be translated to All gateways as shown in the screenshot above.
This command will run every hour and reset the statistics. Longer periods of time can be configured as required, but the smallest granularity for scheduled commands is an hour as shown in the screenshot.
To reset the statistics more frequently using scheduled commands, it is currently necessary to configure multiple scheduled commands, each with a different start time. For example, to reset the statistics every 15 minutes you will need 4 hourly scheduled commands configured as above, but with start times separated by 15 minutes each, for example:
- 08:00:00
- 08:15:00
- 08:30:00
- 08:45:00
Analysing Statistics Copied
Once performance statistics have been collected into a file, they can be analyzed using the load monitoring Gateway plug-in. We recommend that for extended analysis sessions, a non-production Gateway should be used because several Gateway setup changes will be required during the session.
Methodology Copied
The basic process of analysing a statistics file consists of identifying hotspots in a Gateway’s load, and then evaluating whether the hotspot is expected, given the data being processed. Once a hotspot has been found, it can be examined more closely to locate data sources and other metrics.
For example, a rule that is applied to thousands of cells would be expected to use more processing time than a rule applied to fewer cells. If this is not the case, the rule with fewer cells should be investigated to ensure the configuration is optimal. It may still be possible that this rule will use more CPU time if the rule body does more processing (for example, a compute-engine rule to perform statistical calculations).
Statistics by feature Copied
To start analysis, the component view of the load monitoring plug-in can quickly identify which Gateway feature is using the most processing time in the gathered statistical sample. To configure this monitoring, add a new sampler as illustrated below, either to an existing NetProbe or a virtual NetProbe on a Gateway:
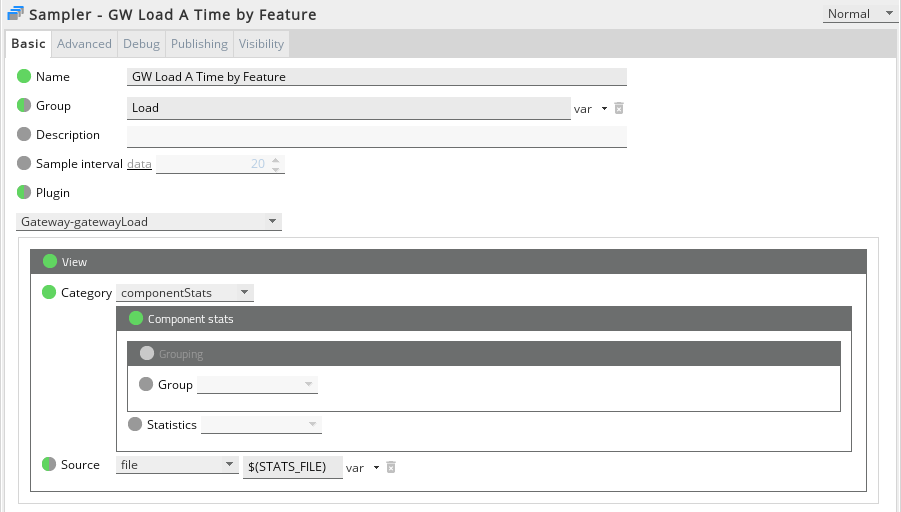
The plug-in can be configured to read statistics from a file using the Source setting. If the plug-in is not configured, it will read statistics from the Gateway’s memory if any have been gathered.
This setup produces a view listing each gateway feature, and the corresponding time spent processing on behalf of this feature. The time figures shown in the load monitoring plug-in are obtained through system dependant timer calls, and as such do not have a fixed unit. They can however be used to gauge CPU time spent relative to each other.
In the example output below, we can see that the majority of CPU time in this gateway is spent executing rules. Database logging is the next most expensive feature, and the remaining features are an order of magnitude below this.
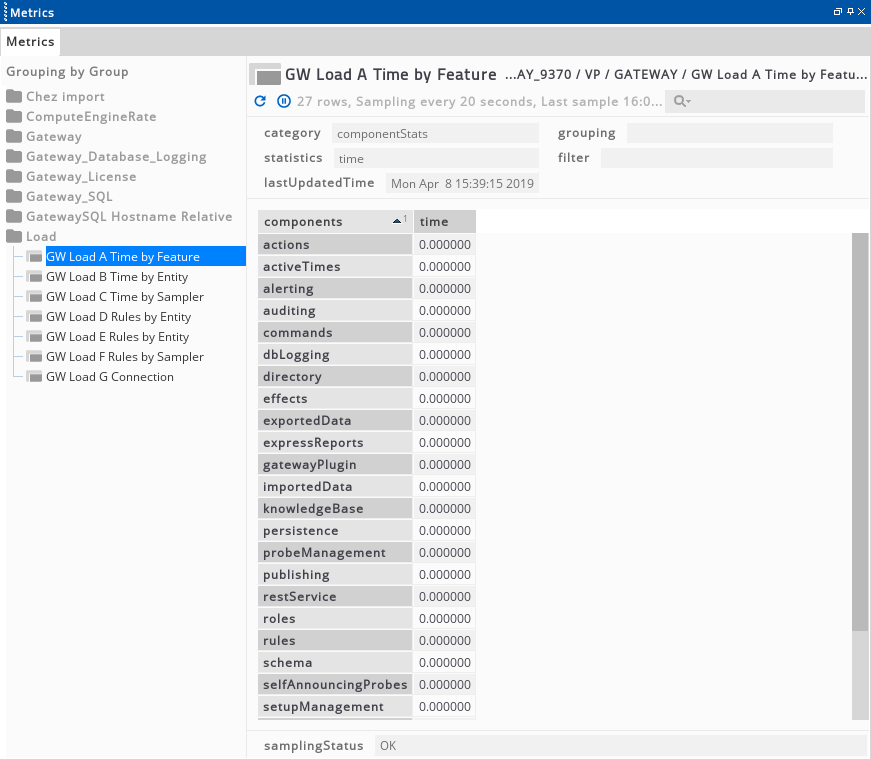
Statistics by monitored item Copied
The main view that you are likely to use to examine statistics is the directoryStats view. This view allows you to see the performance data linked to the various monitoring objects that you have configured in the gateway setup, such as Managed Entities or NetProbes.
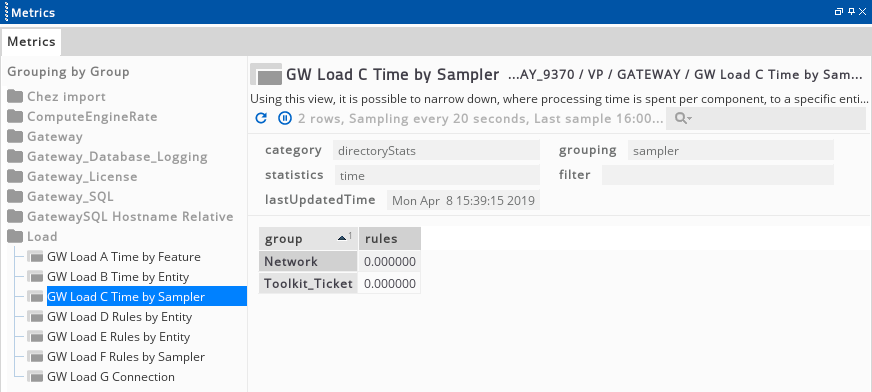
Using this view, it is possible to narrow down, where processing time is spent per component, to a specific entity or set of samplers which may indicate a misconfiguration or that these samplers are producing more data than expected.
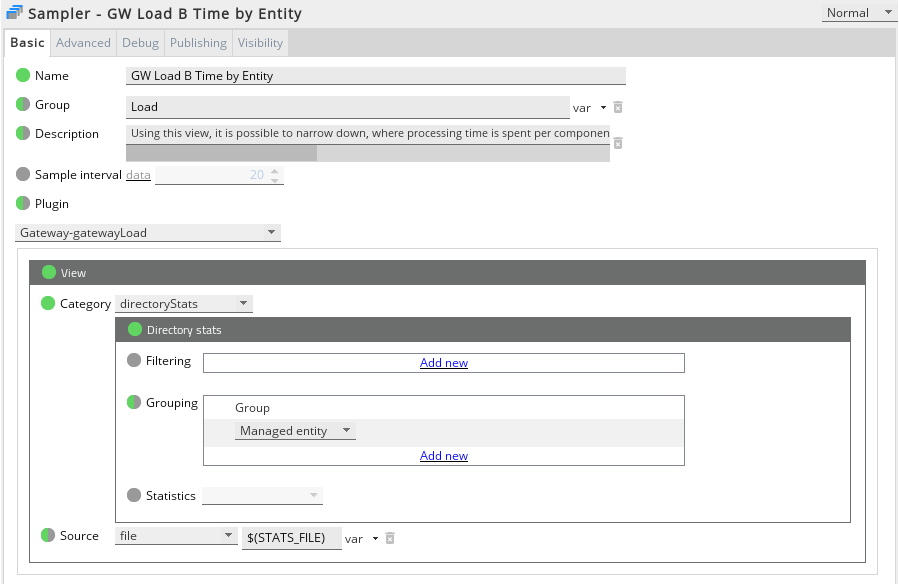
To configure a basic directory view to show statistics per managed entity, use the following sampler configuration in the GSE.
Note
If you are following along with this guide it is not necessary to configure a separate load‑monitoring sampler. You can simply update the existing “Time By Feature” sampler above with the new configuration.
This sampler produces output similar to that illustrated in the following screenshot, showing the breakdown of time spent processing by component for each managed entity.
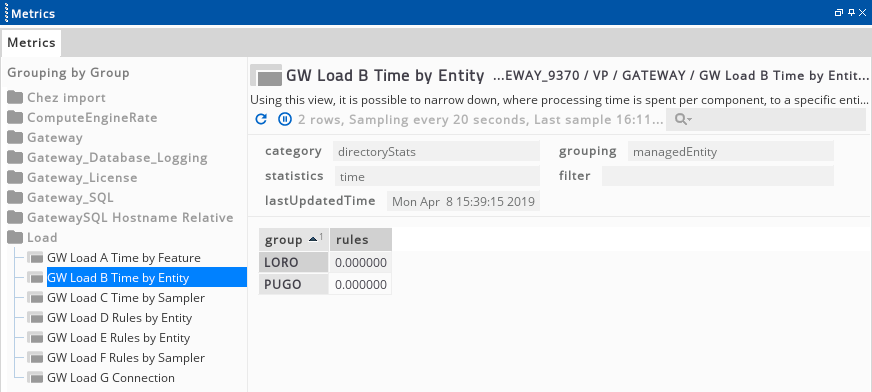
These statistics can then be sorted in the view as normal, so that the entities with the highest load can be found for each feature type.
Note
At the time of writing, directory-level statistics have only been implemented for the database and rules features.
Filtering and grouping output Copied
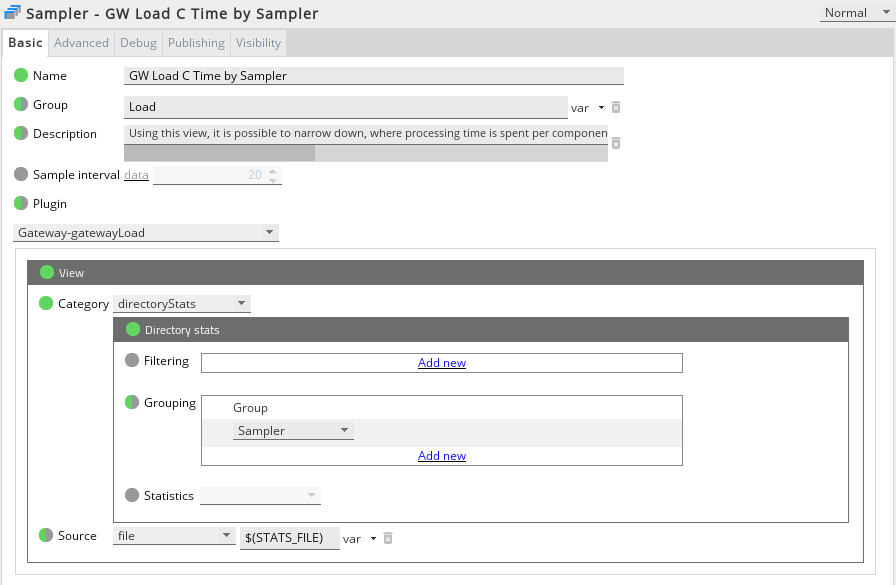
From the output above, we can see that the rts-mds-p? entities are using the highest amount of processing time for rules, and are also near the top usage for database logging. Using the filtering options, we can restrict the output to focus on one of these entities. Additionally, we can alter the plug-in configuration to show a second level of grouping underneath the entities, in this case the samplers on that entity.
The new configuration then becomes:
The output in Active Console now appears as below. From this output, we can see that the os\_cpu sampler is using most of the rules’ time for this entity. In addition, we can see that only three samplers are being used for database logging, and that again it is the os\_cpu sampler using most of the time.
Examination of the configuration for this sampler shows that it is configured to update every second, and since the CPU usage values change with almost every sample, rules are re-executed and the values are logged to a database.
Rule statistics Copied
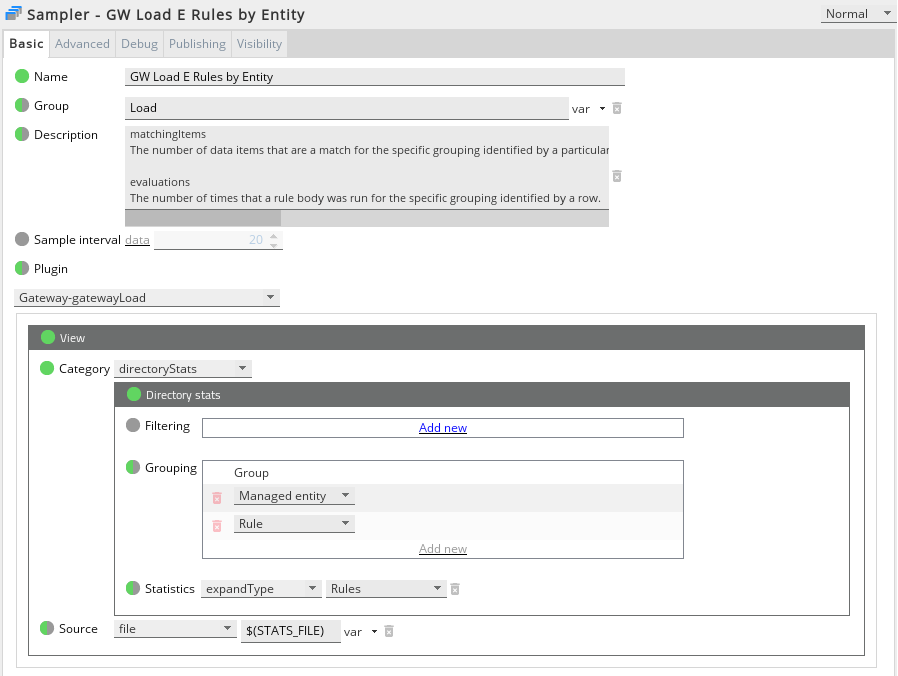
When looking purely at a rule’s statistical data, two further statistics can be displayed in addition to time:
- matchingItems
The number of data items that are a match for the specific grouping identified by a particular row. For example, if the grouping is a rule, this figure is the number of data items that matched the rule. If the grouping is entities, the figure is the number of data items matched for that entity.
- evaluations
The number of times that a rule body was run for the specific grouping identified by a row.
The directoryStats view of the load-monitoring plug-in can be configured to show all rule statistics rather than times across all components. To do this, select the expandType > Rules option for the Statistics setting as shown below.
When using rule statistics data, the rule grouping is also very useful. This grouping displays the rule name as configured in the setup file, along with any enclosing rule group names if these exist.
For example the name Infrastructure>Basic Processes>sshd count would be displayed for the following rule configuration.
Some example output from this sampler is shown below. From this output we can see, on a per-rule basis, the breakdown of the processing time spent in rules.
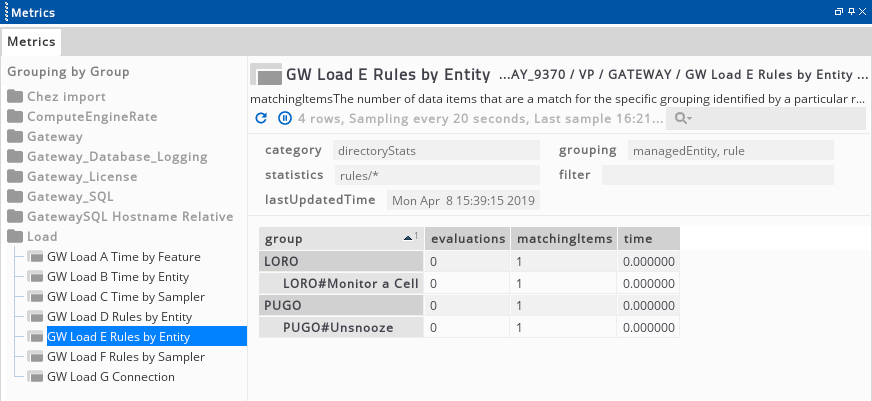
The busiest rule by both time and number of evaluations (203) in this screenshot is the rule RMDS> P2PS5>p2ps5 servicepending. This rule has the same number of matching items as two other rules (with 382 items) yet the time is much higher. This is likely due to the number of evaluations rather than what has been configured in this rule.
As this is a directoryStats view, filters and other groupings can be configured as required. In particular, it can be useful to add a sub-grouping for entities or samplers to show which entity is using a lot of time against which rule. This grouping can also be reversed if required so that you can see which rules are matched against which entity.
Database logging statistics Copied
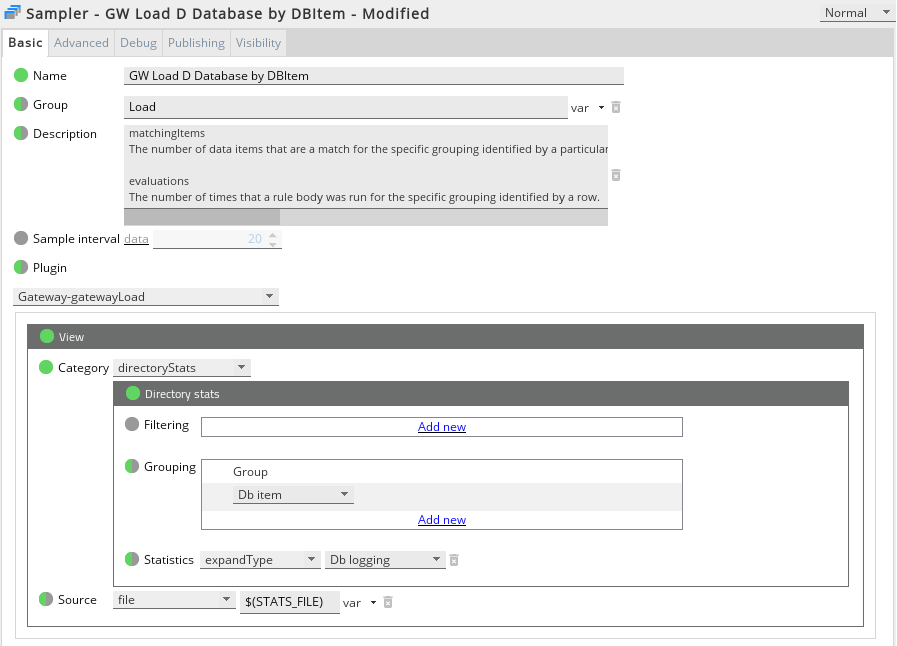
In a similar way to Rules above, Gateways also collects some statistics specific to database logging. In addition to the time field, two extra fields are available:
- matchingItems
The number of data items being logged to a database for the specific grouping identified by a particular row. For example, if the grouping is a DB Item, this figure shows the number of data items that matched the database item of that name (from the gateway setup file). If the grouping is entities, this figure shows the number of data items matched for that entity.
- updates
The number of times a matched data item changed value, which causes database logging to check the item again.
Note
This does not imply that the item is actually logged to database, since there may be other settings (such as a threshold value) which prevent this from happening.
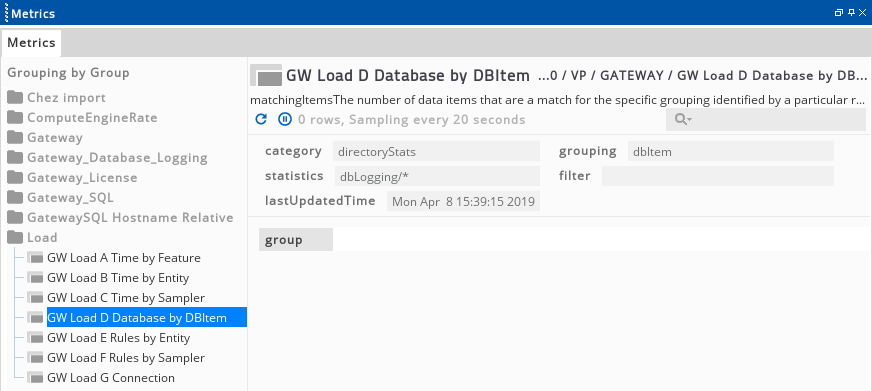
To configure the display of database statistical data, set the Statistics setting to the expandType > Database option as displayed below. Filters and/or groupings for this view can be configured as required. The DB Item grouping will display the database item names as configured in the gateway setup, similar to the Rule grouping for rules.
The output for this configuration is shown below. In this example we can see that the processing time roughly corresponds to the number of updates. os\_cpu has twice the number of updates as os\_network and about double the processing time. Similarly os\_network is twice as busy as the next logged item p2ps\_process, even though p2ps\_process has more matching items.
Tuning configuration Copied
Gateway background Copied
Many Gateway features respond to two different types of event for data received by the gateway. These events are the creation of a new data item and an update to a data item. These events behave in different ways when examining performance statistics and attempting to act upon them.
New data items Copied
When a new data item is created, each Gateway feature will determine whether this item matches any of its configured elements. If a match is found, the feature is said to be interested in this item. For example, the Rules feature will be interested in an item if any Rule Target path of its configured rules matches that item.
Items are created at high frequency when a NetProbe is started and begins publishing data from its samplers. The rate of item creation typically drops to low levels following the initial sampling, new items only being created when new rows are added to data views.
Updates to data items Copied
A data item update event occurs each time a property (such as the value or severity) of a data item changes. Features which are interested in the data item will then evaluate whether this change requires further action. For example, database logging might not log the new value if it has not changed more than the configured threshold.
Example scenarios Copied
The following section details some example scenarios of performance issues and what sort of statistics output these will exhibit.
Gateway busy on NetProbe start-up Copied
As mentioned above, an increase in Gateway load on start-up of a Netprobe is expected due to the amount of new data arriving from the NetProbe, and the path matching evaluations being made. Factors that will affect this are the number of data items being created (how large the data views are for that Netprobe), how many paths that need to be matched, and how complicated those paths are.
To diagnose this issue, gather statistics for the time period between the point when the NetProbe connects and the point when the Gateway load increases. This can then be examined (filtering for the specific probe where appropriate), to locate the features and feature-specific items utilising the time.
If the time usage seems high for a relatively small proportion of matched items, this can indicate that the majority of the work is performed during name matching. This load can be reduced by evaluating configured paths, and checking for complex paths which require more effort to evaluate. Such paths include those accessing dynamic attributes (such as the severity or value of an item) or paths which contain many wildcards.
Further diagnosis can be performed using the XPath statistics view, although it may be useful to seek assistance from ITRS support in these circumstances due to the relative complexity of paths.
Gateway busy due to spike in data rate Copied
A Gateway’s load may increase from a normal operating state to a high load, due to a spike in the data rate being sent from one or more NetProbes. This can happen, for example, when monitoring a log file with FKM which finds many events in a short time period.
Ordinarily this should not be a problem, but if the spike is for a prolonged period of time, it may negatively affect the gateway. There are several mechanisms in place to alleviate this effect, from throttling controls in the FKM plug-in itself through to rate control on the gateway, which will disconnect the NetProbe if it is preventing other monitoring from occurring. The gateway log will indicate when a connection is disconnected due to a high update rate.
If the update rate is high, but not enough to cause throttling or disconnection, examining the performance statistics should show an increased processing time for that NetProbe, and the entities or samplers on it.
Additionally, the gateway connection plug-in or the connection performance statistics view should show a corresponding increase in data for that probe, allowing the spike to be tracked down. If you are not sure that this data rate is a spike, enable database logging to establish a baseline data rate for each probe, and check historical values to see levels over time.
Gateway busy performing database logging Copied
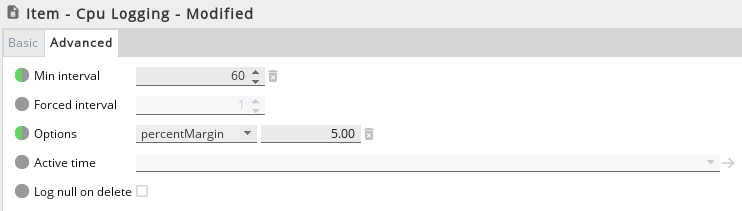
An increase in a Gateway’s load may be caused by logging values to a database. When investigating database logging performance, examine statistics grouping by database item. If an item with high processing time shows a high number of updates for a relatively low number of matching items, the increased load may be caused by the rate of values being logged.
This rate can be reduced simply by lowering the sample interval for the sampler in question. Alternatively, by throttling the rate at which values are logged, the database logging feature will have less work to perform. Two advanced settings can be configured to produce this effect, the Min Interval to control logging by time, or a Margin (either percentage-based or an absolute) to control logging by how much a value changes. See the screenshot below for an example showing these settings.
Gateway busy processing rules Copied
The most likely reason for a Gateway’s load is rule execution, since this is the primary purpose of a Gateway. When investigating performance issues, the best results can be obtained by optimising those rules which are used the most. Failing this, removing unused or fixing misconfigured rules can also prove to be of benefit. Finally, for gateways where rule load is an order of magnitude higher than other gateway features, enabling threaded rule evaluation will allow rules to run in parallel and improve throughput, although not reduce load.
The load that each configured rule adds to a system is dependent upon the configured target paths and the number of items matching this path, the rate of value updates to matching items, and the executable content of the rule body. In general, longer and more complex rules will require more processing time.
Viewing rule-specific performance statistics can give insight into which particular rules configured for a system are using more resources than the others. If the number of evaluations for this rule is high compared to the number of matched items, the high load could be related to update frequency. In this case, reducing the sampling interval for those data items may reduce the problem.
Conversely if the number of executions is low but the time used is high, then this might be due to the rule body content. Rearranging the content so that common conditions are placed earlier in the rule can help to speed up evaluation. The rule will stop processing at the point a transaction is reached.
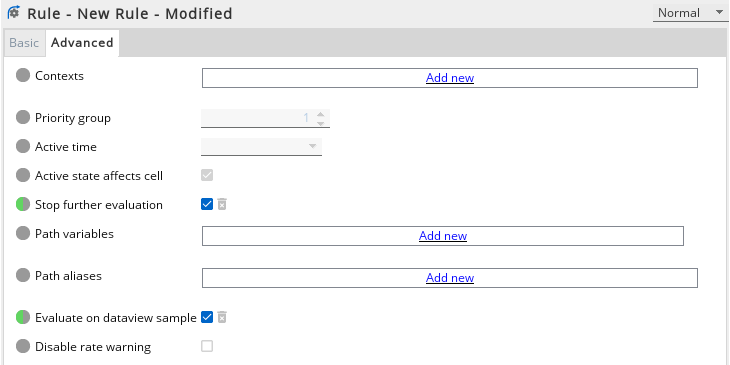
Compute engine rules that compute summary values (for example, the sum or average of a column of values in a dataview) should be configured with the Evaluate on dataview sample setting enabled. This setting defers evaluation of the rule until the end of a data view sample. If Evaluate on dataview sample is not set, the sum will be computed as the value on each row is updated, leading to N evaluations of the rule for a view of N rows each sample, rather than a single evaluation.
Finally depending upon the rule configuration structure, some data items may match several rules. The Gateway will evaluate all rules for this item, and apply any non-conflicting updates for the item. This behaviour is designed primarily to allow mixing of a high-priority data-specific rule with a low-priority generic “catch-all” rule. If you know that the generic catch-all will never apply, evaluation can be stopped early at this point by configuring the Stop further evaluation setting.
A screenshot showing these two settings is shown below:
Threaded rule evaluation Copied
From version 3.0, Gateways support the evaluation of rules using separate threads. This mode is intended to increase the throughput and scalability of the Gateway in situations where the Gateway load is primarily due to rule executions, perhaps because these rules are doing statistical calculations using the compute engine feature. You are advised to enable this mode only when required, that is, when the gateway CPU usage is approaching 100% of a single core on the Gateway server machine.
By default threaded rule evaluation is disabled. To determine whether you will see any benefits from enabling it, gather statistics for the gateway for a period of time and then examine the per-feature breakdown. Compare the time figures for rules against the total for all other features. If rules take greater than 50% of the processing time of the Gateway, enabling threads should see a benefit.
Rule threads are fed data from the main Gateway thread, which also has to service all other features. There are therefore decreasing gains to be made by increasing the number of rule threads. In addition, every additional thread incurs added synchronisation overhead, meaning that doubling the number of threads does not double throughput or maximum load.
In general, a good starting point for calculating the number of threads is to use the per-feature breakdown statistics to calculate a ratio between rule evaluation and the remainder of the gateway features. For example, a usage of 75% overall processing time for rules implies a 3:1 ratio, meaning that 3 rule threads should be an optimal starting point.
It is recommended that the number of threads used is no higher than the number of CPU cores available as this is the maximum number of rule threads that could be executing at the same time.
To enable threaded execution, configure the Number of Rule Evaluation Threads setting in the gateway Operating Environment section.
FAQ Copied
My gateway is slow/unresponsive, how can I find out what’s wrong? Copied
First we must gather statistics that can be looked at to find the problem. Right click on the Gateway in the Active Console and choose Load Monitoring Manager > Start Stats Collection > Now. Check in the Commands output viewer of the Active Console that the command has executed successfully.
If it has, wait a little while to collect statistics (10 minutes is a good bet to start with) then add the gatewayLoad plugin to a Managed Entity in your configuration. Follow the starting examples in the Reference Guide to drill down into specific components that may be causing the problem.
If you cannot run the command (ie the gateway is fully unresponsive) then you can amend the configuration to write out stats to a file. These stats can then be read using a separate gateway. Edit the gateway configuration file directly to add in the Write stats to file part of the Operating Environment. Restart the gateway to run with the -stats option, this will enable stats collection from the outset without having to call the command.
The gateway will then proceed to periodically write out stats to the file specified. You can then grab that file and load up another gateway with an instance of the gatewayLoad plugin and set the Source in the configuration to point to the file output from the other gateway. You can then look at the stats in the same way you would with the gatewayLoad plugin on the other gateway.
My gateway is slow/unresponsive at a specific time. How can I gather relevant stats? Copied
Statistics gathered in the gateway are cumulative from when the gateway was started or the Reset Stats command was called. As such, if a gateway becomes unresponsive at a particular time, it may be difficult to identify the cause as normal operation will skew the stats.
The solution is to gather statistics just for the time period during which the problem occurs. Let us assume for this example that the problem occurs at 9AM every day. We will therefore configure the gateway to gather statistics for a 10 minute interval around that point, so the statistics we see are only relevant to the time when the problem occurs.
Set up a Scheduled Command to run the Start Stats Collection for a Time Period command at 8:55AM. Set the time period for collection to 10 minutes. Set up a gatewayLoad plugin to view the stats. After 9:05AM the plugin will say “Stats Collection Disabled” and you will be looking at the statistics collected in that period.
You can then follow the instructions in the Reference Guide for identifying particular components causing a problem.
I’ve got the stats, how do I find out what is causing the problem? Copied
Start with the Component Statistics view in the gatewayLoad plugin (this is the default). Is there a particular part of the gateway standing out?
Note
Some parts are expected to do a lot of processing (Rule Manager, Setup Management etc).
If no component immediately stands out then check the Sampler Statistics view. Is there a particular Managed Entity that is standing out? If not, try grouping by Rule and seeing if there is a particular rule taking a lot of time or matching way more elements than expected.
Further information on how to track down problems in individual gateway components is available in the Reference Guide.
If I enable stats gathering, is it going to slow my gateway down? Copied
Attention was paid to the performance of statistics during development and there should not be a significant overhead of collecting stats. There may be some overhead if collection is enabled during gateway startup (with the -stats option) due to the large number of XPaths created and evaluated as all the netprobes connect.
The new gateway binary will have more threads for Rule Manager, low level communications etc. Assuming a component is serviced by multiple logical cpu cores, is there a way for the plugin to breakdown the time per core? Copied
Say the Rule Manager is using 60% of the time on a gateway. This is not an issue itself. If the gateway was using 100% of total CPU on the box or was unresponsive to the AC, then it may indicate a problem which you could then diagnose further by grouping by rule in the plugin. As it is, 60% seems a reasonable proportion of utilisation for the Rule Manager.
The same applies with the new threaded rules as well. The Rule Manager can now potentially spend more time running rules (in proportion to number of cores on the machine), so it will show up as using correspondingly more processing time. But on a gateway using 100% CPU, I’m not sure what extra information you would have for diagnosis of the problem by knowing how much time was spent on each core. I guess you’d still be looking for the rule or Managed Entity etc that is taking the most time relative to the others regardless.
Will the gateway statistics be running in a manner which allows it to always be available to collect stats, so in the worst case scenario where the gateway is using high CPU we will still be able to diagnose problems? Copied
The collection of statistics is designed so it will still occur even if the gateway is using excessively high CPU and is unresponsive. In this case however it may be difficult or impossible to view the statistics using the gatewayLoad plugin, as the Active Console may be disconnecting from the gateway. Additionally it may be difficult to modify the configuration of the plugin to look at particular statistics for the same reasons.
This is where the Write Stats To File section of the Operating Environment is very useful. When configured here the Gateway will periodically write stats out to an XML file. This file can then be read and viewed by a gatewayLoad plugin on another separate gateway, so statistics can be viewed from the unresponsive gateway.
In what situations should the Gateway Load plugin be enabled? Should it be turned on 24/7 or just on demand? Copied
The gateway load plugin merely views the statistics gathered by the gateway. The actual gathering of statistics is enabled and disabled via the commands on the right click menu of the gateway or the -stats option on the command line.
Statistics gathering is disabled by default. Whilst Development have made every effort to minimise the performance overhead involved in collecting stats there will naturally be some overhead. So we would advise that statistics collection should be enabled when performance issues are encountered ie for diagnosis purposes.
Collecting statistics all the time for capacity planning is certainly possible, however a small cpu (typically 1-2%) overhead will be incurred.
How can I make use of the data captured from statistics collection? What information should be provided to ITRS support if there are gateway performance issues encountered? Copied
As above, it is likely the statistics gathering will only be enabled when performance issues are encountered. We would anticipate that the plugin could be used on-site for preliminary investigation. If the problem needs to be investigated in the ITRS office we suggest asking the customer to set the gateway to write statistics to a file which can then be sent to support to be looked at. Support will be able to view the full range of statistics that could be seen live on the gateway using this method. Go to GSE > Operating environment > Advanced, and enable Num rule evaluation threads.